[X] Exceptions
-
modernes Exception Handling
In dem Artikel Exception-Handling haben Sie bereits erfahren dass auch der beste Programmierer an Fehler denken muss. Sie haben Exceptions kennengelernt und gesehen wie flexibel diese Ihnen die Arbeit erleichtern können. Doch Exceptions sind nicht nur ein Segen, sondern auch ein Fluch. Bevor wir jedoch die Nachteile von Exception näher betrachten, wollen wir uns die Vorteile ansehen - oder besser: die Alternativen.
Die Alternativen
Exceptions sind nicht das einzige Mittel um Fehlerbehandlung zu implementieren. Betrachten wir also kurz welche alternativen Möglichkeiten wir denn noch haben.
If Then Else
Die wohl bekannteste Variante der Fehlerbehandlung ist das gute alte if-then-else.
#include <stdio.h> #include <stdlib.h> #include <ctype.h> #include <string.h> void error(char const* msg) { fprintf(stderr, "Ein Fehler ist aufgetreten: '%s'\nDas Programm wird beendet\n", msg); } int print_usage() { if(puts("encode <src> <trg>")<0) { return -1; } else { return 0; } } int encode(char const* srcFileName, char const* trgFileName, char const* password) { FILE* src = NULL; FILE* trg = NULL; size_t pwdPos; size_t pwdLength; int c; int bytesWritten; int returnCode; if(srcFileName == NULL || trgFileName == NULL || password == NULL) { return -1; } src = fopen(srcFileName, "r"); if(src==NULL) { returnCode=-1; goto cleanup; } trg = fopen(trgFileName, "w"); if(trg==NULL) { returnCode=-2; goto cleanup; } pwdPos=0; bytesWritten=0; pwdLength=strlen(password); while( (c=fgetc(src)) != EOF) { int encoded = c ^ password[pwdPos++%pwdLength]; if(fputc(encoded, trg) == EOF) { returnCode=-4; goto cleanup; } ++bytesWritten; } if(!feof(src)) { returnCode=-3; } else if(pwdPos<pwdLength) { returnCode=-5; } else { returnCode=bytesWritten; } cleanup: if(src!=NULL) fclose(src); if(trg!=NULL) fclose(trg); return returnCode; } int main(int argc, char* argv[]) { char password[256]; int res; if(printf("Passwort: ")==-1) { error("Schreibfehler auf stdout"); return -5; } if(!fgets(password, 256, stdin)) { error("Lesefehler von stdin"); return -5; } if(argc!=3) { if(!print_usage()) { return 0; } else { error("Unbekannter Fehler"); return -6; } } res=encode(argv[1], argv[2], password); if(res>0) { return 0; } else { switch(res) { case 0: error("Datei leer"); return -2; case -1: error("Source Datei nicht lesbar"); return -3; case -2: error("Target Datei nicht schreibbar"); return -3; case -3: error("Lesefehler in Source Datei"); return -4; case -4: error("Schreibfehler in Target Datei"); return -4; case -5: /*kein fehler*/ return 0; default: error("Unbekannter Fehler"); return -6; } } }Es gibt 3 Probleme mit diesem Code.
- Die Fehlerbehandlung erfolgt lokal und macht dadurch den Code schwerer lesbar.
- Jede Funktion verlangt andere Behandlung von Fehlern.
- In Sprachen ohne Garbage Collector muss man seinen eigenen Mist selber wegräumen. Dieser Cleanup Code ist kompliziert einzubauen. Hier zB über häßliche gotos gelöst. Alternativ auch mit tief verschachtelten ifs lösbar.
Aber in C macht man es anders
Ihnen als aufmerksamer Leser ist natürlich aufgefallen, dass
encode()hier ein Designproblem hat: Der return Wert beißt sich mit der Fehlerbehandlung. Der Programmierer war versuchtencode()leicht benutzbar zu machen und der Konvention zu folgen die geschriebenen Bytes zu returnen. Wenn Sie Erfahrung mit C APIs haben, werden Sie wissen dass der richtige Weg gewesen wärebytesWrittenals Zeiger der Funktion zu geben. Worauf das aber hinausläuft ist, dass man den Returnwert nur noch als Fehlercode verwenden kann - was vielen Code unpraktisch macht.Deshalb geht man in C den Weg über
errnooder genereller gesagt: eine globale Variable. Der Vorteil ist, dass wir nur einen ungültigen Returnwert definieren müssen, beiencodezB -1 und über [/c]errno[/c] könnten wir dann den genauen Fehler abfragen. So ganz löst das unser Problem aber nicht: denn der Fall dass nach x geschriebenen Bytes ein Fehler auftritt hindert uns daranbytesWrittenals return Wert zu verwenden. Wir haben also durcherrnonicht viel gewonnen. Weiters wirft dererrnoAnsatz ein Problem mit der Erweiterbarkeit auf. Welche Werte verwendet eine neue Funktion für Fehler? Bestehende Werte sollte man lieber nicht doppelt benutzen sonst kommen automatisierte Auswertungstools wie zBstrerror()nicht mehr mit. Unter Windows wird das ganze miterrno,GetLastError(),WSAGetLastError(),... auch noch sehr unübersichtlich.Der PHP4 Ansatz
In PHP4 hat man das Problem 2 sehr schön lösen können und da PHP einen Garbage Collector hat fällt auch Problem 3 weg:
function some_function() { if(something_went_wrong()) { return PEAR::raiseError('something went wrong', MY_ERROR_CODE); } return some_value(); } $var = some_function(); if(PEAR::isError($var)) { do_something(); } else { echo $var; }PHP macht sich zu Nutzen dass jede Variable jeden Typ haben kann. isError erkennt ob
$varvom TypPEAR_Error(oder einer Subklasse davon) ist und liefert dementsprechend true oder false. Dadurch hat man verhindert dass jede Funktion einen anderen Fehlerwert liefert und mit leicht behandelbare Fehlerobjekte lassen sich auch Unterschiedliche Fehler leichter unterschiedlich behandeln.Doch auch das war nicht der Weisheit letzter Schluss. Da wir immer noch die Fehler lokal behandeln müssen und dies bedeutet wir müssen dort wo der Fehler auftritt wissen wie wir darauf reagieren wollen. Wenn wir uns aber als Beispiel eine Anwendung mit Datenbank Anbindung vorstellen und mitten in einem Query wird die Verbindung getrennt, dann brauchen wir eine zentrale Stelle im Code um darauf zu reagieren. Wir wollen nicht an 100.000 verschiedenen Stellen im Code Fehlerbehandlung für eine getrennte Verbindung einbauen, sondern an einer Stelle zentral. Es gibt ja verschiedene Strategien was man in so einem Fall machen kann. Mit der if-then-else Methode muessen wir aber jeden Fehler händisch nach unten geben, bis wir irgendwann an einer Stelle sind wo wir reagieren können.
Was Exceptions bieten
Und einen Punkt wollen wir nicht vergessen, Programmierer sind faul. Fehler die "nie" auftreten muss man nicht behandeln. Wieviel C Code haben sie schon gesehen wo der Erfolg von
printf()überprueft wurde? Das Problem mit Fehlern die nie auftreten können ist der, dass wenn sie es doch tun, die Hölle los ist.Exceptions bieten hier nun 3 essentielle Punkte an:
- Fehler können dort behandelt werden wo es Sinn macht und müssen nicht (können aber) lokal behandelt werden.
- Fehler kann man nur noch explizit ignorieren.
- Fehlerbehandlung wird vereinheitlicht.
Wie Exceptions generell funktionieren und was try/catch Blöcke sind, haben Sie ja schon in Exception-Handling gelesen. Doch Sie, als aufmerksamer Leser haben natürlich sofort erkannt dass ich ihnen ein Problem unterschlagen habe: wie verhält es sich mit dem Cleanup Code?
Der finally Block
Viele moderne Sprachen wie zB Java oder C# bieten hier das berüchtigte finally an um dem Problem Herr zu werden:
public void OutputFile(string name) { FileStream fs = null; StreamReader sr = null; try { fs = new FileStream(name, FileMode.Open); sr = new StreamReader(fs); string line; while( (line=sr.ReadLine())!=null ) { Console.WriteLine(line); } } finally { if(sr!=null) sr.Close(); if(fs!=null) fs.Close(); } }Der Vorteil des finally über der if-then-else Methode ist offensichtlich: wir können den Cleanup Code an einer zentralen Stelle lagern und unabhängig wie die Funktion beendet wird, der Code wird ausgeführt. So ganz ideal ist es aber nicht - denn die Variablen müssen im finally Block ja bekannt sein und sie müssen einen Status "uninitialisiert" annehmen können - denn wir wissen ja nicht ob das Objekt schon initialisiert wurde. Der finally Weg ist für Sprachen wie C#/Java durchaus gangbar, denn jedes Objekt ist lediglich eine Referenz und diese Referenz kann auf null Zeigen. In C++ haben wir diesen Luxus nicht und wenn wir dem schlechten Beispiel der Standard Library und den Stream Klassen nicht folgen wollen, dann sind unsere Objekte immer in einem initialisierten Zustand. finally fällt für C++ also weg. Aber C++ bietet und ja RAII.
RAII
Ein grundlegendes Problem in C++ ist, dass wir unsere Ressourcen selber freigeben müssen. Meistens, wie zB im Falle
fstream, haben wir Ressourcen bereits in praktische, kleine Klassen gepackt und der Destruktor räumt für uns automatisch auf. Für alle Situationen wo wir diese schöne Kapselung nicht haben, gibt es ScopeGuard. Mit C++0x wird das ganze dank Closures noch einfacher, aber das ist Thema eines anderen Artikels.Genaugenommen ist RAII auch nicht Thema dieses Artikels, aber das RAII-Konzept zeigt sehr schön wie Exception in C++ verwendet werden. Exception Sicherheit basiert auf dem RAII bzw. RRID (Ressource Release Is Destruction) Idiom. Bevor wir deshalb weiter in Exceptions eintauchen, wiederholen wir kurz was RAII/RRID eigentlich ist.
Exceptions in C++ garantieren uns etwas wichtiges: das zerstören aller Objekte die Out Of Scope gehen. Das bedeutet, dass alle notwendigen Destruktoren aufgerufen werden. Die Idee ist nun, den Destruktor die Aufräumarbeit machen zu lassen, da es ihm egal ist warum er aufgerufen wurde. Damit ist man nicht mehr von einem Single-Entry-Single-Exit wie man es aus C her kennt abhängig und kann durchaus auch früher die Funktion beenden, da alle Ressourcen die bis dahin initialisiert wurden durch den Destruktor wieder freigegeben werden.
Natürlich gibt es auch umfangreichere Einführungen in RAII.
Während Java RAII nicht unterstützt bietet C# eine explizite RAII Schreibweise mit Hilfe des using Schlüsselwortes an:
using( File f=new File(filename) ) { //... } //hier wird automatisch f.Dispose() aufgerufenScopeGuard
ScopeGuard ermöglicht es uns das RRID Idiom einzusetzen um Cleanup Code automatisch ausführen zu lassen. Die einfachste Einsatzweise für ScopeGuard ist
ON_BLOCK_EXIT:void writeFile(char const* name, char const* text) { FILE* f=fopen(name, "w"); ON_BLOCK_EXIT(fclose, f); //mit Ende des Blocks wird fclose(f) aufgerufen fprintf(f, "Text: %s\n", text); } void lockedWrite(char const* text) { Mutex m; m.lock(); ON_BLOCK_EXIT(&Mutex::unlock, m); //mit Ende des Blocks wird m.unlock() aufgerufen cout<<text<<endl; }ON_BLOCK_EXITist sehr praktisch wenn man Cleanup Code hat der in keinem Destruktor steht. Natürlich wäre es besser direkt RAII Objekte zu verwenden, aber manchmal ist das unpraktisch und eine Zeile ScopeGuard ist effizienter. Gerade bei dem Mutex Beispiel wäre aber eine vernünftige Mutex Klasse eine bessere Wahl als überall ScopeGuards einzubauen.Ein weiteres wichtiges Feature von ScopeGuard ist das Ermöglichen von Transaktionen:
void clone(LinkedList* src, LinkedList** trg) { LinkedList* temp = create(); ScopeGuard guard = MakeGuard(destroy, temp); do_clone(src, &temp); destroy(*trg); *trg=temp; guard.Dismiss(); }Dismiss()verhindert dass der Cleanup Code ausgeführt wird. Indem wirDismissals letzte Aktion in der Funktion ausführen garantieren wir, dass wenn die Funktion frühzeitig beendet wurde sauber aufgeräumt wird - wenn die Funktion aber bis zum Ende durchläuft nichts zerstört wird.Exception Garantien
In C++ gibt es 3 Arten von Exception Garantien.
- Basic - grundlegende Garantie
- Strong - starke Garantie
- nothrow - keine Exception fliegt Garantie
Nothrow
Der einfachste Fall ist definitiv die nothrow Garantie. Egal was passiert, die Funktion wirft keine Exception und leitet auch keine durch. Die Funktion garantiert also immer erfolgreich zu sein. Ein einfaches Beispiel ist hier zB die Funktion
std::swap(). Idealerweise sollten natürlich alle Funktionen diese Garantie erfüllen, praktisch ist das aber nicht möglich - oder wie wollen Sie garantieren dass jede Netzwerkoperation erfolgreich endet? Funktionen mit der nothrow Garantie sind aber ein essentieller Baustein in Exception sicheren Code - wie und warum, das erfahren Sie gleich.Basic Garantie
Die basic Garantie verlangt dass die Funktion die Daten in konsistenten Zustand hinterlässt (dass dies nicht immer ganz einfach ist werden Sie etwas später erfahren). Was diese Definition uns verschweigt ist, dass ein konsistenter Zustand nicht unbedingt immer der gewünschte Zustand ist. Nehmen wir als Beispiel die Funktion
std::copy(). Es ist klar, dass copy nicht garantieren kann dass jede Kopieroperation erfolgreich sein wird. Was passiert nun, wenn die xte Kopieroperation fehlschlägt? Die Sequenz auf den der out Iterator zeigt enthält x-1 neue Objekte und N-(x-1) alte Objekte. Wichtig dabei ist aber, dass alle Objekte in einem konsistenten Zustand sind.Strong Garantie
Die strong Garantie ist dagegen die Garantie dass ein Rollback stattfindet wenn etwas schief geht. Als Beispiel sehen wir uns std::uninitialized_copy an. Diese Funktion kopiert Daten in uninitialisierten Speicher, sollte ein Kopiervorgang fehlschlagen werden die alten Daten per Destruktor zerstört. Hier kommt die nothrow Garantie dazu - denn jeder Destruktor muss die nothrow Garantie erfüllen (dass dies oft mit Problemen für die Implementierung des Destruktors verbunden ist, sehen wir später). Eben durch diese nothrow Garantie kann
uninitialized_copy()garantieren dass der Rollback erfolgreich ist und somit kann die Funktion die starke Garantie gewährleisten.Einen etwas tieferen Einblick in Exception Garantien bietet Ihnen unter Anderem Bjarne Stroustrup.
Welche Garantie verwenden?
Wie so oft in C++ gibt es auch hier eine einfache Regel um zu bestimmen welche Exception Garantie eine Funktion abgeben soll: die stärkste die moeglich ist. Sollte es möglich sein die nothrow Garantie einhalten zu können - so tun Sie es. nothrow ist das wertvollste was wir aus Exception-Sicherheitstechnischen-Standpunkt her kennen. Aber bedenken Sie auch, die Funktion soll erst ihre Aufgabe erledigen - dann erst die stärkste Garantie abgeben.
std::copy()zum Beispiel wäre mit der starken Garantie implementierbar:template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator target) { typedef target_container vector< typename std::iterator_traits< OutputIterator >::value_type > ; target_container temp(first, last); target_container::iterator i=temp.begin(); target_container::iterator e=temp.end(); while(i!=e) { swap(*i, *target); ++i; ++target; } return target; }Wie Sie aber sehen ist das nicht die effizienteste Art ein copy zu implementieren. Denn wir erstellen N Kopien und swapen diese dann erst an die Zielposition und müssen nachher die Kopien auch wieder zerstören. Deshalb gilt die Regel "eine Funktion soll die stärkste Garantie unterstützen die sie kann, ohne relevante Mehrkosten zu produzieren". Als kleiner Tip sei deshalb gesagt: die meisten Operationen lassen sich per Copy&Swap von der basic auf die strong Garantie upgraden (übrigens nur weil swap und Destruktoren uns ein nothrow garantieren). Wir können so auch aus fast jeder Funktion die die basic Garantie abgibt eine Funktion die die strong Garantie einhält machen:
template<typename Container> void strong_sort(Container& c) { Container temp(c); temp.sort(); swap(c, temp); }Java/C# und Co
Diese 3 Garantien kann man auch auf Java/C# übertragen. Allerdings sind Operationen wie swap() und Destruktoraufrufe (bzw. eigentlich ja finalizer Aufrufe) in diesen Sprachen sowieso automatisch nothrow. Da nur mit Referenzen hantiert wird, ist swap einfach per Zuweisung implementierbar und da nur Referenzen kopiert werden, kann auch keine Exception fliegen. Man muss in Java/C# deshalb nicht so genau schauen wie in C++, aber die 3 Exception Garantien gelten in Java/C# genauso wie in C++.
Die Implentierung der 3 Garantien
Sie wissen nun warum Exception Sinn machen und welche Garantien eine Funktion in Bezug auf Exception Sicherheit vergeben kann. Sehen wir uns nun aber einmal an wie wir diese Garantien auch durchsetzen können:
Betrachten wir folgende Beispiele:
template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { while(first!=last) { *result=*first; //wenn diese Zuweisung fehlschlägt, wird *result nicht geändert ++first; ++result; } return result; }copyunterstützt die basic Garantie, solange der Zuweisungsoperator des verwendeten Typen diese Garantie ebenfalls unterstützt. Wenn wir dem Zuweisungsoperator nicht trauen können, dann können wir auch keinen Exception Sicheren Code schreiben. Jede Funktion muss deshalb die basic Garantie erfüllen.template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ForwardIterator marker = first; try { while(first!=last) { new (&*first) T(obj); //wenn der Konstruktor fehlschlägt, wird *first nicht geändert ++first; } } catch(...) { //Rollback while(marker!=first) { marker->~T(); //Elemente wieder zerstören ++marker; } throw; //rethrow da wird den Fehler nicht behandeln können } }unitialized_fillunterstützt die strong Garantie und wir brauchen deshalb Rollback Code um im Falle eines Fehlers den Ursprungszustand wiederherstellen zu können. Dank ScopeGuard kann man das aber auch eleganter lösen:template<typename T, typename Function> struct DelayedRangeExecute { private: T startValue; T const* endValue; Function func; public: DelayedRangeExecute(T const& value, Function func) : startValue(value), endValue(&value), func(func) { } void operator()() { while(startValue!=*endValue) { func(*startValue); ++startValue; } } }; template<typename T, typename Function> DelayedRangeExecute<T, Function> makeDelayedRangeExecute(T const& value, Function func) { return DelayedRangeExecute<T, Function>(value, func); } template<typename T> void destroy(T& obj) { obj.~T(); } template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ScopeGuard guard = MakeGuard(makeDelayedRangeExecute(first, destroy)); while(first!=last) { new (&*first) T(obj); ++first; } guard.Dismiss(); }Auf den ersten Blick wirkt der Aufwand für DelayedRangeExecute sehr hoch - aber wenn man bedenkt dass wir
DelayedRangeExecutejetzt überall verwenden können wo wir ein Rollback über eine unbestimmte Iterator Range machen müssen, wirkt es nicht mehr so viel.Ein Beispiel für eine Funktion die die nothrow Garantie unterstützt ersparen wir uns. Denn nothrow Funktionen dürfen nur andere nothrow Funktionen verwenden oder sie müssten Fehler explizit ignorieren.
Arten von Fehlern
In dem Artikel Exception-Handling haben Sie bereits unterschiedliche Fehlerarten kennengelernt. Eine weitere Einteilung ist in Interne Fehler und in Externe Fehler. Externe Fehler sind Fehler die einfach passieren auch wenn Ihr Programm ganz korrekt geschrieben ist. Es kann eine Netzwerkverbindung abbrechen, der Speicherplatz ausgehen, der User nicht die notwendigen Rechte besitzen, etc. Diese Fehler passieren. Man kann sich nicht gegen sie schützen, man kann nur richtig reagieren. Aber es gibt auch noch Interne Fehler wie zB
strlen(NULL). Solche Fehler sollten nicht passieren und sollten in der Release Version alle behoben sein. Interne Fehler sind immer fatale Fehler, da man auf sie nicht richtig reagieren kann. Egal wasstrlen()macht wenn man ihm einen NULL Zeiger gibt, es ist ein falsches Resultat. Man kann natürlich argumentieren dass ein NULL Zeiger die laenge 0 hat - aber wie sieht das ganze mitfopen(NULL)aus? fopen kann nun ebenfalls NULL liefern und sagen die Datei konnte nicht geoeffnet werden, aber warum? Was sagen wir dem User warum wir seine Lieblingsdatei nicht öffnen konnten? Irgendetwas ist schief gelaufen, nie hätte der NULL Zeiger an fopen übergeben werden dürfen.Assert
Um solche Internen von Externen Fehlern getrennt bearbeiten zu können hat C bzw. C++ uns die Möglichkeiten eines
assert()gegeben. assert ist ein Makro dass in der Release Version nichts macht, in der Debug Version aber (je nach Compiler) direkt den Debugger startet und uns zeigt: hier haben wir irgendwo einen Logikfehler versteckt. Das ideale Beispiel für assert ist deroperator[]einer Array Klasse. Zugriffe ausserhalb des Array Bereichs sind Logikfehler die nicht auftreten dürfen - sollte es uns dennoch einmal passieren über den Index hinaus zuzugreifen, springt gleich der Debugger an und zeigt uns wo wir einen Fehler gemacht haben. Ganz wichtig aber ist es, Externe Fehler nie nie nie nie mit assert zu prüfen, da assert in der Release Version in der Regel abgeschaltet ist.C# und Java bieten auch Asserts an, aber diese Technik ist in diesen beiden Sprachen nicht weit verbreitet. Meistens werden Interne Fehler in mit Exceptions geahndet, was den (je nachdem von welcher Warte man es sieht) Vorteil oder Nachteil hat, dass Interne Fehler ignoriert werden können. Der Vorteil von asserts ist aber, dass man sie überall hinpacken kann da sie in der Release Version keine Performance kosten. Für viele kleine Tests mag das keinen Unterschied machen, aber asserts sind ideal um Invarianten bzw. Pre/Post Conditions zu testen (was durchaus auch einmal länger dauern kann (Beispielsweise muss ein sortierter Container nach jeder Einfügeoperation immernoch sortiert sein, dies durchzutesten kann aber dauern))
Design by Contract
Jeder Funktionsaufruf ist genaugenommen nichts anderes als ein Vertragsabschluss zwischen der aufrufenden (caller) und der aufgerufenen (callee) Funktion. Der Caller erfüllt eine handvoll Vorbedingungen (Preconditions) wie zB der string ist 0-terminiert und den Pfad zu einer Datei zu zeigen. Der Callee dagegen garantiert dass eine bestimmte Situation eingetreten bzw. nicht eingetreten ist wenn die Funktion abgeschlossen ist - so zB garantiert fopen die Datei geöffnet zu haben und den Zugriff auf die Datei zu ermöglichen.
Die Theorie besagt, wenn sich alle Caller und Callees an den Vertrag halten, dann ist das Programm Fehlerfrei. Ganz so simpel ist es zwar nicht, aber Design by Contract ermöglicht uns dennoch 2 Fehlerquellen (bis zu einem gewissen Grad) auszuschliessen:
- Logikfehler beim Funktionsaufruf
- Fehler in der Logik der Funktion selbst
Sehen wir uns deshalb einmal etwas Pseudocode an (Vorlage dazu ist std::copy):
template <class InputIterator, class OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { precondition { first<=last && //valid range (result<first || last>result) //result not within [first,last) range //theoretisch fehlt hier die Überprüfung ob result genug Speicher hat //um die ganzen Elemente auch aufzunehmen } while(first!=last) { *result = *first; ++result; ++first; } return result; postcondition { equal(first, last, result) &&//Zugriff auf die originalen Werte return == result + (last-first) } }Wir können durch so einen Code garantieren dass sich Caller und Callee an den Vertrag gehalten haben - dass dabei nicht alle Fehler abgefangen werden ist klar (
[first,last)könnte auf zuviele oder zuwenig Items zeigen, es könnte nur eine flache statt einer tiefen Kopie der Elemente erzeugt werden oder es könnten Ressourcen Leaks entstehen) aber viele Fehler können so gefunden werden.Invarianten
Ein wichtiger Bestandteil von Design by Contract sind sogenannte Invarianten. Invariant wird die Garantie genannt, dass eine Klasse in einem konsisten Zustand ist.
std::mapzB ist ein sortierter, balanzierter Baum.std::mapmuss zu jedem Zeitpunkt sortiert und balanziert sein - dass ist also die Invariante. Invarianten werden immer aufgerufen nachdem eine öffentliche (public oder protected) Memberfunktion beendet wird. dh, nach jeder Operation wird noch einmal überprüft ob die map wirklich sortiert und balanziert ist. Die Theorie besagt: solange das Objekt in einem konsistenen Zustand ist, kann es zu keinem Fehler kommen. Auch hier ist die Theorie nicht 100% korrekt, aber Invarianten helfen uns logikfehler in Klassen zu finden.Praxis
Ein wichtiger Punkt von DbC ist aber, dass wir diese Tests nur dann durchführen müssen, wenn wir unser Programm testen. In der Release Version müssen diese Tests nicht mehr enthalten sein - dies ermöglicht es uns Tests zu verwenden die sehr viel Zeit in Anspruch nehmen (zB eine map auf sortiertheit und balanziertheit zu testen). Da es sich aber nur um Logik-Fehler handelt die wir abfangen wollen, hat zB ein Vergleich ob eine Datei nun geöffnet werden konnte oder nicht, in den Postconditions wenig verloren.
Warum werden Invarianten nur in public und protected Funktionen aufgerufen? Das liegt daran, dass private Funktionen durchaus den Status des Objektes zerstören dürfen - sofern eine andere Funktion sie wieder herstellt. Als Beispiel nehmen wir wieder unsere Map:
class Map { //... public: void insert(map const& other) { do_insert(other); do_balance(); } }Erst fügen wir alle Elemente sortiert ein und danach balanzieren wir den Baum. do_insert zerstört den konsistenten Zustand des Objektes - aber da wir immer nach einem do_insert ein do_balance aufrufen, ist das kein Problem. Bedingung ist natürlich dass
do_insertunddo_balancenicht von aussen zugänglich sind - denn sonst können wir den konsistenten Zustand nicht mehr garantieren, da wir Niemanden davon abhalten könnendo_insertohnedo_balanceaufzurufen.Die wenigsten Sprachen unterstützen Design by Contract direkt - aber unabhängig ob man im Code direkt per DbC die Validierung einbauen kann oder nicht, es ist meistens sinnvoll die Pre- und Postconditions zu notieren. Mit assert kann man dann zumindest die meisten Preconditions forcieren - um gute Postcondition-Checks schreiben zu können, braucht man aber in der Regel Unterstützung der Sprache (da man ja auf die originalen Werte zugreifen können muss nachdem die Funktion beendet wurde).
Design by Contract Libraries gibt für viele Sprachen, darunter natürlich auch für C++, C# und Java.
Betrand Meyer bietet in einem Interview für Artima einen tieferen Einblick in DbC.
Execption Spezifikationen
Neben den Exception Garantien gibt es auch Exception Spezifikationen. Eine Exception Spezifikation sagt aus, welche Exceptiontypen eine Funktion werfen darf. Im Prinzip nicht viel anders als eine Liste mit erlaubten Error Codes - mit einem kleinen Unterschied: Die Funktion definiert Klassen die sie werfen darf, aber sie darf natürlich auch Subklassen davon werfen. Das ist gegenüber den Returncodes ein erheblicher Vorteil.
Ein weiterer Vorteil von Exception Spezifikationen ist, dass sie Tools ermöglichen die statisch untersuchen können ob alle möglichen geworfenen Exceptions auch gefangen werden. Java geht hier einen Schritt weiter und definiert 2 Arten von Exceptions: Checked und Unchecked Exceptions.
Checked/Unchecked Exceptions
Checked Exceptions sind Externe Fehler wie zB die Datei konnte nicht geöffnet werden weil wir die Rechte nicht haben oder die Netzwerkverbindung wurde unterbrochen. Unchecked Exceptions sind dagegen die Fälle bei denen wir in C++ ein assert nehmen würden, nämlich Vertragsverletzungen.
Java verlangt, dass man alle Checked Exceptions abfängt oder explizit weiter wirft. Das bedeutet nun in der Theorie, dass in einem Java Programm kein unerwarteter Externer Fehler auftreten kann, praktisch sieht es aber anders aus. Die Idee der Checked Exceptions ist nicht schlecht - da man damit versucht eben die beiden Arten von Fehlern zu trennen, die wir kennengelernt haben. Aber es gibt an der Umsetzung bzw. am Resultat der Umsetzung durchaus einige Kirtikpunkte:
- Versioning der Funktionen wird schwerer. In den meisten Faellen sind die einzelnen Exceptiontypen nicht so relevant, da man meistens ein catch-all macht, aber Checked Exceptions verbieten es Funktionen nachträglich einen neuen Fehler produzieren zu dürfen.
- Es ist nicht immer leicht für die Programmierer zu entscheiden was jetzt eine Checked Exception sein soll und was nicht. Nehmen wir als Beispiel eine Datenbank Anwendung. Der Abbruch der Verbindung zum Server während eines Queries ist definitiv eine Checked Exception. Doch was wenn wir die Datenbank lokal direkt in die Anwendung integrieren und keine Verbindung zu einem externen Server haben sondern nur ein WriteLock auf eine lokale Datei erstellen? Dann kann die Verbindung nicht mehr abbrechen, wir muessen aber dennoch auf diese Situation die nie eintreten kann reagieren.
- Checked Exceptions verleiten die Programmierer dazu
catch(Exception e){}zu schreiben.
Das bedeutet nicht, dass Checked Exceptions schlecht sind - sie lösen einige Probleme und bringen dafür ein paar andere Probleme ins Spiel. Sehr schön auch in Unchecked Exception - The Controversy oder Does Java need Checked Exceptions dagelegt. Nichtsdestotrotz sind sie ein essentielles Designmittel in Java um den Programmierer auf Fehler hinzuweisen. C++ und C# sowie die meisten Sprachen trennen Exception Typen aber nicht.
Die Implementierung der Exception Spezifikationen in C++, C# und Java sind recht unterschiedlich.
Implementierungen
In Java sind Exception Spezifikationen immer notwendig. Jede Methode muss genau definieren welche Checked Exceptions sie werfen darf. Die Spezifikation von Unchecked Exceptions ist dagegen optional. Wenn eine Methode eine Checked Exception werfen will, die sie laut der Spezifikation nicht werfen darf gibt es einen Compiler Fehler.
In C++ sind alle Exception Spezifikationen optional und da der Check welche Exception geworfen wird und welche geworfen werden dürfen erst zur Laufzeit stattfindet, ist er ziemlich unnütz. Wenn eine unerlaubte Exception geworfen wird, wird die Funktion
std::unexpected()aufgerufen welche im Normalfall eine Exception vom Typstd::bad_exceptionwirft. Da aber, wie gesagt, diese Tests alle zur Laufzeit stattfinden macht es keinen Sinn in C++ Exception Spezifikationen zu verwenden. Es kann vorallem auch gefährlich werden, da eben keine statischen Tests stattfinden, dass falsche Exception Spezifikationen Fehler einführen. Und Fehler die erst zur Laufzeit gefunden werden sind die schwersten zu finden.C# geht einen komplett anderen Weg und trennt nicht in Checked/Unchecked Exceptions sondern verbietet jede Art der Exception Spezifikation.
Exception Translation
Oft kommt es vor, dass ein Fehler der aufgetreten ist zu Low-Levelig ist als dass man ihn weiter werfen will. Als Beispiel betrachten wir eine Datenbank Anwendung die alle Tabellen in Dateien ablegt. Bei einem Verbindungsaufbau wird ein WriteLock auf die entsprechende Datenbank Datei gemacht und darauf operiert. Wenn nun diese Datei nicht vorhanden ist, dann fliegt eine
FileNotFoundException. Der Anwender unseres Codes wird sich aber wundern warum einFileNotFoundfliegt, da er ja eigentlich keine Datei öffnen wollte, sondern eine Verbindung zu einer Datenbank. Wir offenbaren unsere Implementationsdetails. Das ist nie gut und wenn wir von Dateien weggehen und stattdessen einen echten Server irgendwo in unser Netzwerk stellen fliegt plötzlich nie wieder eineFileNotFoundException. Um dieses Problem zu lösen verwendet man Exception Translation. Das ist ein hochtrabender Namen für das Umwandeln einer Low Level Exception wieFileNotFoundin eine High Level Exception wieDatabaseConnectionException.Das ganze sieht wenig Spektakulär aus:
try { ConnectToDatabase(); } catch(FileNotFoundException e) { throw new DatabaseConnectionException(); }Exception Chaining
Das Problem bei Exception Propagation ist aber, wir verlieren die Low Level Daten warum die Operation fehlgeschlagen ist. Wir können jedesmal natürlich alle Informationen aus der Low Level Exception rauskitzeln und in die High Level Exception übertragen. Aber es gibt einen einfacheren Weg: Exception Chaining. Exception Chaining erlaubt uns genau diese Umwandlung einer
FileNotFoundExceptionin eineDatabaseConnectionExceptionException ohne Informationsverlust:try { ConnectToDatabase(); } catch(FileNotFoundException cause) { throw new DatabaseConnectionException(cause); }Der Vorteil von Exception Chaining ist der, dass wir uns bis zu der ursprünglichen Exception durchhandeln können und wir selbst durch das umwandeln von Low Level Exceptions in High Level Exceptions keine Information verlieren. Denn eine Exception ist nun nichts andere als ein Knoten in einer einfach verketteten Liste. Wir können problemlos alle Umwandlungsschritte nachvollziehen.
Die C++ Exception Klassen haben dieses Feature nicht eingebaut - auch hat man in C++ das Problem dass man dafür Exceptions kopieren müsste und eine Kopieroperation eine Exception werfen kann.
rethrow
Sie haben gesehen, dass man aus einem catch-Block Problemlos eine Exception werfen kann. Das führt uns zu einem interessanten Punkt: kann man auf einen Fehler reagieren und ihn dann weiter reichen? Es kommt öfters vor, dass man Fehler nicht komplett behandeln kann - meistens kann man nichts tun und nur den Cleanup Code ausführen. Dafür haben wir ja finally bzw. RAII kennengelernt. Manchmal müssen wir aber bei einem Fehler etwas anders reagieren als bei keinem Fehler - der finally Block unterscheidet ja nicht zwischen Fehlerzustand und Normale Beendung der Funktion. Nehmen wir an wir wollen den Fehler loggen:
try { something(); } catch(SpecificException& e) { log(e); throw e; //??? }Hier gibt es 2 Faelle zu Unterscheiden: throw und rethrow. Ein throw wirft eine neue Exception - dh, dass ein eventueller Stacktrace verloren geht oder die Zeilennummer/Datei in der die Exception geworfen wurde wird auf diese aktuelle Zeile gesetzt - wo der Fehler aber nicht auftrat. Ein rethrow erlaubt uns die Exception ohne Änderung weiterzuwerfen. In C++ und C# macht man ein rethrow über ein throw ohne Exception Paramater:
try { something(); } catch(SpecificException& e) { log(e); throw; }In Java dagegen gibt es keinen Unterschied zwischen throw und rethrow - jedes throw von einer bereits geworfenen Exception ist ein rethrow.
Unhandled Exceptions
Wenn wir eine Exception werfen (bzw. weiter werfen) und diese nicht fangen, wird sie zu einer sogenannten Uncaught/Unhandled Exception und unser Programm beendet sich. Auf den 1. Blick sieht es komisch aus, dass es gut sein soll dass keine Ressourcen aufgeraeumt werden, aber es hat durchaus seinen Sinn: Wenn etwas total unerwartetes passiert (und eine Unhandled Exception ist nichts anderes als ein Fehlerfall auf den wir nicht vorbereitet waren - ihn also nicht erwartet haben) dann sollte man die Anwendung so schnell wie möglich beenden. Denn in der Regel kann man sich von solchen Fehlern nicht mehr erholen, da man ja nicht weiss was genau passiert ist. Wenn wir den Fall einmal ausschliessen dass wir einen Fehler gemacht haben und eine Exception die wir fangen hätten sollen durchgelassen haben - dann ist die wahrscheinlichkeit groß, dass Anwendungsinterne Daten korrupt sind. uU haben wir einen Buffer Overflow produziert und irgendwo im RAM stehen ungültige Daten die eben diesen Fehler provoziert haben. In so einer Situation will man die Anwendung so schnell wie möglich beenden und sowenig Code wie möglich ausführen (da man nicht mehr garantieren kann, dass der Code fehlerfrei arbeitet).
Normalerweise haben wir einen globalen try-catch Block wo wir die meisten erwarteten Fehler abfangen, aber unerwartete Exceptions sollte man an das Betriebssystem durchlassen. Das Betriebssystem kann dann einen sehr schönen Crash Report erstellen - etwas das die Anwendung selber nicht kann. Denn das Betriebssystem kann garantiert funktionierenden Code ausführen (was die Anwendung ja nicht mehr kann). Essentielle Ressourcen kann man natürlich selber ruhig noch frei geben - aber jeden Destruktor aufzurufen waere zuviel des guten (denn mit jedem Code den wir ausführen steigt das Risiko noch mehr unerwartetes Verhalten zu produzieren).
Hinter den Kulissen
Betrachten wir uns einmal was hinter den Kulissen vorsich geht. Wie implementieren Compiler diesen Exception Mechanismus? Als Beispiel nehmen wir den VC++ 2005 heran. Mit VC++ 2008 hat sich in Bezug auf Exceptionhandling nichts Grundlegendes verändert, es wurden nur ein paar kleine Optimierungen eingebaut - die Struktur blieb aber gleich.
Sehen wir uns folgenden einfachen Code an:
class Class {}; void do_nothing() { } void might_throw() { if(rand() % 2) { throw SomeException(); } } void two_objects() { Class objA; might_throw(); Class objB; might_throw(); Class objC; } void pass_through() { two_objects(); } void foo() { try { pass_through(); } catch(SomeException& e) { do_nothing(); throw; } } int main() { foo(); }Der Compiler muss im Falle einer Exception genau wissen was er zu tun hat - er muss deshalb irgendwo Informationen haben wo das Programm steht und was es zu tun gibt. Unter Windows 32 Bit ist das ganze per einfach verketteter Liste geloest in der alle Funktionen stehen die im Falle einer Exception etwas tun müssen. Sehen wir uns diese Liste einmal an:
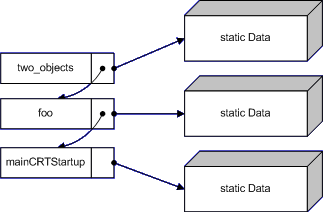
might_throwwirft eine Exception, aber es gibt nichts zu tun. Keine Objekte die zerstört werden müssen und keine catch Blöcke.two_objectsbraucht dagegen einen Eintrag in der Unwind-Liste. Denntwo_objectserstellt Objekte die zerstört werden muss wenn eine Exception fliegt.pass_throughhat keinen Eintrag in der Liste denn egal was passiert,pass_throughleitet die Exception nur weiter ohne selber zu reagieren.foodagegen hat einen catch Block und muss somit Code ausführen wenn eine Exception fliegt. Der catch Block enthält Code um zu überprüfen ob die Exception hier gefangen wird oder durchgelassen wird. Selbst wennfoodie Exception nicht fangen würde, müsste dieser Code dennoch ausgeführt werden.mainist wiepass_throughrecht langweilig.mainCRTStartupist eine magische Funktion der C/C++ Runtime. Hier werden globale Variablen wieerrnoinitialisiert, der Heap angelegt,argc/argvgefüllt, etc. und ebenfalls ein try catch Block ummaingelegt.Jedesmal wenn eine Funktion betreten wird, wird ein Eintrag in der Unwind-Liste gemacht. Da aber einige Funktionen keinen Code haben der abhängig von Exceptions ist, werden diese Funktionen nicht in der Liste eingetragen. Dieser Eintrag kostet natürlich Zeit und Speicher, deshalb optimiert der Compiler wo er nur kann. Static Data enthält Daten zu den jeweiligen Funktionen die den aktuellen Status angeben.
Die interessante Funktion ist
two_objects. Sehen wir unstwo_objectseinmal so an, wie ein sehr naiver Compiler sie implementieren könnte:void two_objects() { //Metadaten //eintrag in Unwind Liste Function this = new Function(); unwindList.add(&this); this.status=0; //objekte anlegen: Class* objA; Class* objB; Class* objC; //Class objA; - objekt initialisieren objA=new Class(); this.status=1; might_throw(); if(exception) goto cleanup; //Class objB; - objekt initialisieren objB=new Class(); this.status=2; might_throw(); if(exception) goto cleanup; //Class objC; - objekt initialisieren objC=new Class(); this.status=3; //aufräumen cleanup: if(this.status==3) { delete objC; this.status=2; } if(this.status==2) { delete objB; this.status=1; } if(this.status==1) { delete objA; this.status=0; } if(this.status==0) { unwindList.remove(&this); delete this; } }Der Cleanup Code wird aus dem "static Data" Block abgeleitet auf den das aktuelle Unwind Element zeigt. Diese status Variable immer auf dem Laufenden zu halten kostet ebenfalls Zeit und wird deshalb nur dann gemacht, wenn es wirklich notwendig ist.
this.status=3;waere in dem obigen Code wegoptimierbar.Unter Windows 64 Bit sieht das ganze schon etwas besser aus. Statt einer Unwind Liste haben wir eine Unwind Map und als Schlüssel verwenden wir den Wert des Instruction Pointers, IP, zu dem Zeitpunkt als die Exception geworfen wird.
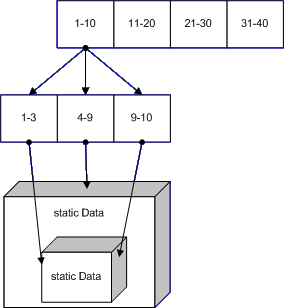
Der Vorteil hier liegt auf der Hand: wir haben keine teure Liste die wir pro Funktionsaufruf ändern müssen, wir haben nur eine komplexe Map die wir einmal erstellt haben. Über den IP kann man den aktuellen Status der Funktion (und vorallem auch die Funktion selber in der man sich gerade befindet) herausfinden. Der Nachteil liegt im höherem Aufwand falls eine Exception geworfen wird. Da Exceptions aber nur fliegen wenn sowieso etwas nicht mit rechten Dingen zugeht, ist es durchaus vertretbar - vorallem wenn man dafür den nicht-Exception Pfad deutlich beschleunigen kann.
Das ganze soll nicht vor Exceptions abschrecken - sie sind zwar nicht gratis (aus Performance Sicht) aber man darf nicht vergessen dass ein
if()oder gar ganzeswitch()Orgien bei der if-then-else Fehlerbehandlung auch nicht gerade wenig Zeit kostet.Wenn nun eine Exception geworfen wird, kann die Funktion sich selber dank der status Informationen unwinden - aber wie genau wird der passende catch-Handler gefunden? VC++ geht hier einen 2-Pass Weg, es wird die Unwind Liste also 2 mal durchgegangen.
Beim 1. Pass wird ein passender Exceptionhandler gesucht. Wenn keiner gefunden wird, wird
terminate()aufgerufen welchesabort()aufruft und das Programm beendet. Wenn aber einer gefunden wurde, dann wird der 2. Pass ausgeführt in welchem das Unwinding beginnt.Exkurs: Exceptions in C
Im vorherigen Abschnitt haben wir einen Blick hinter die Kulissen des Exceptionhandlings geworfen. Doch C bzw. C++ wäre nicht C bzw. C++ wenn man das ganze nicht auch händisch implementieren könnte. Einige Exceptionimplementierungen basieren auf genau dem Prinzip das Sie gleich kennen lernen werden. Vorallem im Embedded Bereich wo öfters C++ Exceptions nicht verwendet können werden setzt man öfters C Exceptions ein.
Der Trick hinter Exceptions in C sind die beiden Funktion
setjmp()undlongjmp(), deshalb wird diese Art der Implementierung auch gerne sjlj-Exceptions genannt.setjmpsichert den aktuellen Kontext in einen sogenannten jump Buffer. Der Kontext enthält unter Anderem die auto Variablen am Stack und die Registerwerte.setjmpliefert immer 0 als Ergebnis. Nun verwendet manlongjmpum einen Kontext wiederherzustellen (einschließlich des Instruction Pointers), wir landen mit der Ausführung als wieder in der Zeile in der wirsetjmp()aufgerufen haben.longjmpgeben wir aber einen bestimmten Integer Wert mit und diesen liefertsetjmpuns jetzt - so können wir zwischen den einzelnen Fällen unterscheiden.Da das sehr theoretisch klingt, ein kleines Beispiel:
#include <stdio.h> #include <setjmp.h> #include <assert.h> jmp_buf jbuf; #define E_DIVBYZERO -1 #define E_NOCLEANDIV -2 int divide(int a, int b) { if(b==0) { longjmp(jbuf, E_DIVBYZERO); } if(a%b != 0) { longjmp(jbuf, E_NOCLEANDIV); } return a/b; } int main() { switch(setjmp(jbuf)) { case 0: { int a,b,c; puts("please input an integer"); scanf("%d", &a); puts("please input another integer"); scanf("%d", &b); c=divide(a, b); printf("%d divided by %d gives %d\n", a, b, c); return 0; } case E_DIVBYZERO: { fputs("The integers couldn't be divided, due to a division by zero error.\n", stderr); return -1; } case E_NOCLEANDIV: { fputs("The integers couldn't be divided without a remainder.\n", stderr); return -1; } default: assert(0); } assert(0); }divide()dividiert 2 integer Werte und liefert einen Fehler wenn der Divisor 0 ist oder die Division einen Rest ergibt. Sobald wir eine Fehlersituation individehaben, springen wir mitlongjmpin das switch in main. Dort wird das Ergebnis ausgewertet und der passende Case Zweig angesprungen.Ein Wort der Warnung ist hier aber angebracht: lesen Sie genau in ihrer Compilerdokumentation nach wie sich sjlj in einem C++ Programm verhält. Denn in einem C++ Programm muss der Destruktor von Objekten am Stack ausgeführt werden (etwas das wir uns in C ja sparen können).
Einen etwas tieferen Einblick in sjlj-Exceptions bieten Ihnen Tom Schotland und Peter Petersen.
Exception Safety Testen
Wie können wir garantieren dass unsere Klassen Exception sicher sind? Wir können natürlich den Code stundenlang analysieren und irgendwann sagen: so, jetzt haben wir alle Situationen bedacht. Das ist aber unpraktisch und in der Software Entwicklung lechzen wir nach Automatisierungen.
Unittest: eine komplette Automatisierung ist mir leider nicht bekannt, aber es gibt Techniken die man in seine Unittests einbauen kann. Die Idee ist eine Funktion
mightThrow()in jede Funktion zu packen die eine Exception werfen darf. Einfach ist das ganze wenn wir zB einen Container und ähnliches Testen wollen:class ThrowTestClass { private: int value; public: TestClass(int value=0) : value(value) { mightThrow(); } TestClass(TestClass const& other) : value(other.value) { mightThrow(); } int operator=(TestClass const& other) { this->value = other.value; mightThrow(); } //... }; int main() { std::vector<ThrowTestClass> vec; test(vec); }Die ganze Magie befindet sich in der Funktion mightThrow.
void mightThrow() { if(!throwCounter--) { throw ExceptionSafetyTestException(); } }Wir nehmen eine globale Variable und reduzieren sie immer um 1 wenn
mighThrowaufgerufen wird. WennthrowCounter0 erreicht hat, dann wird eine Exception geworfen. Idealerweise iteriertmightThrowdann durch alle Exceptions die die Funktion werfen darf, meistens ist das aber zuviel des guten und es reicht eine Standard Exception zu werfen. Sehen wir uns dazu jetzt die Testfunktion an:template<class Data, class Test> void basicGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { //nothing } invariants(copy); } } template<class Data, class Test> void strongGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { REQUIRE(copy == data); } invariants(copy); } }Mit Hilfe von Regular Expressions lässt sich die Dokumentation des Codes dazu nutzen die notwendigen throws zu generieren. Dabei wird auf einer Kopie des originalen Source Codes gearbeitet und am Anfang jeder Funktion die Exceptions werfen darf ein
mightThrow()eingefügt.Leider kenne ich keine Unittest Library die das unterstützt - aber vielleicht regt dieser Artikel ja den einen oder anderen an sowas in bestehende Librarys reinzupatchen.
Der Code der Testfunktion sollte leicht verständlich sein, deshalb sehen wir ihn uns nur kurz naeher an.
dataist ein Datenobjekt, zB ein Objekt einer Klasse undtestist ein Objekt dass den Test ausführt. So könntedatazB einstd::vectorsein undtestkönnte den operator= testen. Der throwCounter ist eine globale Variable die bestimmt wann mightThrow eine Exception wirft und anhandfinishederkennen wir, wann keine Exception mehr geworfen wurde (und deshalb der Test beendet ist). Wir arbeiten dabei die ganze Zeit nur auf einer Kopie der echten Daten, da wir ja (zumindest bei der strong Garantie) testen wollen ob der Zustand trotz Exception identisch geblieben ist. Mitinvariants()überprüfen wir zum Schluss ob die Invarianten noch alle stimmen.Interoperability von Exceptions
In C++ leiden wir unter dem Fehlen eines ABI-Standards. Wir können leider nicht garantieren dass eine Exception die ein Binary (zB eine DLL oder SO) verlaesst kompatibel mit den Exceptions in dem Binary ist, dass die Exception fängt. Natürlich ist es möglich diese Kompatibilitaet zu erzwingen und in einigen Situationen macht das auch durchaus Sinn, aber wir sollten nicht davon ausgehen dass dies immer zutrifft. Wir haben in C++ also das Problem, dass wir Exceptions nicht über Binary Grenzen hinweg werfen dürfen. Wir müssen in solchen Situationen zu dem alten if-then Error Handling zurückkehren.
Java und .NET haben dieses Problem nicht, da sie jeweils ein standardisiertes ABI haben und daher das werfen und fangen von Exceptions über Binary Grenzen hinweg kein Problem darstellt.
Exception sicheres Klassen Design
Nach welchen Richtlinien schreibt man denn nun Exception sichere Klassen? Das Paradebeispiel dafür ist eine Stack Klasse wie
std::stack- wobeistd::stackja eigentlich nur ein Container Adapter ist. Eine naive Implementierung einer Stack Klasse könnte so aussehen:template<typename T> class Stack { private: T* data; std::size_t used; std::size_t space; public: explicit Stack(std::size_t expectedElements = 100) : data(static_cast<T*>(operator new(expectedElements*sizeof T))) , used(0) , space(expectedElements) { } Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); } ~Stack() { std::destroy(data, data+used); operator delete(data); } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; } T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; } bool empty() const { return used==0; } std::size_t size() const { return used; } void swap(Stack& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } };Hier gibt es eine Menge Probleme. Gehen wir sie der Reihe nach an:
Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); }Sollte eine Kopieroperation in
std::uninitialized_copyfehlschlagen, so wird der Speicher auf den data zeigt nicht aufgeräumt.void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; }space wird erhöht bevor die Kopieroperationen beendet sind. Sollte new oder
std::copy()fehlschlagen bleibtspaceauf dem erhöhten Wert obwohl keine Erhöhung stattfand.T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; }Sollte eine der beiden Kopieroperation fehlschlagen, geht das Objekt für immer verloren da wir es bereits aus unserem Stack gelöscht haben - es aber nie beim Caller ankam.
Eine elegantere Variante diese Probleme zu umgehen wäre folgende Implementierung:
template<typename T> class StackImpl { public: T* data; std::size_t used; std::size_t space; explicit StackImpl(std::size_t elements) : data(static_cast<T*>(operator new(elements*sizeof T))) , used(0) , space(elements) { } ~StackImpl() { std::destroy(data, data+used); operator delete(data); } void swap(StackImpl& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } private: StackImpl(StackImpl const&); StackImpl& operator=(StackImpl& const); }; template<typename T> class Stack { private: StackImpl<T> impl; public: explicit Stack(std::size_t expectedElements = 100) : impl(expectedElements) { } Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; } void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } bool empty() const { return impl.used==0; } std::size_t size() const { return impl.used; } void swap(Stack& other) { impl.swap(other.impl); } };Da wir eine Hilfsklasse verwenden die das Speichermanagement übernimmt, entstehen im Konstruktor keine Speicherlecks mehr:
Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; }Sollte
std::uninitialized_copyfehlschlagen wird dennoch impl zerstört und der Speicher korrekt freigegeben. Wichtig ist, dassusederst gesetzt wird nachdem das Kopieren erfolgreich war.void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; }Wir verwenden hier das bekannte Copy&Swap um den Speicherbereich zu vergrößern. Wir reduzieren dadurch den nötigen Code und gewinnen Robustheit.
void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; }Ein
pop()dass den gepopten Wert by Value liefert, kann nie Exception Sicher sein. Wir brauchen daher einetop()Methode um an das oberste Element zu gelangen. Nebenbei gewinnen wir dadurch noch die Möglichkeit Stack als ein konstantes Objekt verwenden zu können, da wir nun mittop()an das oberste Element kommen ohne den Stack ändern zu müssen.Design von Exception Klassen
Je nachdem mit welcher Sprache man arbeitet sehen Exceptions immer leicht anders aus. Exceptions können das Debuggen erleichtern wenn sie wichtige Informationen wie Was ist passiert?, Wo ist es passiert? und uU auch ein Warum ist es passiert? mitteilen. Das essentielste davon ist "Was ist passiert?". In der C++ Standard Library über die virtuelle Funktion exception::what() gelöst. Java und C# bieten jeweils noch eine Antwort auf die Frage "wo ist es passiert?" Anhand eines Stack Traces. C++ bietet soetwas nicht eingebaut, aber man kann dennoch an einen Stack Trace gelangen.
Die einfachste Möglichkeit einen Stack Trace zu bekommen ist einen Debugger mitlaufen zu lassen - in der Debug Version während wir noch testen - werden wir das vermutlich sowieso immer machen. Aber wenn wir keinen Debugger mitlaufen lassen haben, können wir die System API verwenden (sofern wir mit Debug Informationen kompiliert haben) oder aber eine fertige Lösung.
Das wichtigste Feature dass Exception Klassen bieten müssen ist eine durchdachte Hierachie. Denn wenn jeder Fehler der erzeugt wir lediglich vom Typ
StandardExceptionist, kann man nur sehr schwer darauf reagieren. Es ist wichtig einen Mittelweg aus zu tiefer Hierachie und zu breiter Hierachie zu finden. Denn wenn wir eine Exception von einer anderen erben lassen muss dies wirklich eine "A ist spezialfall von B"-Situation sein. Oft ist so eine Entscheidung nicht leicht zu treffen: wenn ich eine Datei nicht öffnen kann weil mir die Rechte fehlen, ist das dann eineIOExceptionoder eineSecurityException?Der Konstruktor einer Exceptionklasse darf nie eine Exception erzeugen - denn wir wissen ja: sollte eine Exception auftreten während eine Exception behandelt wird, wird das Programm beendet. Das bedeutet auch, dass man mit Speicherreservierungen vorsichtig sein muss.
Exception Sicherheit ohne try/catch
Der große Vorteil von C++ Exceptions ist RAII. Anstatt überall try/catch schreiben zu müssen, können wir mit RAII die Fehlerfälle meistens sehr gut abfangen ohne sie explizit zu behandeln.
Betrachten wir folgenden Code:
class Class { private: char* name; int* array; public: Class(char const* name) : name(new char[strlen(name)+1]), array(new int[100]) { strcpy(this->name, name); fill(array); } //... };Das Problem ist offensichtlich: wenn eine der beiden Allokationen fehlschlägt, wird die andere nicht mehr rückgängig gemacht. Wir könnten also mit try/catch versuchen das Problem zu lösen:
class Class { private: char* name; int* array; public: Class(char const* name) : name(0), array(0) { try { this->name = new char[strlen(name)+1]; array = new int[100]; } catch(std::bad_alloc& e) { delete [] this->name; delete [] array; throw; } strcpy(this->name, name); fill(array); } //... };Das funktioniert zwar, aber es geht besser:
class Class { private: std::string name; std::vector<int> array; public: Class(char const* name) : name(name), array(100) { fill(array); } //... };Nicht nur dass wir jetzt keine Memory-Leaks mehr haben, wir haben auch noch den Code reduziert und schlanker gemacht. Meistens ist es eine gute Idee dynamische Allokationen in eine Ressourcen Klasse zu stecken, da so nicht nur Fehler verhindert werden sondern der Code auch deutlich einfacher gestaltet bleibt.
Besonders problematisch sind dynamische Allokationen in einem Funktionsaufruf:
foo(new Bar(), new Baz());Mit Smart Pointern wie zB scoped_ptr/auto_ptr oder shared_ptr kann man diese Probleme umgehen indem die Smart Pointer die Ressource verwalten.
Die weite Welt
Exception Handling ist nur eine mögliche Lösung für das komplexe Problem der Fehlerbehandlung. Sie haben in diesem Artikel bereits ein paar Methoden kennengelernt, es gibt aber noch weit mehr. Jede dieser Methoden hat Vorteile und Nachteile, es gibt keine beste Lösung hier.
Error Stack
Jeder Fehler der auftritt wird auf einen bestimmten Stack gesetzt und die Funktion beendet sich selbst. An bestimmten Code Stellen kann man dann auf Fehler testen die ja alle auf diesem Error Stack liegen. Jeder Code kann einen behandelten Fehler vom Stack poppen - man hat somit ein feineres System was Fehlerbehandlung betrifft als wir bei Exceptions haben (wo es nur den Zustand Fehler (Exception wurde geworfen) und nicht Fehler (keine Exception geworfen) gibt.
Deferred Error Handling
iostreammacht es vor: wenn ein Fehler auftritt, dann setzen wir ein internes error-flag und teilen so mit dass etwas schiefgegangen ist.Callbacks
Unter Unix sind Signals recht bekannt, in der Windows-Welt eher nicht. Dennoch bieten Signale eine interessante Möglichkeit Fehler zu handhaben. Jedesmal wenn ein Fehler auftritt wird ein Signal generiert, auf dass eine Anwendung (oder ein Teil einer Anwendung) per Callback reagieren kann indem man das Callback für das entsprechende Signal registriert.
Zu diesen 3 Methoden gibt es unter C++ Exception Alternatives auch ein bisschen Lesestoff wenn Sie mehr erfahren wollen.
Conditions
Nicht jeder Fehler ist ein fataler Fehler. Conditions ermöglichen es an definierten Stellen von einem Fehler zu recovern.
Fehler passieren und egal was wir für eine Methode verwenden um sie zu Handhaben, wir müssen acht geben.
-
bitte technische Fehler, vorallem in den source codes finden und mir sagen
")
uU auch fuer den letzten abschnitt mehr alternativen fuer exceptions finden.
-
Ist jetzt Korinthen-hacken aber vielleicht bist du ja Perfektionist und willst es ändern.
")
PHP macht sich zu Nutzen dass jede Variable jeden Typ haben kann. isError erkennt ob $var vom Typ PEAR_Error (oder einer Subklasse davon) ist und liefert dementsprechend true oder false. Dadurch hat man verhindert dass jede Funktion einen anderen Fehlerwert liefert und mit leicht behandelbare Fehlerobjekte lassen sich auch Unterschiedliche Fehler leichter unterschiedlich behandeln.
Doch auch das war nicht der Weisheit letzter Schluss. Da wir immer noch die Fehler lokal behandeln müssen und dies bedeutet wir müssen dort wo der Fehler auftritt wissen wie wir darauf reagieren wollen.
Das stimmt so nicht. Hier hast du C++-denken auf PHP übertragen. In C++ hast du in vielen Fällen keine ordentliche Möglichkeit einen Fehlerwert zurück zu geben, von daher bist du gezwungen es lokal zu behandeln da es nicht leicht nach oben propagiert werden kann. In PHP kannst du aber einfach das Errorobjekt zurück geben und somit ist eine Propagation nach oben sehr leicht möglich, wenn auch sehr anfällig für Programmierfehler.
-
Ben04 schrieb:
Das stimmt so nicht. Hier hast du C++-denken auf PHP übertragen. In C++ hast du in vielen Fällen keine ordentliche Möglichkeit einen Fehlerwert zurück zu geben, von daher bist du gezwungen es lokal zu behandeln da es nicht leicht nach oben propagiert werden kann. In PHP kannst du aber einfach das Errorobjekt zurück geben und somit ist eine Propagation nach oben sehr leicht möglich, wenn auch sehr anfällig für Programmierfehler.
ICH HAB HIER GEPOSTET DAMIT DU JA UND AMEN SAGST UND NICHT DAMIT DU MICH KRITISIERTS!!!!

:p
natuerlich. dummer fehler von mir. muss mal ueberlegen wie man das am sinnvollsten umschreibt.danke.
-
Shade Of Mine schrieb:
ICH HAB HIER GEPOSTET DAMIT DU JA UND AMEN SAGST UND NICHT DAMIT DU MICH KRITISIERTS!!!!
kritisierst
-
Ein einfaches Beispiel ist hier zB die Funktion std::swap().
std::swap liefert aber nicht die nothrow Garantie. Kann es auch gar nicht, da es per default den Dreieckstausch verwendet der eine Kopie anfertigt.
typedef target_container vector< typename std::iterator_traits< OutputIterator >::value_type > ;Ist da nicht etwas verdreht?
Und dein copy hat nicht die strong-Garantie. Input Iteratoren dürfen die Daten on the fly generieren und Nebeneffekte haben (Zum Beispiel von cin lesen). Diese Nebeneffekte werden aber nicht zurückgespult, da dies gar nicht möglich ist. Du benötigst mindestens Forward-Iteratoren. [edit]Ich bin mir nicht sicher ob das reicht. Ein buffered-istream_iterator wäre ja auch ein Forward-Iterator.[/edit]
Vielleicht die Klammer mit dem finalizer weg lassen. Sie ist zwar schön tief verbuddelt daher ist das Risiko klein, aber das Potential für ein Java-vs-C++ Thread hat sie.
Bin noch nicht ganz durch den Artikel.
-
In "Aber in C macht man es anders" ist das [c] falsch gesetzt. "zB" würde ich lieber ausschreiben, da Abkürzungen in einem Artikel imho eher stören.
In "Der PHP4 Ansatz": Ich würde eher schreiben: "In PHP4 hat man das zweite Problem sehr schön lösen können und da PHP einen Garbage Collector hat fällt auch dritte Problem weg:"
In "Was Exceptions bieten": "Das Problem mit Fehlern die "nie" auftreten können ist jedoch, dass die Hölle los ist, wenn sie doch auftreten."
"Doch Sie, als aufmerksamer Leser haben natürlich sofort erkannt dass ich Ihnen ein Problem unterschlagen habe: wie verhält es sich mit dem Cleanup Code?"
In "Der finally Block": "In C++ haben wir diesen Luxus nicht" hmm, Luxus finde ich zu sehr wertend. Sind einfach zwei unterschiedliche Philosophien. bzw. RAII ist bei einem GC auch nicht wirklich möglich. Als Nachteil würde ich vielleicht noch aufzählen, dass man explizit Ressourcen freigeben muss (was man ja durchaus vergessen kann).
In "Design by Contract": Wenn du die Abkürzugn DbC einführst, solltest du sie imho vorher auch angeben. Also zB einfach "Ein wichtiger Bestandteil von Design by Contract (kurz DbC) sind ..."
Vielleicht solltest du auch erwähnen, dass DbC in Eiffel eingeführt wurde.
In "Exception Spezifikationen": Ich würde den Satz "Java geht hier einen Schritt weiter und definiert 2 Arten von Exceptions: Checked und Unchecked Exceptions." in den Unterabschnitt "Unchecked/Checked Exceptions" verlegen
Hab noch nicht weiter gelesen. Gefällt mir aber der Artikel.
-
aber wie sieht das ganze mit fopen(NULL) aus?
Blödeste Antwort: Syntax error (da fehlt der zweite Parameter).
Immer noch blöd aber ich kann es mir nicht verkneifen: /dev/null öffnen.
Bei Assert könntest du noch sagen, dass wenn der Debugger nicht automatisch anspringt (mindestens MinGW) dann kann man ein (((char)0)=0) in Definition von Assert einbauen. Dann springt der Debugger an.
aber asserts sind ideal um Invarianten bzw. Pre/Post Conditions zu testen
public f: assert pre condition call g assert post condition private g: verletze Invariante call f stelle Invariante wieder herAls ideal würde assert also nicht bezeichnen.
return result; postcondition { equal(first, last, result) &&//Zugriff auf die originalen Werte return == result + (last-first) }Den Pseudocode verstehe ich nicht. Wieso nicht einfach die Bedingung in assert packen?
ist klar ([first,last) könnte
'ne Klammer zuviel.
std::map muss zu jedem Zeitpunkt sortiert und balanziert sein - dass ist also die Invariante.
Das könnte man so lesen, als wenn std::map die Invariante nicht innerhalb einer Methode verletzen darf.
Invarianten werden immer aufgerufen nachdem...
überprüft, Invarianten sind keine Funktionen im C/C++-Sinn.
Die Theorie besagt: solange das Objekt in einem konsistenen Zustand ist, kann es zu keinem Fehler kommen.
Welche Theorie? Ich bin mir sicher, dass es Theorien gibt welche Netzwerkfehler mit in die Invarianten packen. Die Aussage ist also IMO nicht allgemein gültig.
Beim Map-Beispiel kannst du unter Umständen auf meinen Artikel zu Binär-Bäumen verweisen. Ich habe da Code drin welcher explizit Invarianten überprüft.
Der DM unterstützt DbC in C und C++ als Compilererweiterung. Leider ist dies nicht weit verbreitet und daher wahrscheinlich auch nicht erwähnenswert. Wenn es dich interessiert:
http://www.digitalmars.com/ctg/contract.htmlUnchecked Exceptions sind dagegen die Fälle bei denen wir in C++ ein assert nehmen würden, nämlich Vertragsverletzungen.
oder std::logic_error
Vielleicht noch erwähnen, dass der VC Exception Spezifikationen gar nicht unterstützt. Dies unterstreicht die Unbedeutendheit.
Essentielle Ressourcen kann man natürlich selber ruhig noch frei geben - aber jeden Destruktor aufzurufen wäre zuviel des guten (denn mit jedem Code den wir ausführen steigt das Risiko noch mehr unerwartetes Verhalten zu produzieren).
Das klingt als wenn bei Unhandled Exceptions der Stack nicht abgeklappert werden würde und diese Destruktoren nicht aufgerufen werden würden. Ich glaube nicht, dass dies bei jedem Compiler der Fall ist.
Unter Windows 32 Bit
Bist du dir sicher, dass der VC unter Win32 immer diese Methode wählt? Ich dachte der hätte noch andere Modelle zur Auswahl.
Bin immer noc nicht ganz durch. Der Artikel ist schon lang geworden.
-
Warum noch ein Thread? Eigentlich hätte es im bisherigen weitergehen sollen, einfach Status auf [T] umstellen. Aber na ja, egal, beim Umstellen auf [R] dann in diesem Thread bleiben.
-
GPC schrieb:
Warum noch ein Thread? Eigentlich hätte es im bisherigen weitergehen sollen, einfach Status auf [T] umstellen. Aber na ja, egal, beim Umstellen auf [R] dann in diesem Thread bleiben.
Sorry, das ist mir zu spaet aufgefallen. Ich habe naemlich kurz ueberlegt ob die Konvention ist den Thread weiterzufuehren oder einen neuen aufzumauchen. Dann habe ich die 2 OpenMP threads gesehen und nicht weiter nachgedacht.
erst nachher gesehen dass es bei dem openmp thema einen anderen grund hatte.
nicht gruendlich genug nachgelesen, sorry

@alle:
danke, das meiste klingt super.
-
Noch was: Der Titel des Threads sollte zum Titel des Artikels passen. Also "Modernes Exception Handling" und nicht einfach "Exceptions"
-
@Ben04:
Bei dem finalizer stimme ich dir nicht zu.
Der Rest sollte jetzt aber passen.zu dem copy habe ich einen Absatz danach hinzugefuegt - ich denke das passt so ziemlich gut. Es zeigt das Konzept der strong Garantie und weisst gleich auf einen pitfall hin (auf den ich ja selber reingefallen bin).
asserts sind ideal habe ich in "praktisch" geaendert
der pseudocode zu den postconditions kann nicht mit assert gemacht werden, weil ich zB den return value brauche und die originalen werte die uebergeben wurden - features die c++ nicht bietet.
([first,last) - keine klammer zuviel, nur unpraktisch, da [first,last) in einer klammer steht... habe einen abstand eingefuegt
zu "die theorie": ich gehe da ja nicht auf invarianten oder sonstwas ein. theoretisch ist ein fehlerfreier code ohne fehler. praktisch ist das nicht der fall, da fehler durch die falsche komposition von korrektem code entstehen koennen. was ich damit sagen will ist:
wenn wir garantieren koennen dass unsere objekte immer in einem konsistenten zustand sind, dann koennen wir davon ausgehen dass sie korrekt arbeiten.dmc++ kenne ich, aber es verwenden zuwenige dass man da sinnvoll hinweisen kann. wenn es eine oeffentliche library gaebe die dbc in c++ vernuenftig unterstuetzt (uU auch mit eigenem precompiler) dann waere das was anderes.
bei deinem map artikel geht es nicht um invarianten - ich sehe also nicht viel sinn das zu verlinken. der artikel hat eine komplett andere zielgruppe...
vertragsverletzungen sollten kein logic_error werfen. das ist der ganze sinn eines vertrags: fehler nicht ignorieren zu koennen. logic_error macht fast nie sinn.
unhandled exception: mhm, ja. dumme compiler koennten den stack unwinden. hab extra im standard nachgeschlagen: das verhalten ist implementation defined. dumme sache
muss ich mir noch ueberlegen was ich da hinschreibe.exception handling vom vc++: das ist die standard methode. sie aendert sich ganz leicht, wenn man synchron/asynchrones exception handling waehlt - aber die generelle struktur bleibt gleich. gcc bietet soweit ich weiss sjlj und dwarf2. wie dwarf2 funktioniert habe ich keinen schimmer, aber sjlj habe ich ja auch vorgestellt. worum es mir aber geht ist generell einen ueberblick ueber die technik zu geben und nicht eine genaue beschreibung ueber compiler implementationen
@kingruedi:
bei finally: luxus jetzt in feature geaendert.
rest ebenfalls angepasstalles was ich nicht kommentiert habe, habe ich geaendert.
danke fuer die hilfe aber jetzt nur nicht nachlassenPS:
woha, maximale beitragslaenge gefunden und ueberboten... krass...
-
modernes Exception Handling
In dem Artikel Exception-Handling haben Sie bereits erfahren dass auch der beste Programmierer an Fehler denken muss. Sie haben Exceptions kennengelernt und gesehen wie flexibel diese Ihnen die Arbeit erleichtern können. Doch Exceptions sind nicht nur ein Segen, sondern auch ein Fluch. Bevor wir jedoch die Nachteile von Exception näher betrachten, wollen wir uns die Vorteile ansehen - oder besser: die Alternativen.
Die Alternativen
Exceptions sind nicht das einzige Mittel um Fehlerbehandlung zu implementieren. Betrachten wir also kurz welche alternativen Möglichkeiten wir denn noch haben.
If Then Else
Die wohl bekannteste Variante der Fehlerbehandlung ist das gute alte if-then-else.
#include <stdio.h> #include <stdlib.h> #include <ctype.h> #include <string.h> void error(char const* msg) { fprintf(stderr, "Ein Fehler ist aufgetreten: '%s'\nDas Programm wird beendet\n", msg); } int print_usage() { if(puts("encode <src> <trg>")<0) { return -1; } else { return 0; } } int encode(char const* srcFileName, char const* trgFileName, char const* password) { FILE* src = NULL; FILE* trg = NULL; size_t pwdPos; size_t pwdLength; int c; int bytesWritten; int returnCode; if(srcFileName == NULL || trgFileName == NULL || password == NULL) { return -1; } src = fopen(srcFileName, "r"); if(src==NULL) { returnCode=-1; goto cleanup; } trg = fopen(trgFileName, "w"); if(trg==NULL) { returnCode=-2; goto cleanup; } pwdPos=0; bytesWritten=0; pwdLength=strlen(password); while( (c=fgetc(src)) != EOF) { int encoded = c ^ password[pwdPos++%pwdLength]; if(fputc(encoded, trg) == EOF) { returnCode=-4; goto cleanup; } ++bytesWritten; } if(!feof(src)) { returnCode=-3; } else if(pwdPos<pwdLength) { returnCode=-5; } else { returnCode=bytesWritten; } cleanup: if(src!=NULL) fclose(src); if(trg!=NULL) fclose(trg); return returnCode; } int main(int argc, char* argv[]) { char password[256]; int res; if(printf("Passwort: ")==-1) { error("Schreibfehler auf stdout"); return -5; } if(!fgets(password, 256, stdin)) { error("Lesefehler von stdin"); return -5; } if(argc!=3) { if(!print_usage()) { return 0; } else { error("Unbekannter Fehler"); return -6; } } res=encode(argv[1], argv[2], password); if(res>0) { return 0; } else { switch(res) { case 0: error("Datei leer"); return -2; case -1: error("Source Datei nicht lesbar"); return -3; case -2: error("Target Datei nicht schreibbar"); return -3; case -3: error("Lesefehler in Source Datei"); return -4; case -4: error("Schreibfehler in Target Datei"); return -4; case -5: /*kein fehler*/ return 0; default: error("Unbekannter Fehler"); return -6; } } }Es gibt 3 Probleme mit diesem Code.
- Die Fehlerbehandlung erfolgt lokal und macht dadurch den Code schwerer lesbar.
- Jede Funktion verlangt andere Behandlung von Fehlern.
- In Sprachen ohne Garbage Collector muss man seinen eigenen Mist selber wegräumen. Dieser Cleanup Code ist kompliziert einzubauen. Hier zB über häßliche gotos gelöst. Alternativ auch mit tief verschachtelten ifs lösbar.
Aber in C macht man es anders
Ihnen als aufmerksamer Leser ist natürlich aufgefallen, dass
encode()hier ein Designproblem hat: Der return Wert beißt sich mit der Fehlerbehandlung. Der Programmierer war versuchtencode()leicht benutzbar zu machen und der Konvention zu folgen die geschriebenen Bytes zu returnen. Wenn Sie Erfahrung mit C APIs haben, werden Sie wissen dass der richtige Weg gewesen wärebytesWrittenals Zeiger der Funktion zu geben. Worauf das aber hinausläuft ist, dass man den Returnwert nur noch als Fehlercode verwenden kann - was vielen Code unpraktisch macht.Deshalb geht man in C den Weg über
errnooder genereller gesagt: eine globale Variable. Der Vorteil ist, dass wir nur einen ungültigen Returnwert definieren müssen, beiencodezB -1 und übererrnokönnten wir dann den genauen Fehler abfragen. So ganz löst das unser Problem aber nicht: denn der Fall dass nach x geschriebenen Bytes ein Fehler auftritt hindert uns daranbytesWrittenals return Wert zu verwenden. Wir haben also durcherrnonicht viel gewonnen. Weiters wirft dererrnoAnsatz ein Problem mit der Erweiterbarkeit auf. Welche Werte verwendet eine neue Funktion für Fehler? Bestehende Werte sollte man lieber nicht doppelt benutzen sonst kommen automatisierte Auswertungstools wie zBstrerror()nicht mehr mit. Unter Windows wird das ganze miterrno,GetLastError(),WSAGetLastError(),... auch noch sehr unübersichtlich.Der PHP4 Ansatz
In PHP4 hat man das zweite Problem sehr schön lösen können und da PHP einen Garbage Collector hat fällt auch dritte Problem weg:
function some_function() { if(something_went_wrong()) { return PEAR::raiseError('something went wrong', MY_ERROR_CODE); } return some_value(); } $var = some_function(); if(PEAR::isError($var)) { do_something(); } else { echo $var; }PHP macht sich zu Nutzen dass jede Variable jeden Typ haben kann. isError erkennt ob
$varvom TypPEAR_Error(oder einer Subklasse davon) ist und liefert dementsprechend true oder false. Dadurch hat man verhindert dass jede Funktion einen anderen Fehlerwert liefert und mit leicht behandelbare Fehlerobjekte lassen sich auch Unterschiedliche Fehler leichter unterschiedlich behandeln.Doch auch das war nicht der Weisheit letzter Schluss, da wir immer noch die Fehler lokal behandeln müssen oder explizit weiter nach unten geben müssen und somit auch wenn wir den Fehler nicht behandeln wollen auf ihn (zumindest mit einem return) reagieren müssen. Wenn wir uns aber als Beispiel eine Anwendung mit Datenbank Anbindung vorstellen und mitten in einem Query wird die Verbindung getrennt, dann brauchen wir eine zentrale Stelle im Code um darauf zu reagieren. Wir wollen nicht an 100.000 verschiedenen Stellen im Code Fehlerbehandlung für eine getrennte Verbindung einbauen, sondern an einer Stelle zentral. Es gibt ja verschiedene Strategien was man in so einem Fall machen kann. Mit der if-then-else Methode muessen wir aber jeden Fehler händisch nach unten geben, bis wir irgendwann an einer Stelle sind wo wir reagieren können.
Was Exceptions bieten
Und einen Punkt wollen wir nicht vergessen, Programmierer sind faul. Fehler die "nie" auftreten muss man nicht behandeln. Wieviel C Code haben sie schon gesehen wo der Erfolg von
printf()überprueft wurde? Das Problem mit Fehlern die nie auftreten können ist jedoch, dass die Hölle los ist, wenn sie doch auftreten.Exceptions bieten hier nun 3 essentielle Punkte an:
- Fehler können dort behandelt werden wo es Sinn macht und müssen nicht (können aber) lokal behandelt werden.
- Fehler kann man nur noch explizit ignorieren.
- Fehlerbehandlung wird vereinheitlicht.
Wie Exceptions generell funktionieren und was try/catch Blöcke sind, haben Sie ja schon in Exception-Handling gelesen. Doch Sie, als aufmerksamer Leser haben natürlich sofort erkannt dass ich Ihnen ein Problem unterschlagen habe: wie verhält es sich mit dem Cleanup Code?
Der finally Block
Viele moderne Sprachen wie zB Java oder C# bieten hier das berüchtigte finally an um dem Problem Herr zu werden:
public void OutputFile(string name) { FileStream fs = null; StreamReader sr = null; try { fs = new FileStream(name, FileMode.Open); sr = new StreamReader(fs); string line; while( (line=sr.ReadLine())!=null ) { Console.WriteLine(line); } } finally { if(sr!=null) sr.Close(); if(fs!=null) fs.Close(); } }Der Vorteil des finally über der if-then-else Methode ist offensichtlich: wir können den Cleanup Code an einer zentralen Stelle lagern und unabhängig wie die Funktion beendet wird, der Code wird ausgeführt. So ganz ideal ist es aber nicht - denn die Variablen müssen im finally Block ja bekannt sein und sie müssen einen Status "uninitialisiert" annehmen können - denn wir wissen ja nicht ob das Objekt schon initialisiert wurde. Der finally Weg ist für Sprachen wie C#/Java durchaus gangbar, denn jedes Objekt ist lediglich eine Referenz und diese Referenz kann auf null Zeigen. In C++ haben wir dieses Feature nicht und wenn wir dem schlechten Beispiel der Standard Library und den Stream Klassen nicht folgen wollen, dann sind unsere Objekte immer in einem initialisierten Zustand. finally fällt für C++ also weg. Aber C++ bietet und ja RAII.
RAII
Ein grundlegendes Problem in C++ ist, dass wir unsere Ressourcen selber freigeben müssen. Meistens, wie zB im Falle
fstream, haben wir Ressourcen bereits in praktische, kleine Klassen gepackt und der Destruktor räumt für uns automatisch auf. Für alle Situationen wo wir diese schöne Kapselung nicht haben, gibt es ScopeGuard. Mit C++0x wird das ganze dank Closures noch einfacher, aber das ist Thema eines anderen Artikels.Genaugenommen ist RAII auch nicht Thema dieses Artikels, aber das RAII-Konzept zeigt sehr schön wie Exception in C++ verwendet werden. Exception Sicherheit basiert auf dem RAII bzw. RRID (Ressource Release Is Destruction) Idiom. Bevor wir deshalb weiter in Exceptions eintauchen, wiederholen wir kurz was RAII/RRID eigentlich ist.
Exceptions in C++ garantieren uns etwas wichtiges: das zerstören aller Objekte die Out Of Scope gehen. Das bedeutet, dass alle notwendigen Destruktoren aufgerufen werden. Die Idee ist nun, den Destruktor die Aufräumarbeit machen zu lassen, da es ihm egal ist warum er aufgerufen wurde. Damit ist man nicht mehr von einem Single-Entry-Single-Exit wie man es aus C her kennt abhängig und kann durchaus auch früher die Funktion beenden, da alle Ressourcen die bis dahin initialisiert wurden durch den Destruktor wieder freigegeben werden.
Natürlich gibt es auch umfangreichere Einführungen in RAII.
Während Java RAII nicht unterstützt bietet C# eine explizite RAII Schreibweise mit Hilfe des using Schlüsselwortes an:
using( File f=new File(filename) ) { //... } //hier wird automatisch f.Dispose() aufgerufenScopeGuard
ScopeGuard ermöglicht es uns das RRID Idiom einzusetzen um Cleanup Code automatisch ausführen zu lassen. Die einfachste Einsatzweise für ScopeGuard ist
ON_BLOCK_EXIT:void writeFile(char const* name, char const* text) { FILE* f=fopen(name, "w"); ON_BLOCK_EXIT(fclose, f); //mit Ende des Blocks wird fclose(f) aufgerufen fprintf(f, "Text: %s\n", text); } void lockedWrite(char const* text) { Mutex m; m.lock(); ON_BLOCK_EXIT(&Mutex::unlock, m); //mit Ende des Blocks wird m.unlock() aufgerufen cout<<text<<endl; }ON_BLOCK_EXITist sehr praktisch wenn man Cleanup Code hat der in keinem Destruktor steht. Natürlich wäre es besser direkt RAII Objekte zu verwenden, aber manchmal ist das unpraktisch und eine Zeile ScopeGuard ist effizienter. Gerade bei dem Mutex Beispiel wäre aber eine vernünftige Mutex Klasse eine bessere Wahl als überall ScopeGuards einzubauen.Ein weiteres wichtiges Feature von ScopeGuard ist das Ermöglichen von Transaktionen:
void clone(LinkedList* src, LinkedList** trg) { LinkedList* temp = create(); ScopeGuard guard = MakeGuard(destroy, temp); do_clone(src, &temp); destroy(*trg); *trg=temp; guard.Dismiss(); }Dismiss()verhindert dass der Cleanup Code ausgeführt wird. Indem wirDismissals letzte Aktion in der Funktion ausführen garantieren wir, dass wenn die Funktion frühzeitig beendet wurde sauber aufgeräumt wird - wenn die Funktion aber bis zum Ende durchläuft nichts zerstört wird.Exception Garantien
In C++ gibt es 3 Arten von Exception Garantien.
- Basic - grundlegende Garantie
- Strong - starke Garantie
- nothrow - keine Exception fliegt Garantie
Nothrow
Der einfachste Fall ist definitiv die nothrow Garantie. Egal was passiert, die Funktion wirft keine Exception und leitet auch keine durch. Die Funktion garantiert also immer erfolgreich zu sein. Ein einfaches Beispiel ist hier zB die Funktion
std::swap(). Idealerweise sollten natürlich alle Funktionen diese Garantie erfüllen, praktisch ist das aber nicht möglich - oder wie wollen Sie garantieren dass jede Netzwerkoperation erfolgreich endet? Funktionen mit der nothrow Garantie sind aber ein essentieller Baustein in Exception sicheren Code - wie und warum, das erfahren Sie gleich.Basic Garantie
Die basic Garantie verlangt dass die Funktion die Daten in konsistenten Zustand hinterlässt (dass dies nicht immer ganz einfach ist werden Sie etwas später erfahren). Was diese Definition uns verschweigt ist, dass ein konsistenter Zustand nicht unbedingt immer der gewünschte Zustand ist. Nehmen wir als Beispiel die Funktion
std::copy(). Es ist klar, dass copy nicht garantieren kann dass jede Kopieroperation erfolgreich sein wird. Was passiert nun, wenn die xte Kopieroperation fehlschlägt? Die Sequenz auf den der out Iterator zeigt enthält x-1 neue Objekte und N-(x-1) alte Objekte. Wichtig dabei ist aber, dass alle Objekte in einem konsistenten Zustand sind.Strong Garantie
Die strong Garantie ist dagegen die Garantie dass ein Rollback stattfindet wenn etwas schief geht. Als Beispiel sehen wir uns std::uninitialized_copy an. Diese Funktion kopiert Daten in uninitialisierten Speicher, sollte ein Kopiervorgang fehlschlagen werden die alten Daten per Destruktor zerstört. Hier kommt die nothrow Garantie dazu - denn jeder Destruktor muss die nothrow Garantie erfüllen (dass dies oft mit Problemen für die Implementierung des Destruktors verbunden ist, sehen wir später). Eben durch diese nothrow Garantie kann
uninitialized_copy()garantieren dass der Rollback erfolgreich ist und somit kann die Funktion die starke Garantie gewährleisten.Einen etwas tieferen Einblick in Exception Garantien bietet Ihnen unter Anderem Bjarne Stroustrup.
Welche Garantie verwenden?
Wie so oft in C++ gibt es auch hier eine einfache Regel um zu bestimmen welche Exception Garantie eine Funktion abgeben soll: die stärkste die moeglich ist. Sollte es möglich sein die nothrow Garantie einhalten zu können - so tun Sie es. nothrow ist das wertvollste was wir aus Exception-Sicherheitstechnischen-Standpunkt her kennen. Aber bedenken Sie auch, die Funktion soll erst ihre Aufgabe erledigen - dann erst die stärkste Garantie abgeben.
std::copy()zum Beispiel wäre mit der starken Garantie implementierbar:template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator target) { typedef vector< typename std::iterator_traits< OutputIterator >::value_type > target_container ; target_container temp(first, last); target_container::iterator i=temp.begin(); target_container::iterator e=temp.end(); while(i!=e) { swap(*i, *target); ++i; ++target; } return target; }Wie Sie aber sehen ist das nicht die effizienteste Art ein copy zu implementieren. Denn wir erstellen N Kopien und swapen diese dann erst an die Zielposition und müssen nachher die Kopien auch wieder zerstören. Deshalb gilt die Regel "eine Funktion soll die stärkste Garantie unterstützen die sie kann, ohne relevante Mehrkosten zu produzieren". Als kleiner Tip sei deshalb gesagt: die meisten Operationen lassen sich per Copy&Swap von der basic auf die strong Garantie upgraden (übrigens nur weil swap und Destruktoren uns ein nothrow garantieren). Wir können so auch aus fast jeder Funktion die die basic Garantie abgibt eine Funktion die die strong Garantie einhält machen:
template<typename Container> void strong_sort(Container& c) { Container temp(c); temp.sort(); swap(c, temp); }Was ich Ihnen hier aber unterschlagen habe ist, dass auch dieses
copy()nicht die strong Garantie liefert. Das Problem liegt in den Iteratoren, die zB istream Iteratoren sein könnten und wenn wir nun die Werte aus einem Stream lesen (zum Beispiel von cin) dann können wir diese Werte nicht mehr ungelesen machen. Die strong Garantie verlangt, dass man nur Funktionen verwendet die reversibel sind.Java/C# und Co
Diese 3 Garantien kann man auch auf Java/C# übertragen. Allerdings sind Operationen wie swap() und Destruktoraufrufe (bzw. eigentlich ja finalizer Aufrufe) in diesen Sprachen sowieso automatisch nothrow. Da nur mit Referenzen hantiert wird, ist swap einfach per Zuweisung implementierbar und da nur Referenzen kopiert werden, kann auch keine Exception fliegen. Man muss in Java/C# deshalb nicht so genau schauen wie in C++, aber die 3 Exception Garantien gelten in Java/C# genauso wie in C++.
Die Implentierung der 3 Garantien
Sie wissen nun warum Exception Sinn machen und welche Garantien eine Funktion in Bezug auf Exception Sicherheit vergeben kann. Sehen wir uns nun aber einmal an wie wir diese Garantien auch durchsetzen können:
Betrachten wir folgende Beispiele:
template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { while(first!=last) { *result=*first; //wenn diese Zuweisung fehlschlägt, wird *result nicht geändert ++first; ++result; } return result; }copyunterstützt die basic Garantie, solange der Zuweisungsoperator des verwendeten Typen diese Garantie ebenfalls unterstützt. Wenn wir dem Zuweisungsoperator nicht trauen können, dann können wir auch keinen Exception Sicheren Code schreiben. Jede Funktion muss deshalb die basic Garantie erfüllen.template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ForwardIterator marker = first; try { while(first!=last) { new (&*first) T(obj); //wenn der Konstruktor fehlschlägt, wird *first nicht geändert ++first; } } catch(...) { //Rollback while(marker!=first) { marker->~T(); //Elemente wieder zerstören ++marker; } throw; //rethrow da wird den Fehler nicht behandeln können } }unitialized_fillunterstützt die strong Garantie und wir brauchen deshalb Rollback Code um im Falle eines Fehlers den Ursprungszustand wiederherstellen zu können. Dank ScopeGuard kann man das aber auch eleganter lösen:template<typename T, typename Function> struct DelayedRangeExecute { private: T startValue; T const* endValue; Function func; public: DelayedRangeExecute(T const& value, Function func) : startValue(value), endValue(&value), func(func) { } void operator()() { while(startValue!=*endValue) { func(*startValue); ++startValue; } } }; template<typename T, typename Function> DelayedRangeExecute<T, Function> makeDelayedRangeExecute(T const& value, Function func) { return DelayedRangeExecute<T, Function>(value, func); } template<typename T> void destroy(T& obj) { obj.~T(); } template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ScopeGuard guard = MakeGuard(makeDelayedRangeExecute(first, destroy)); while(first!=last) { new (&*first) T(obj); ++first; } guard.Dismiss(); }Auf den ersten Blick wirkt der Aufwand für DelayedRangeExecute sehr hoch - aber wenn man bedenkt dass wir
DelayedRangeExecutejetzt überall verwenden können wo wir ein Rollback über eine unbestimmte Iterator Range machen müssen, wirkt es nicht mehr so viel.Ein Beispiel für eine Funktion die die nothrow Garantie unterstützt ersparen wir uns. Denn nothrow Funktionen dürfen nur andere nothrow Funktionen verwenden oder sie müssten Fehler explizit ignorieren.
Arten von Fehlern
In dem Artikel Exception-Handling haben Sie bereits unterschiedliche Fehlerarten kennengelernt. Eine weitere Einteilung ist in Interne Fehler und in Externe Fehler. Externe Fehler sind Fehler die einfach passieren auch wenn Ihr Programm ganz korrekt geschrieben ist. Es kann eine Netzwerkverbindung abbrechen, der Speicherplatz ausgehen, der User nicht die notwendigen Rechte besitzen, etc. Diese Fehler passieren. Man kann sich nicht gegen sie schützen, man kann nur richtig reagieren. Aber es gibt auch noch Interne Fehler wie zB
strlen(NULL). Solche Fehler sollten nicht passieren und sollten in der Release Version alle behoben sein. Interne Fehler sind immer fatale Fehler, da man auf sie nicht richtig reagieren kann. Egal wasstrlen()macht wenn man ihm einen NULL Zeiger gibt, es ist ein falsches Resultat. Man kann natürlich argumentieren dass ein NULL Zeiger die laenge 0 hat - aber wie sieht das ganze mitfopen(NULL, "w")aus? fopen kann nun ebenfalls NULL liefern und sagen die Datei konnte nicht geoeffnet werden, aber warum? Was sagen wir dem User warum wir seine Lieblingsdatei nicht öffnen konnten? Irgendetwas ist schief gelaufen, nie hätte der NULL Zeiger an fopen übergeben werden dürfen.Assert
Um solche Internen von Externen Fehlern getrennt bearbeiten zu können hat C bzw. C++ uns die Möglichkeiten eines
assert()gegeben. assert ist ein Makro dass in der Release Version nichts macht, in der Debug Version aber (je nach Compiler) direkt den Debugger startet und uns zeigt: hier haben wir irgendwo einen Logikfehler versteckt. Das ideale Beispiel für assert ist deroperator[]einer Array Klasse. Zugriffe ausserhalb des Array Bereichs sind Logikfehler die nicht auftreten dürfen - sollte es uns dennoch einmal passieren über den Index hinaus zuzugreifen, springt gleich der Debugger an (sollte das bei Ihnen nicht der Fall sein, führen Sie in einemassertfolgenden Code aus:((*(char*)0)=0)- der Schreibzugriff auf einen NULL Zeiger ruft in der Regel den Debugger auf) und zeigt uns wo wir einen Fehler gemacht haben. Ganz wichtig aber ist es, Externe Fehler nie nie nie nie mit assert zu prüfen, da assert in der Release Version in der Regel abgeschaltet ist.C# und Java bieten auch Asserts an, aber diese Technik ist in diesen beiden Sprachen nicht weit verbreitet. Meistens werden Interne Fehler in mit Exceptions geahndet, was den (je nachdem von welcher Warte man es sieht) Vorteil oder Nachteil hat, dass Interne Fehler ignoriert werden können. Der Vorteil von asserts ist aber, dass man sie überall hinpacken kann da sie in der Release Version keine Performance kosten. Für viele kleine Tests mag das keinen Unterschied machen, aber asserts sind praktisch um Invarianten bzw. Pre/Post Conditions zu testen (was durchaus auch einmal länger dauern kann (Beispielsweise muss ein sortierter Container nach jeder Einfügeoperation immernoch sortiert sein, dies durchzutesten kann aber dauern))
Design By Contract
Ursprünglich stammt die Design By Contract Idee von Bertrand Meyers Programmiersprache Eiffel. Eiffel ist eine der wenigen Sprachen die eine starke Integration von Design By Contract in der Sprache selbst anbieten - aber die Idee hinter diesem Konzept können in alle Sprachen übertragen werden.
Jeder Funktionsaufruf ist genaugenommen nichts anderes als ein Vertragsabschluss zwischen der aufrufenden (caller) und der aufgerufenen (callee) Funktion. Der Caller erfüllt eine handvoll Vorbedingungen (Preconditions) wie zB der string ist 0-terminiert und den Pfad zu einer Datei zu zeigen. Der Callee dagegen garantiert dass eine bestimmte Situation eingetreten bzw. nicht eingetreten ist wenn die Funktion abgeschlossen ist - so zB garantiert fopen die Datei geöffnet zu haben und den Zugriff auf die Datei zu ermöglichen.
Die Theorie besagt, wenn sich alle Caller und Callees an den Vertrag halten, dann ist das Programm Fehlerfrei. Ganz so simpel ist es zwar nicht, aber Design by Contract ermöglicht uns dennoch 2 Fehlerquellen (bis zu einem gewissen Grad) auszuschliessen:
- Logikfehler beim Funktionsaufruf
- Fehler in der Logik der Funktion selbst
Sehen wir uns deshalb einmal etwas Pseudocode an (Vorlage dazu ist std::copy):
template <class InputIterator, class OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { precondition { first<=last && //valid range (result<first || last>result) //result not within [first,last) range //theoretisch fehlt hier die Überprüfung ob result genug Speicher hat //um die ganzen Elemente auch aufzunehmen } while(first!=last) { *result = *first; ++result; ++first; } return result; postcondition { equal(first, last, result) &&//Zugriff auf die originalen Werte return == result + (last-first) } }Wir können durch so einen Code garantieren dass sich Caller und Callee an den Vertrag gehalten haben - dass dabei nicht alle Fehler abgefangen werden ist klar (
[first,last)könnte auf zuviele oder zuwenig Items zeigen, es könnte nur eine flache statt einer tiefen Kopie der Elemente erzeugt werden oder es könnten Ressourcen Leaks entstehen) aber viele Fehler können so gefunden werden.Invarianten
Ein wichtiger Bestandteil von Design by Contract sind sogenannte Invarianten. Invariant wird die Garantie genannt, dass eine Klasse in einem konsisten Zustand ist.
std::mapzB ist ein sortierter, balanzierter Baum.std::mapmuss zu jedem Zeitpunkt sortiert und balanziert sein - dass ist also die Invariante. Invarianten werden immer überprüft nachdem eine öffentliche (public oder protected) Memberfunktion beendet wird. dh, nach jeder Operation wird noch einmal überprüft ob die map wirklich sortiert und balanziert ist. Die Theorie besagt: solange das Objekt in einem konsistenen Zustand ist, kann es zu keinem Fehler kommen. Auch hier ist die Theorie nicht 100% korrekt, aber Invarianten helfen uns logikfehler in Klassen zu finden.Praxis
Ein wichtiger Punkt von Design By Contract ist aber, dass wir diese Tests nur dann durchführen müssen, wenn wir unser Programm testen. In der Release Version müssen diese Tests nicht mehr enthalten sein - dies ermöglicht es uns Tests zu verwenden die sehr viel Zeit in Anspruch nehmen (zB eine map auf sortiertheit und balanziertheit zu testen). Da es sich aber nur um Logik-Fehler handelt die wir abfangen wollen, hat zB ein Vergleich ob eine Datei nun geöffnet werden konnte oder nicht, in den Postconditions wenig verloren.
Warum werden Invarianten nur in public und protected Funktionen aufgerufen? Das liegt daran, dass private Funktionen durchaus den Status des Objektes zerstören dürfen - sofern eine andere Funktion sie wieder herstellt. Als Beispiel nehmen wir wieder unsere Map:
class Map { //... public: void insert(map const& other) { do_insert(other); do_balance(); } }Erst fügen wir alle Elemente sortiert ein und danach balanzieren wir den Baum. do_insert zerstört den konsistenten Zustand des Objektes - aber da wir immer nach einem do_insert ein do_balance aufrufen, ist das kein Problem. Bedingung ist natürlich dass
do_insertunddo_balancenicht von aussen zugänglich sind - denn sonst können wir den konsistenten Zustand nicht mehr garantieren, da wir Niemanden davon abhalten könnendo_insertohnedo_balanceaufzurufen.Die wenigsten Sprachen unterstützen Design by Contract direkt - aber unabhängig ob man im Code direkt per Design By Contract die Validierung einbauen kann oder nicht, es ist meistens sinnvoll die Pre- und Postconditions zu notieren. Mit assert kann man dann zumindest die meisten Preconditions forcieren - um gute Postcondition-Checks schreiben zu können, braucht man aber in der Regel Unterstützung der Sprache (da man ja auf die originalen Werte zugreifen können muss nachdem die Funktion beendet wurde).
Design by Contract Libraries gibt für viele Sprachen, darunter natürlich auch für C++, C# und Java.
Betrand Meyer bietet in einem Interview für Artima einen tieferen Einblick in Design By Contract.
Execption Spezifikationen
Neben den Exception Garantien gibt es auch Exception Spezifikationen. Eine Exception Spezifikation sagt aus, welche Exceptiontypen eine Funktion werfen darf. Im Prinzip nicht viel anders als eine Liste mit erlaubten Error Codes - mit einem kleinen Unterschied: Die Funktion definiert Klassen die sie werfen darf, aber sie darf natürlich auch Subklassen davon werfen. Das ist gegenüber den Returncodes ein erheblicher Vorteil.
Ein weiterer Vorteil von Exception Spezifikationen ist, dass sie Tools ermöglichen die statisch untersuchen können ob alle möglichen geworfenen Exceptions auch gefangen werden.
Checked/Unchecked Exceptions
Java geht sogar einen Schritt weiter und definiert zwei Arten von Exceptions: Checked und Unchecked Exceptions.
Checked Exceptions sind Externe Fehler wie zB die Datei konnte nicht geöffnet werden weil wir die Rechte nicht haben oder die Netzwerkverbindung wurde unterbrochen. Unchecked Exceptions sind dagegen die Fälle bei denen wir in C++ ein assert nehmen würden, nämlich Vertragsverletzungen.
Java verlangt, dass man alle Checked Exceptions abfängt oder explizit weiter wirft. Das bedeutet nun in der Theorie, dass in einem Java Programm kein unerwarteter Externer Fehler auftreten kann, praktisch sieht es aber anders aus. Die Idee der Checked Exceptions ist nicht schlecht - da man damit versucht eben die beiden Arten von Fehlern zu trennen, die wir kennengelernt haben. Aber es gibt an der Umsetzung bzw. am Resultat der Umsetzung durchaus einige Kirtikpunkte:
- Versioning der Funktionen wird schwerer. In den meisten Faellen sind die einzelnen Exceptiontypen nicht so relevant, da man meistens ein catch-all macht, aber Checked Exceptions verbieten es Funktionen nachträglich einen neuen Fehler produzieren zu dürfen.
- Es ist nicht immer leicht für die Programmierer zu entscheiden was jetzt eine Checked Exception sein soll und was nicht. Nehmen wir als Beispiel eine Datenbank Anwendung. Der Abbruch der Verbindung zum Server während eines Queries ist definitiv eine Checked Exception. Doch was wenn wir die Datenbank lokal direkt in die Anwendung integrieren und keine Verbindung zu einem externen Server haben sondern nur ein WriteLock auf eine lokale Datei erstellen? Dann kann die Verbindung nicht mehr abbrechen, wir muessen aber dennoch auf diese Situation die nie eintreten kann reagieren.
- Checked Exceptions verleiten die Programmierer dazu
catch(Exception e){}zu schreiben.
Das bedeutet nicht, dass Checked Exceptions schlecht sind - sie lösen einige Probleme und bringen dafür ein paar andere Probleme ins Spiel. Sehr schön auch in Unchecked Exception - The Controversy oder Does Java need Checked Exceptions dagelegt. Nichtsdestotrotz sind sie ein essentielles Designmittel in Java um den Programmierer auf Fehler hinzuweisen. C++ und C# sowie die meisten Sprachen trennen Exception Typen aber nicht.
Die Implementierung der Exception Spezifikationen in C++, C# und Java sind recht unterschiedlich.
Implementierungen
In Java sind Exception Spezifikationen immer notwendig. Jede Methode muss genau definieren welche Checked Exceptions sie werfen darf. Die Spezifikation von Unchecked Exceptions ist dagegen optional. Wenn eine Methode eine Checked Exception werfen will, die sie laut der Spezifikation nicht werfen darf gibt es einen Compiler Fehler.
In C++ sind alle Exception Spezifikationen optional und da der Check welche Exception geworfen wird und welche geworfen werden dürfen erst zur Laufzeit stattfindet, ist er ziemlich unnütz. Wenn eine unerlaubte Exception geworfen wird, wird die Funktion
std::unexpected()aufgerufen welche im Normalfall eine Exception vom Typstd::bad_exceptionwirft. Da aber, wie gesagt, diese Tests alle zur Laufzeit stattfinden macht es keinen Sinn in C++ Exception Spezifikationen zu verwenden. Es kann vorallem auch gefährlich werden, da eben keine statischen Tests stattfinden, dass falsche Exception Spezifikationen Fehler einführen. Und Fehler die erst zur Laufzeit gefunden werden sind die schwersten zu finden. Einige Compiler, wie zum Beispiel der Microsoft C++ Compiler ignorieren Exception Spezifikationen gleich vollständig.C# geht einen komplett anderen Weg und trennt nicht in Checked/Unchecked Exceptions sondern verbietet jede Art der Exception Spezifikation.
Exception Translation
Oft kommt es vor, dass ein Fehler der aufgetreten ist zu Low-Levelig ist als dass man ihn weiter werfen will. Als Beispiel betrachten wir eine Datenbank Anwendung die alle Tabellen in Dateien ablegt. Bei einem Verbindungsaufbau wird ein WriteLock auf die entsprechende Datenbank Datei gemacht und darauf operiert. Wenn nun diese Datei nicht vorhanden ist, dann fliegt eine
FileNotFoundException. Der Anwender unseres Codes wird sich aber wundern warum einFileNotFoundfliegt, da er ja eigentlich keine Datei öffnen wollte, sondern eine Verbindung zu einer Datenbank. Wir offenbaren unsere Implementationsdetails. Das ist nie gut und wenn wir von Dateien weggehen und stattdessen einen echten Server irgendwo in unser Netzwerk stellen fliegt plötzlich nie wieder eineFileNotFoundException. Um dieses Problem zu lösen verwendet man Exception Translation. Das ist ein hochtrabender Namen für das Umwandeln einer Low Level Exception wieFileNotFoundin eine High Level Exception wieDatabaseConnectionException.Das ganze sieht wenig Spektakulär aus:
try { ConnectToDatabase(); } catch(FileNotFoundException e) { throw new DatabaseConnectionException(); }Exception Chaining
Das Problem bei Exception Propagation ist aber, wir verlieren die Low Level Daten warum die Operation fehlgeschlagen ist. Wir können jedesmal natürlich alle Informationen aus der Low Level Exception rauskitzeln und in die High Level Exception übertragen. Aber es gibt einen einfacheren Weg: Exception Chaining. Exception Chaining erlaubt uns genau diese Umwandlung einer
FileNotFoundExceptionin eineDatabaseConnectionExceptionException ohne Informationsverlust:try { ConnectToDatabase(); } catch(FileNotFoundException cause) { throw new DatabaseConnectionException(cause); }Der Vorteil von Exception Chaining ist der, dass wir uns bis zu der ursprünglichen Exception durchhandeln können und wir selbst durch das umwandeln von Low Level Exceptions in High Level Exceptions keine Information verlieren. Denn eine Exception ist nun nichts andere als ein Knoten in einer einfach verketteten Liste. Wir können problemlos alle Umwandlungsschritte nachvollziehen.
Die C++ Exception Klassen haben dieses Feature nicht eingebaut - auch hat man in C++ das Problem dass man dafür Exceptions kopieren müsste und eine Kopieroperation eine Exception werfen kann.
rethrow
Sie haben gesehen, dass man aus einem catch-Block Problemlos eine Exception werfen kann. Das führt uns zu einem interessanten Punkt: kann man auf einen Fehler reagieren und ihn dann weiter reichen? Es kommt öfters vor, dass man Fehler nicht komplett behandeln kann - meistens kann man nichts tun und nur den Cleanup Code ausführen. Dafür haben wir ja finally bzw. RAII kennengelernt. Manchmal müssen wir aber bei einem Fehler etwas anders reagieren als bei keinem Fehler - der finally Block unterscheidet ja nicht zwischen Fehlerzustand und Normale Beendung der Funktion. Nehmen wir an wir wollen den Fehler loggen:
try { something(); } catch(SpecificException& e) { log(e); throw e; //??? }Hier gibt es 2 Faelle zu Unterscheiden: throw und rethrow. Ein throw wirft eine neue Exception - dh, dass ein eventueller Stacktrace verloren geht oder die Zeilennummer/Datei in der die Exception geworfen wurde wird auf diese aktuelle Zeile gesetzt - wo der Fehler aber nicht auftrat. Ein rethrow erlaubt uns die Exception ohne Änderung weiterzuwerfen. In C++ und C# macht man ein rethrow über ein throw ohne Exception Paramater:
try { something(); } catch(SpecificException& e) { log(e); throw; }In Java dagegen gibt es keinen Unterschied zwischen throw und rethrow - jedes throw von einer bereits geworfenen Exception ist ein rethrow.
Unhandled Exceptions
Wenn wir eine Exception werfen (bzw. weiter werfen) und diese nicht fangen, wird sie zu einer sogenannten Uncaught/Unhandled Exception und unser Programm beendet sich. Auf den 1. Blick sieht es komisch aus, dass es gut sein soll dass keine Ressourcen aufgeraeumt werden, aber es hat durchaus seinen Sinn: Wenn etwas total unerwartetes passiert (und eine Unhandled Exception ist nichts anderes als ein Fehlerfall auf den wir nicht vorbereitet waren - ihn also nicht erwartet haben) dann sollte man die Anwendung so schnell wie möglich beenden. Denn in der Regel kann man sich von solchen Fehlern nicht mehr erholen, da man ja nicht weiss was genau passiert ist. Wenn wir den Fall einmal ausschliessen dass wir einen Fehler gemacht haben und eine Exception die wir fangen hätten sollen durchgelassen haben - dann ist die wahrscheinlichkeit groß, dass Anwendungsinterne Daten korrupt sind. uU haben wir einen Buffer Overflow produziert und irgendwo im RAM stehen ungültige Daten die eben diesen Fehler provoziert haben. In so einer Situation will man die Anwendung so schnell wie möglich beenden und sowenig Code wie möglich ausführen (da man nicht mehr garantieren kann, dass der Code fehlerfrei arbeitet).
Normalerweise haben wir einen globalen try-catch Block wo wir die meisten erwarteten Fehler abfangen, aber unerwartete Exceptions sollte man an das Betriebssystem durchlassen. Das Betriebssystem kann dann einen sehr schönen Crash Report erstellen - etwas das die Anwendung selber nicht kann. Denn das Betriebssystem kann garantiert funktionierenden Code ausführen (was die Anwendung ja nicht mehr kann). Essentielle Ressourcen kann man natürlich selber ruhig noch frei geben - aber jeden Destruktor aufzurufen waere zuviel des guten (denn mit jedem Code den wir ausführen steigt das Risiko noch mehr unerwartetes Verhalten zu produzieren).
Hinter den Kulissen
Betrachten wir uns einmal was hinter den Kulissen vorsich geht. Wie implementieren Compiler diesen Exception Mechanismus? Als Beispiel nehmen wir den VC++ 2005 heran. Mit VC++ 2008 hat sich in Bezug auf Exceptionhandling nichts Grundlegendes verändert, es wurden nur ein paar kleine Optimierungen eingebaut - die Struktur blieb aber gleich.
Sehen wir uns folgenden einfachen Code an:
class Class {}; void do_nothing() { } void might_throw() { if(rand() % 2) { throw SomeException(); } } void two_objects() { Class objA; might_throw(); Class objB; might_throw(); Class objC; } void pass_through() { two_objects(); } void foo() { try { pass_through(); } catch(SomeException& e) { do_nothing(); throw; } } int main() { foo(); }Der Compiler muss im Falle einer Exception genau wissen was er zu tun hat - er muss deshalb irgendwo Informationen haben wo das Programm steht und was es zu tun gibt. Unter Windows 32 Bit ist das ganze per einfach verketteter Liste geloest in der alle Funktionen stehen die im Falle einer Exception etwas tun müssen. Sehen wir uns diese Liste einmal an:
might_throwwirft eine Exception, aber es gibt nichts zu tun. Keine Objekte die zerstört werden müssen und keine catch Blöcke.two_objectsbraucht dagegen einen Eintrag in der Unwind-Liste. Denntwo_objectserstellt Objekte die zerstört werden muss wenn eine Exception fliegt.pass_throughhat keinen Eintrag in der Liste denn egal was passiert,pass_throughleitet die Exception nur weiter ohne selber zu reagieren.foodagegen hat einen catch Block und muss somit Code ausführen wenn eine Exception fliegt. Der catch Block enthält Code um zu überprüfen ob die Exception hier gefangen wird oder durchgelassen wird. Selbst wennfoodie Exception nicht fangen würde, müsste dieser Code dennoch ausgeführt werden.mainist wiepass_throughrecht langweilig.mainCRTStartupist eine magische Funktion der C/C++ Runtime. Hier werden globale Variablen wieerrnoinitialisiert, der Heap angelegt,argc/argvgefüllt, etc. und ebenfalls ein try catch Block ummaingelegt.Jedesmal wenn eine Funktion betreten wird, wird ein Eintrag in der Unwind-Liste gemacht. Da aber einige Funktionen keinen Code haben der abhängig von Exceptions ist, werden diese Funktionen nicht in der Liste eingetragen. Dieser Eintrag kostet natürlich Zeit und Speicher, deshalb optimiert der Compiler wo er nur kann. Static Data enthält Daten zu den jeweiligen Funktionen die den aktuellen Status angeben.
Die interessante Funktion ist
two_objects. Sehen wir unstwo_objectseinmal so an, wie ein sehr naiver Compiler sie implementieren könnte:void two_objects() { //Metadaten //eintrag in Unwind Liste Function this = new Function(); unwindList.add(&this); this.status=0; //objekte anlegen: Class* objA; Class* objB; Class* objC; //Class objA; - objekt initialisieren objA=new Class(); this.status=1; might_throw(); if(exception) goto cleanup; //Class objB; - objekt initialisieren objB=new Class(); this.status=2; might_throw(); if(exception) goto cleanup; //Class objC; - objekt initialisieren objC=new Class(); this.status=3; //aufräumen cleanup: if(this.status==3) { delete objC; this.status=2; } if(this.status==2) { delete objB; this.status=1; } if(this.status==1) { delete objA; this.status=0; } if(this.status==0) { unwindList.remove(&this); delete this; } }Der Cleanup Code wird aus dem "static Data" Block abgeleitet auf den das aktuelle Unwind Element zeigt. Diese status Variable immer auf dem Laufenden zu halten kostet ebenfalls Zeit und wird deshalb nur dann gemacht, wenn es wirklich notwendig ist.
this.status=3;waere in dem obigen Code wegoptimierbar.Unter Windows 64 Bit sieht das ganze schon etwas besser aus. Statt einer Unwind Liste haben wir eine Unwind Map und als Schlüssel verwenden wir den Wert des Instruction Pointers, IP, zu dem Zeitpunkt als die Exception geworfen wird.
Der Vorteil hier liegt auf der Hand: wir haben keine teure Liste die wir pro Funktionsaufruf ändern müssen, wir haben nur eine komplexe Map die wir einmal erstellt haben. Über den IP kann man den aktuellen Status der Funktion (und vorallem auch die Funktion selber in der man sich gerade befindet) herausfinden. Der Nachteil liegt im höherem Aufwand falls eine Exception geworfen wird. Da Exceptions aber nur fliegen wenn sowieso etwas nicht mit rechten Dingen zugeht, ist es durchaus vertretbar - vorallem wenn man dafür den nicht-Exception Pfad deutlich beschleunigen kann.
Das ganze soll nicht vor Exceptions abschrecken - sie sind zwar nicht gratis (aus Performance Sicht) aber man darf nicht vergessen dass ein
if()oder gar ganzeswitch()Orgien bei der if-then-else Fehlerbehandlung auch nicht gerade wenig Zeit kostet.Wenn nun eine Exception geworfen wird, kann die Funktion sich selber dank der status Informationen unwinden - aber wie genau wird der passende catch-Handler gefunden? VC++ geht hier einen 2-Pass Weg, es wird die Unwind Liste also 2 mal durchgegangen.
Beim 1. Pass wird ein passender Exceptionhandler gesucht. Wenn keiner gefunden wird, wird
terminate()aufgerufen welchesabort()aufruft und das Programm beendet. Wenn aber einer gefunden wurde, dann wird der 2. Pass ausgeführt in welchem das Unwinding beginnt.Exkurs: Exceptions in C
Im vorherigen Abschnitt haben wir einen Blick hinter die Kulissen des Exceptionhandlings geworfen. Doch C bzw. C++ wäre nicht C bzw. C++ wenn man das ganze nicht auch händisch implementieren könnte. Einige Exceptionimplementierungen basieren auf genau dem Prinzip das Sie gleich kennen lernen werden. Vorallem im Embedded Bereich wo öfters C++ Exceptions nicht verwendet können werden setzt man öfters C Exceptions ein.
Der Trick hinter Exceptions in C sind die beiden Funktion
setjmp()undlongjmp(), deshalb wird diese Art der Implementierung auch gerne sjlj-Exceptions genannt.setjmpsichert den aktuellen Kontext in einen sogenannten jump Buffer. Der Kontext enthält unter Anderem die auto Variablen am Stack und die Registerwerte.setjmpliefert immer 0 als Ergebnis. Nun verwendet manlongjmpum einen Kontext wiederherzustellen (einschließlich des Instruction Pointers), wir landen mit der Ausführung als wieder in der Zeile in der wirsetjmp()aufgerufen haben.longjmpgeben wir aber einen bestimmten Integer Wert mit und diesen liefertsetjmpuns jetzt - so können wir zwischen den einzelnen Fällen unterscheiden.Da das sehr theoretisch klingt, ein kleines Beispiel:
#include <stdio.h> #include <setjmp.h> #include <assert.h> jmp_buf jbuf; #define E_DIVBYZERO -1 #define E_NOCLEANDIV -2 int divide(int a, int b) { if(b==0) { longjmp(jbuf, E_DIVBYZERO); } if(a%b != 0) { longjmp(jbuf, E_NOCLEANDIV); } return a/b; } int main() { switch(setjmp(jbuf)) { case 0: { int a,b,c; puts("please input an integer"); scanf("%d", &a); puts("please input another integer"); scanf("%d", &b); c=divide(a, b); printf("%d divided by %d gives %d\n", a, b, c); return 0; } case E_DIVBYZERO: { fputs("The integers couldn't be divided, due to a division by zero error.\n", stderr); return -1; } case E_NOCLEANDIV: { fputs("The integers couldn't be divided without a remainder.\n", stderr); return -1; } default: assert(0); } assert(0); }divide()dividiert 2 integer Werte und liefert einen Fehler wenn der Divisor 0 ist oder die Division einen Rest ergibt. Sobald wir eine Fehlersituation individehaben, springen wir mitlongjmpin das switch in main. Dort wird das Ergebnis ausgewertet und der passende Case Zweig angesprungen.Ein Wort der Warnung ist hier aber angebracht: lesen Sie genau in ihrer Compilerdokumentation nach wie sich sjlj in einem C++ Programm verhält. Denn in einem C++ Programm muss der Destruktor von Objekten am Stack ausgeführt werden (etwas das wir uns in C ja sparen können).
Einen etwas tieferen Einblick in sjlj-Exceptions bieten Ihnen Tom Schotland und Peter Petersen.
Exception Safety Testen
Wie können wir garantieren dass unsere Klassen Exception sicher sind? Wir können natürlich den Code stundenlang analysieren und irgendwann sagen: so, jetzt haben wir alle Situationen bedacht. Das ist aber unpraktisch und in der Software Entwicklung lechzen wir nach Automatisierungen.
Unittest: eine komplette Automatisierung ist mir leider nicht bekannt, aber es gibt Techniken die man in seine Unittests einbauen kann. Die Idee ist eine Funktion
mightThrow()in jede Funktion zu packen die eine Exception werfen darf. Einfach ist das ganze wenn wir zB einen Container und ähnliches Testen wollen:class ThrowTestClass { private: int value; public: TestClass(int value=0) : value(value) { mightThrow(); } TestClass(TestClass const& other) : value(other.value) { mightThrow(); } int operator=(TestClass const& other) { this->value = other.value; mightThrow(); } //... }; int main() { std::vector<ThrowTestClass> vec; test(vec); }Die ganze Magie befindet sich in der Funktion mightThrow.
void mightThrow() { if(!throwCounter--) { throw ExceptionSafetyTestException(); } }Wir nehmen eine globale Variable und reduzieren sie immer um 1 wenn
mighThrowaufgerufen wird. WennthrowCounter0 erreicht hat, dann wird eine Exception geworfen. Idealerweise iteriertmightThrowdann durch alle Exceptions die die Funktion werfen darf, meistens ist das aber zuviel des guten und es reicht eine Standard Exception zu werfen. Sehen wir uns dazu jetzt die Testfunktion an:template<class Data, class Test> void basicGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { //nothing } invariants(copy); } } template<class Data, class Test> void strongGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { REQUIRE(copy == data); } invariants(copy); } }Mit Hilfe von Regular Expressions lässt sich die Dokumentation des Codes dazu nutzen die notwendigen throws zu generieren. Dabei wird auf einer Kopie des originalen Source Codes gearbeitet und am Anfang jeder Funktion die Exceptions werfen darf ein
mightThrow()eingefügt.Leider kenne ich keine Unittest Library die das unterstützt - aber vielleicht regt dieser Artikel ja den einen oder anderen an sowas in bestehende Librarys reinzupatchen.
Der Code der Testfunktion sollte leicht verständlich sein, deshalb sehen wir ihn uns nur kurz naeher an.
dataist ein Datenobjekt, zB ein Objekt einer Klasse undtestist ein Objekt dass den Test ausführt. So könntedatazB einstd::vectorsein undtestkönnte den operator= testen. Der throwCounter ist eine globale Variable die bestimmt wann mightThrow eine Exception wirft und anhandfinishederkennen wir, wann keine Exception mehr geworfen wurde (und deshalb der Test beendet ist). Wir arbeiten dabei die ganze Zeit nur auf einer Kopie der echten Daten, da wir ja (zumindest bei der strong Garantie) testen wollen ob der Zustand trotz Exception identisch geblieben ist. Mitinvariants()überprüfen wir zum Schluss ob die Invarianten noch alle stimmen.Interoperability von Exceptions
In C++ leiden wir unter dem Fehlen eines ABI-Standards. Wir können leider nicht garantieren dass eine Exception die ein Binary (zB eine DLL oder SO) verlaesst kompatibel mit den Exceptions in dem Binary ist, dass die Exception fängt. Natürlich ist es möglich diese Kompatibilitaet zu erzwingen und in einigen Situationen macht das auch durchaus Sinn, aber wir sollten nicht davon ausgehen dass dies immer zutrifft. Wir haben in C++ also das Problem, dass wir Exceptions nicht über Binary Grenzen hinweg werfen dürfen. Wir müssen in solchen Situationen zu dem alten if-then Error Handling zurückkehren.
Java und .NET haben dieses Problem nicht, da sie jeweils ein standardisiertes ABI haben und daher das werfen und fangen von Exceptions über Binary Grenzen hinweg kein Problem darstellt.
Exception sicheres Klassen Design
Nach welchen Richtlinien schreibt man denn nun Exception sichere Klassen? Das Paradebeispiel dafür ist eine Stack Klasse wie
std::stack- wobeistd::stackja eigentlich nur ein Container Adapter ist. Eine naive Implementierung einer Stack Klasse könnte so aussehen:template<typename T> class Stack { private: T* data; std::size_t used; std::size_t space; public: explicit Stack(std::size_t expectedElements = 100) : data(static_cast<T*>(operator new(expectedElements*sizeof T))) , used(0) , space(expectedElements) { } Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); } ~Stack() { std::destroy(data, data+used); operator delete(data); } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; } T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; } bool empty() const { return used==0; } std::size_t size() const { return used; } void swap(Stack& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } };Hier gibt es eine Menge Probleme. Gehen wir sie der Reihe nach an:
Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); }Sollte eine Kopieroperation in
std::uninitialized_copyfehlschlagen, so wird der Speicher auf den data zeigt nicht aufgeräumt.void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; }space wird erhöht bevor die Kopieroperationen beendet sind. Sollte new oder
std::copy()fehlschlagen bleibtspaceauf dem erhöhten Wert obwohl keine Erhöhung stattfand.T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; }Sollte eine der beiden Kopieroperation fehlschlagen, geht das Objekt für immer verloren da wir es bereits aus unserem Stack gelöscht haben - es aber nie beim Caller ankam.
Eine elegantere Variante diese Probleme zu umgehen wäre folgende Implementierung:
template<typename T> class StackImpl { public: T* data; std::size_t used; std::size_t space; explicit StackImpl(std::size_t elements) : data(static_cast<T*>(operator new(elements*sizeof T))) , used(0) , space(elements) { } ~StackImpl() { std::destroy(data, data+used); operator delete(data); } void swap(StackImpl& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } private: StackImpl(StackImpl const&); StackImpl& operator=(StackImpl& const); }; template<typename T> class Stack { private: StackImpl<T> impl; public: explicit Stack(std::size_t expectedElements = 100) : impl(expectedElements) { } Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; } void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } bool empty() const { return impl.used==0; } std::size_t size() const { return impl.used; } void swap(Stack& other) { impl.swap(other.impl); } };Da wir eine Hilfsklasse verwenden die das Speichermanagement übernimmt, entstehen im Konstruktor keine Speicherlecks mehr:
Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; }Sollte
std::uninitialized_copyfehlschlagen wird dennoch impl zerstört und der Speicher korrekt freigegeben. Wichtig ist, dassusederst gesetzt wird nachdem das Kopieren erfolgreich war.void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; }Wir verwenden hier das bekannte Copy&Swap um den Speicherbereich zu vergrößern. Wir reduzieren dadurch den nötigen Code und gewinnen Robustheit.
void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; }Ein
pop()dass den gepopten Wert by Value liefert, kann nie Exception Sicher sein. Wir brauchen daher einetop()Methode um an das oberste Element zu gelangen. Nebenbei gewinnen wir dadurch noch die Möglichkeit Stack als ein konstantes Objekt verwenden zu können, da wir nun mittop()an das oberste Element kommen ohne den Stack ändern zu müssen.Design von Exception Klassen
Je nachdem mit welcher Sprache man arbeitet sehen Exceptions immer leicht anders aus. Exceptions können das Debuggen erleichtern wenn sie wichtige Informationen wie Was ist passiert?, Wo ist es passiert? und uU auch ein Warum ist es passiert? mitteilen. Das essentielste davon ist "Was ist passiert?". In der C++ Standard Library über die virtuelle Funktion exception::what() gelöst. Java und C# bieten jeweils noch eine Antwort auf die Frage "wo ist es passiert?" Anhand eines Stack Traces. C++ bietet soetwas nicht eingebaut, aber man kann dennoch an einen Stack Trace gelangen.
Die einfachste Möglichkeit einen Stack Trace zu bekommen ist einen Debugger mitlaufen zu lassen - in der Debug Version während wir noch testen - werden wir das vermutlich sowieso immer machen. Aber wenn wir keinen Debugger mitlaufen lassen haben, können wir die System API verwenden (sofern wir mit Debug Informationen kompiliert haben) oder aber eine fertige Lösung.
Das wichtigste Feature dass Exception Klassen bieten müssen ist eine durchdachte Hierachie. Denn wenn jeder Fehler der erzeugt wir lediglich vom Typ
StandardExceptionist, kann man nur sehr schwer darauf reagieren. Es ist wichtig einen Mittelweg aus zu tiefer Hierachie und zu breiter Hierachie zu finden. Denn wenn wir eine Exception von einer anderen erben lassen muss dies wirklich eine "A ist spezialfall von B"-Situation sein. Oft ist so eine Entscheidung nicht leicht zu treffen: wenn ich eine Datei nicht öffnen kann weil mir die Rechte fehlen, ist das dann eineIOExceptionoder eineSecurityException?Der Konstruktor einer Exceptionklasse darf nie eine Exception erzeugen - denn wir wissen ja: sollte eine Exception auftreten während eine Exception behandelt wird, wird das Programm beendet. Das bedeutet auch, dass man mit Speicherreservierungen vorsichtig sein muss.
Exception Sicherheit ohne try/catch
Der große Vorteil von C++ Exceptions ist RAII. Anstatt überall try/catch schreiben zu müssen, können wir mit RAII die Fehlerfälle meistens sehr gut abfangen ohne sie explizit zu behandeln.
Betrachten wir folgenden Code:
class Class { private: char* name; int* array; public: Class(char const* name) : name(new char[strlen(name)+1]), array(new int[100]) { strcpy(this->name, name); fill(array); } //... };Das Problem ist offensichtlich: wenn eine der beiden Allokationen fehlschlägt, wird die andere nicht mehr rückgängig gemacht. Wir könnten also mit try/catch versuchen das Problem zu lösen:
class Class { private: char* name; int* array; public: Class(char const* name) : name(0), array(0) { try { this->name = new char[strlen(name)+1]; array = new int[100]; } catch(std::bad_alloc& e) { delete [] this->name; delete [] array; throw; } strcpy(this->name, name); fill(array); } //... };Das funktioniert zwar, aber es geht besser:
class Class { private: std::string name; std::vector<int> array; public: Class(char const* name) : name(name), array(100) { fill(array); } //... };Nicht nur dass wir jetzt keine Memory-Leaks mehr haben, wir haben auch noch den Code reduziert und schlanker gemacht. Meistens ist es eine gute Idee dynamische Allokationen in eine Ressourcen Klasse zu stecken, da so nicht nur Fehler verhindert werden sondern der Code auch deutlich einfacher gestaltet bleibt.
Besonders problematisch sind dynamische Allokationen in einem Funktionsaufruf:
foo(new Bar(), new Baz());Mit Smart Pointern wie zB scoped_ptr/auto_ptr oder shared_ptr kann man diese Probleme umgehen indem die Smart Pointer die Ressource verwalten.
Die weite Welt
Exception Handling ist nur eine mögliche Lösung für das komplexe Problem der Fehlerbehandlung. Sie haben in diesem Artikel bereits ein paar Methoden kennengelernt, es gibt aber noch weit mehr. Jede dieser Methoden hat Vorteile und Nachteile, es gibt keine beste Lösung hier.
Error Stack
Jeder Fehler der auftritt wird auf einen bestimmten Stack gesetzt und die Funktion beendet sich selbst. An bestimmten Code Stellen kann man dann auf Fehler testen die ja alle auf diesem Error Stack liegen. Jeder Code kann einen behandelten Fehler vom Stack poppen - man hat somit ein feineres System was Fehlerbehandlung betrifft als wir bei Exceptions haben (wo es nur den Zustand Fehler (Exception wurde geworfen) und nicht Fehler (keine Exception geworfen) gibt.
Deferred Error Handling
iostreammacht es vor: wenn ein Fehler auftritt, dann setzen wir ein internes error-flag und teilen so mit dass etwas schiefgegangen ist.
-
Callbacks
Unter Unix sind Signals recht bekannt, in der Windows-Welt eher nicht. Dennoch bieten Signale eine interessante Möglichkeit Fehler zu handhaben. Jedesmal wenn ein Fehler auftritt wird ein Signal generiert, auf dass eine Anwendung (oder ein Teil einer Anwendung) per Callback reagieren kann indem man das Callback für das entsprechende Signal registriert.
Zu diesen 3 Methoden gibt es unter C++ Exception Alternatives auch ein bisschen Lesestoff wenn Sie mehr erfahren wollen.
Conditions
Nicht jeder Fehler ist ein fataler Fehler. Conditions ermöglichen es an definierten Stellen von einem Fehler zu recovern.
Fehler passieren und egal was wir für eine Methode verwenden um sie zu Handhaben, wir müssen acht geben.
-
Shade Of Mine schrieb:
@Ben04:
Bei dem finalizer stimme ich dir nicht zu.
Der Rest sollte jetzt aber passen.zu dem copy habe ich einen Absatz danach hinzugefuegt - ich denke das passt so ziemlich gut. Es zeigt das Konzept der strong Garantie und weisst gleich auf einen pitfall hin (auf den ich ja selber reingefallen bin).
Mir gefällt die neue Version nicht
std::copy() zum Beispiel wäre mit der starken Garantie implementierbar
Was ich Ihnen hier aber unterschlagen habe ist, dass auch dieses copy() nicht die strong Garantie liefert.
1. Verstehe ich nicht warum du den K2 im ersten Zitat verwendest. Entweder es ist implementierbar oder es ist dies nicht.
2. Widersprichst du dir selbst. Das sollte meiner Meinung nach in einem Artikel nicht vorkommen. (Siehe 2. Zitat)
3. Gibt es auch ostream_iterator und potentiell noch viele mehr.Ich glaube, es wäre besser einfach ein anderes Beispiel zu verwenden oder dich auf das Kopieren von Container zu Container zu beschränken.
bei deinem map artikel geht es nicht um invarianten - ich sehe also nicht viel sinn das zu verlinken. der artikel hat eine komplett andere zielgruppe...
Das stimmt. Ich setze aber ausgiebig assert ein um eine Reihe von Invarianten zu testen, also genau das was du vorschlägst. (Stichwort is_wellformed) Ich dachte es wäre nicht schlecht wenn man den Code als größeres Beispiel zweckentfremden würde.
vertragsverletzungen sollten kein logic_error werfen. das ist der ganze sinn eines vertrags: fehler nicht ignorieren zu koennen. logic_error macht fast nie sinn.
Da gebe ich dir vollkommen recht. Allein die Existenz von logic_error zeigt aber, dass wir mit der Meinung nicht alleine stehen. Es gibt sogar Leute die der Meinung sind assert sollte eine Exception werfen damit der Stack unwinded wird. Deswegen, würde ich dieses Verhalten bei nicht gefangenen Ausnahmen auch nicht als blöde Implementierung abtun. Zu mindest volkard ist/war dieser Meinung.
Da Destruktoren sich ja auch nicht immer nur um die Interna einer Anwendung kümmern, verschlimmert es manchmal den Fehler wenn das Programm einfach abschießt ohne sie auszuführen. Zum Beispiel ein Interprocess-Mutex das nicht mehr geöffnet wird, ein Ausgabestream der nicht geflusht wird, ein Socket das nicht korrekt geschlossen wird und deswegen andere Programme mit sich zieht...
dwarf2 entspricht glaub ich dem was der VC im 64 Bit Modus macht.
worum es mir aber geht ist generell einen ueberblick ueber die technik zu geben und nicht eine genaue beschreibung ueber compiler implementationen
Baue einfach ein meisten/üblich/standard Einstellung/ähnliches Gummiwort ein und es ist auch von einem pedantischem Standpunkt her korrekt.
ja eigentlich nur ein Container Adapter ist
Ich würde hier nochmal kurz erwähnen was ein Container Adapter ist. Ich glaube nicht, dass dies jedem bekannt ist.
-
modernes Exception Handling
In dem Artikel Exception-Handling haben Sie bereits erfahren dass auch der beste Programmierer an Fehler denken muss. Sie haben Exceptions kennengelernt und gesehen wie flexibel diese Ihnen die Arbeit erleichtern können. Doch Exceptions sind nicht nur ein Segen, sondern auch ein Fluch. Bevor wir jedoch die Nachteile von Exception näher betrachten, wollen wir uns die Vorteile ansehen - oder besser: die Alternativen.
Die Alternativen
Exceptions sind nicht das einzige Mittel um Fehlerbehandlung zu implementieren. Betrachten wir also kurz welche alternativen Möglichkeiten wir denn noch haben.
If Then Else
Die wohl bekannteste Variante der Fehlerbehandlung ist das gute alte if-then-else.
#include <stdio.h> #include <stdlib.h> #include <ctype.h> #include <string.h> void error(char const* msg) { fprintf(stderr, "Ein Fehler ist aufgetreten: '%s'\nDas Programm wird beendet\n", msg); } int print_usage() { if(puts("encode <src> <trg>")<0) { return -1; } else { return 0; } } int encode(char const* srcFileName, char const* trgFileName, char const* password) { FILE* src = NULL; FILE* trg = NULL; size_t pwdPos; size_t pwdLength; int c; int bytesWritten; int returnCode; if(srcFileName == NULL || trgFileName == NULL || password == NULL) { return -1; } src = fopen(srcFileName, "r"); if(src==NULL) { returnCode=-1; goto cleanup; } trg = fopen(trgFileName, "w"); if(trg==NULL) { returnCode=-2; goto cleanup; } pwdPos=0; bytesWritten=0; pwdLength=strlen(password); while( (c=fgetc(src)) != EOF) { int encoded = c ^ password[pwdPos++%pwdLength]; if(fputc(encoded, trg) == EOF) { returnCode=-4; goto cleanup; } ++bytesWritten; } if(!feof(src)) { returnCode=-3; } else if(pwdPos<pwdLength) { returnCode=-5; } else { returnCode=bytesWritten; } cleanup: if(src!=NULL) fclose(src); if(trg!=NULL) fclose(trg); return returnCode; } int main(int argc, char* argv[]) { char password[256]; int res; if(printf("Passwort: ")==-1) { error("Schreibfehler auf stdout"); return -5; } if(!fgets(password, 256, stdin)) { error("Lesefehler von stdin"); return -5; } if(argc!=3) { if(!print_usage()) { return 0; } else { error("Unbekannter Fehler"); return -6; } } res=encode(argv[1], argv[2], password); if(res>0) { return 0; } else { switch(res) { case 0: error("Datei leer"); return -2; case -1: error("Source Datei nicht lesbar"); return -3; case -2: error("Target Datei nicht schreibbar"); return -3; case -3: error("Lesefehler in Source Datei"); return -4; case -4: error("Schreibfehler in Target Datei"); return -4; case -5: /*kein fehler*/ return 0; default: error("Unbekannter Fehler"); return -6; } } }Es gibt 3 Probleme mit diesem Code.
- Die Fehlerbehandlung erfolgt lokal und macht dadurch den Code schwerer lesbar.
- Jede Funktion verlangt andere Behandlung von Fehlern.
- In Sprachen ohne Garbage Collector muss man seinen eigenen Mist selber wegräumen. Dieser Cleanup Code ist kompliziert einzubauen. Hier zB über häßliche gotos gelöst. Alternativ auch mit tief verschachtelten ifs lösbar.
Aber in C macht man es anders
Ihnen als aufmerksamer Leser ist natürlich aufgefallen, dass
encode()hier ein Designproblem hat: Der return Wert beißt sich mit der Fehlerbehandlung. Der Programmierer war versuchtencode()leicht benutzbar zu machen und der Konvention zu folgen die geschriebenen Bytes zu returnen. Wenn Sie Erfahrung mit C APIs haben, werden Sie wissen dass der richtige Weg gewesen wärebytesWrittenals Zeiger der Funktion zu geben. Worauf das aber hinausläuft ist, dass man den Returnwert nur noch als Fehlercode verwenden kann - was vielen Code unpraktisch macht.Deshalb geht man in C den Weg über
errnooder genereller gesagt: eine globale Variable. Der Vorteil ist, dass wir nur einen ungültigen Returnwert definieren müssen, beiencodezB -1 und übererrnokönnten wir dann den genauen Fehler abfragen. So ganz löst das unser Problem aber nicht: denn der Fall dass nach x geschriebenen Bytes ein Fehler auftritt hindert uns daranbytesWrittenals return Wert zu verwenden. Wir haben also durcherrnonicht viel gewonnen. Weiters wirft dererrnoAnsatz ein Problem mit der Erweiterbarkeit auf. Welche Werte verwendet eine neue Funktion für Fehler? Bestehende Werte sollte man lieber nicht doppelt benutzen sonst kommen automatisierte Auswertungstools wie zBstrerror()nicht mehr mit. Unter Windows wird das ganze miterrno,GetLastError(),WSAGetLastError(),... auch noch sehr unübersichtlich.Der PHP4 Ansatz
In PHP4 hat man das zweite Problem sehr schön lösen können und da PHP einen Garbage Collector hat fällt auch dritte Problem weg:
function some_function() { if(something_went_wrong()) { return PEAR::raiseError('something went wrong', MY_ERROR_CODE); } return some_value(); } $var = some_function(); if(PEAR::isError($var)) { do_something(); } else { echo $var; }PHP macht sich zu Nutzen dass jede Variable jeden Typ haben kann. isError erkennt ob
$varvom TypPEAR_Error(oder einer Subklasse davon) ist und liefert dementsprechend true oder false. Dadurch hat man verhindert dass jede Funktion einen anderen Fehlerwert liefert und mit leicht behandelbare Fehlerobjekte lassen sich auch Unterschiedliche Fehler leichter unterschiedlich behandeln.Doch auch das war nicht der Weisheit letzter Schluss, da wir immer noch die Fehler lokal behandeln müssen oder explizit weiter nach unten geben müssen und somit auch wenn wir den Fehler nicht behandeln wollen auf ihn (zumindest mit einem return) reagieren müssen. Wenn wir uns aber als Beispiel eine Anwendung mit Datenbank Anbindung vorstellen und mitten in einem Query wird die Verbindung getrennt, dann brauchen wir eine zentrale Stelle im Code um darauf zu reagieren. Wir wollen nicht an 100.000 verschiedenen Stellen im Code Fehlerbehandlung für eine getrennte Verbindung einbauen, sondern an einer Stelle zentral. Es gibt ja verschiedene Strategien was man in so einem Fall machen kann. Mit der if-then-else Methode muessen wir aber jeden Fehler händisch nach unten geben, bis wir irgendwann an einer Stelle sind wo wir reagieren können.
Was Exceptions bieten
Und einen Punkt wollen wir nicht vergessen, Programmierer sind faul. Fehler die "nie" auftreten muss man nicht behandeln. Wieviel C Code haben sie schon gesehen wo der Erfolg von
printf()überprueft wurde? Das Problem mit Fehlern die nie auftreten können ist jedoch, dass die Hölle los ist, wenn sie doch auftreten.Exceptions bieten hier nun 3 essentielle Punkte an:
- Fehler können dort behandelt werden wo es Sinn macht und müssen nicht (können aber) lokal behandelt werden.
- Fehler kann man nur noch explizit ignorieren.
- Fehlerbehandlung wird vereinheitlicht.
Wie Exceptions generell funktionieren und was try/catch Blöcke sind, haben Sie ja schon in Exception-Handling gelesen. Doch Sie, als aufmerksamer Leser haben natürlich sofort erkannt dass ich Ihnen ein Problem unterschlagen habe: wie verhält es sich mit dem Cleanup Code?
Der finally Block
Viele moderne Sprachen wie zB Java oder C# bieten hier das berüchtigte finally an um dem Problem Herr zu werden:
public void OutputFile(string name) { FileStream fs = null; StreamReader sr = null; try { fs = new FileStream(name, FileMode.Open); sr = new StreamReader(fs); string line; while( (line=sr.ReadLine())!=null ) { Console.WriteLine(line); } } finally { if(sr!=null) sr.Close(); if(fs!=null) fs.Close(); } }Der Vorteil des finally über der if-then-else Methode ist offensichtlich: wir können den Cleanup Code an einer zentralen Stelle lagern und unabhängig wie die Funktion beendet wird, der Code wird ausgeführt. So ganz ideal ist es aber nicht - denn die Variablen müssen im finally Block ja bekannt sein und sie müssen einen Status "uninitialisiert" annehmen können - denn wir wissen ja nicht ob das Objekt schon initialisiert wurde. Der finally Weg ist für Sprachen wie C#/Java durchaus gangbar, denn jedes Objekt ist lediglich eine Referenz und diese Referenz kann auf null Zeigen. In C++ haben wir dieses Feature nicht und wenn wir dem schlechten Beispiel der Standard Library und den Stream Klassen nicht folgen wollen, dann sind unsere Objekte immer in einem initialisierten Zustand. finally fällt für C++ also weg. Aber C++ bietet und ja RAII.
RAII
Ein grundlegendes Problem in C++ ist, dass wir unsere Ressourcen selber freigeben müssen. Meistens, wie zB im Falle
fstream, haben wir Ressourcen bereits in praktische, kleine Klassen gepackt und der Destruktor räumt für uns automatisch auf. Für alle Situationen wo wir diese schöne Kapselung nicht haben, gibt es ScopeGuard. Mit C++0x wird das ganze dank Closures noch einfacher, aber das ist Thema eines anderen Artikels.Genaugenommen ist RAII auch nicht Thema dieses Artikels, aber das RAII-Konzept zeigt sehr schön wie Exception in C++ verwendet werden. Exception Sicherheit basiert auf dem RAII bzw. RRID (Ressource Release Is Destruction) Idiom. Bevor wir deshalb weiter in Exceptions eintauchen, wiederholen wir kurz was RAII/RRID eigentlich ist.
Exceptions in C++ garantieren uns etwas wichtiges: das zerstören aller Objekte die Out Of Scope gehen. Das bedeutet, dass alle notwendigen Destruktoren aufgerufen werden. Die Idee ist nun, den Destruktor die Aufräumarbeit machen zu lassen, da es ihm egal ist warum er aufgerufen wurde. Damit ist man nicht mehr von einem Single-Entry-Single-Exit wie man es aus C her kennt abhängig und kann durchaus auch früher die Funktion beenden, da alle Ressourcen die bis dahin initialisiert wurden durch den Destruktor wieder freigegeben werden.
Natürlich gibt es auch umfangreichere Einführungen in RAII.
Während Java RAII nicht unterstützt bietet C# eine explizite RAII Schreibweise mit Hilfe des using Schlüsselwortes an:
using( File f=new File(filename) ) { //... } //hier wird automatisch f.Dispose() aufgerufenScopeGuard
ScopeGuard ermöglicht es uns das RRID Idiom einzusetzen um Cleanup Code automatisch ausführen zu lassen. Die einfachste Einsatzweise für ScopeGuard ist
ON_BLOCK_EXIT:void writeFile(char const* name, char const* text) { FILE* f=fopen(name, "w"); ON_BLOCK_EXIT(fclose, f); //mit Ende des Blocks wird fclose(f) aufgerufen fprintf(f, "Text: %s\n", text); } void lockedWrite(char const* text) { Mutex m; m.lock(); ON_BLOCK_EXIT(&Mutex::unlock, m); //mit Ende des Blocks wird m.unlock() aufgerufen cout<<text<<endl; }ON_BLOCK_EXITist sehr praktisch wenn man Cleanup Code hat der in keinem Destruktor steht. Natürlich wäre es besser direkt RAII Objekte zu verwenden, aber manchmal ist das unpraktisch und eine Zeile ScopeGuard ist effizienter. Gerade bei dem Mutex Beispiel wäre aber eine vernünftige Mutex Klasse eine bessere Wahl als überall ScopeGuards einzubauen.Ein weiteres wichtiges Feature von ScopeGuard ist das Ermöglichen von Transaktionen:
void clone(LinkedList* src, LinkedList** trg) { LinkedList* temp = create(); ScopeGuard guard = MakeGuard(destroy, temp); do_clone(src, &temp); destroy(*trg); *trg=temp; guard.Dismiss(); }Dismiss()verhindert dass der Cleanup Code ausgeführt wird. Indem wirDismissals letzte Aktion in der Funktion ausführen garantieren wir, dass wenn die Funktion frühzeitig beendet wurde sauber aufgeräumt wird - wenn die Funktion aber bis zum Ende durchläuft nichts zerstört wird.Exception Garantien
In C++ gibt es 3 Arten von Exception Garantien.
- Basic - grundlegende Garantie
- Strong - starke Garantie
- nothrow - keine Exception fliegt Garantie
Nothrow
Der einfachste Fall ist definitiv die nothrow Garantie. Egal was passiert, die Funktion wirft keine Exception und leitet auch keine durch. Die Funktion garantiert also immer erfolgreich zu sein. Ein einfaches Beispiel ist hier zB die Funktion
std::swap(). Idealerweise sollten natürlich alle Funktionen diese Garantie erfüllen, praktisch ist das aber nicht möglich - oder wie wollen Sie garantieren dass jede Netzwerkoperation erfolgreich endet? Funktionen mit der nothrow Garantie sind aber ein essentieller Baustein in Exception sicheren Code - wie und warum, das erfahren Sie gleich.Basic Garantie
Die basic Garantie verlangt dass die Funktion die Daten in konsistenten Zustand hinterlässt (dass dies nicht immer ganz einfach ist werden Sie etwas später erfahren). Was diese Definition uns verschweigt ist, dass ein konsistenter Zustand nicht unbedingt immer der gewünschte Zustand ist. Nehmen wir als Beispiel die Funktion
std::copy(). Es ist klar, dass copy nicht garantieren kann dass jede Kopieroperation erfolgreich sein wird. Was passiert nun, wenn die xte Kopieroperation fehlschlägt? Die Sequenz auf den der out Iterator zeigt enthält x-1 neue Objekte und N-(x-1) alte Objekte. Wichtig dabei ist aber, dass alle Objekte in einem konsistenten Zustand sind.Strong Garantie
Die strong Garantie ist dagegen die Garantie dass ein Rollback stattfindet wenn etwas schief geht. Als Beispiel sehen wir uns std::uninitialized_copy an. Diese Funktion kopiert Daten in uninitialisierten Speicher, sollte ein Kopiervorgang fehlschlagen werden die alten Daten per Destruktor zerstört. Hier kommt die nothrow Garantie dazu - denn jeder Destruktor muss die nothrow Garantie erfüllen (dass dies oft mit Problemen für die Implementierung des Destruktors verbunden ist, sehen wir später). Eben durch diese nothrow Garantie kann
uninitialized_copy()garantieren dass der Rollback erfolgreich ist und somit kann die Funktion die starke Garantie gewährleisten.Einen etwas tieferen Einblick in Exception Garantien bietet Ihnen unter Anderem Bjarne Stroustrup.
Welche Garantie verwenden?
Wie so oft in C++ gibt es auch hier eine einfache Regel um zu bestimmen welche Exception Garantie eine Funktion abgeben soll: die stärkste die moeglich ist. Sollte es möglich sein die nothrow Garantie einhalten zu können - so tun Sie es. nothrow ist das wertvollste was wir aus Exception-Sicherheitstechnischen-Standpunkt her kennen. Aber bedenken Sie auch, die Funktion soll erst ihre Aufgabe erledigen - dann erst die stärkste Garantie abgeben.
std::copy()zum Beispiel wäre mit der starken Garantie implementierbar:template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator target) { typedef vector< typename std::iterator_traits< OutputIterator >::value_type > target_container ; target_container temp(first, last); target_container::iterator i=temp.begin(); target_container::iterator e=temp.end(); while(i!=e) { swap(*i, *target); ++i; ++target; } return target; }Wie Sie aber sehen ist das nicht die effizienteste Art ein copy zu implementieren. Denn wir erstellen N Kopien und swapen diese dann erst an die Zielposition und müssen nachher die Kopien auch wieder zerstören. Deshalb gilt die Regel "eine Funktion soll die stärkste Garantie unterstützen die sie kann, ohne relevante Mehrkosten zu produzieren". Als kleiner Tip sei deshalb gesagt: die meisten Operationen lassen sich per Copy&Swap von der basic auf die strong Garantie upgraden (übrigens nur weil swap und Destruktoren uns ein nothrow garantieren). Wir können so auch aus fast jeder Funktion die die basic Garantie abgibt eine Funktion die die strong Garantie einhält machen:
template<typename Container> void strong_sort(Container& c) { Container temp(c); temp.sort(); swap(c, temp); }Was ich Ihnen hier aber unterschlagen habe ist, dass auch dieses
copy()nicht die strong Garantie liefert. Das Problem liegt in den Iteratoren, die zB istream Iteratoren sein könnten und wenn wir nun die Werte aus einem Stream lesen (zum Beispiel von cin) dann können wir diese Werte nicht mehr ungelesen machen. Die strong Garantie verlangt, dass man nur Funktionen verwendet die reversibel sind.Java/C# und Co
Diese 3 Garantien kann man auch auf Java/C# übertragen. Allerdings sind Operationen wie swap() und Destruktoraufrufe (bzw. eigentlich ja finalizer Aufrufe) in diesen Sprachen sowieso automatisch nothrow. Da nur mit Referenzen hantiert wird, ist swap einfach per Zuweisung implementierbar und da nur Referenzen kopiert werden, kann auch keine Exception fliegen. Man muss in Java/C# deshalb nicht so genau schauen wie in C++, aber die 3 Exception Garantien gelten in Java/C# genauso wie in C++.
Die Implentierung der 3 Garantien
Sie wissen nun warum Exception Sinn machen und welche Garantien eine Funktion in Bezug auf Exception Sicherheit vergeben kann. Sehen wir uns nun aber einmal an wie wir diese Garantien auch durchsetzen können:
Betrachten wir folgende Beispiele:
template<typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { while(first!=last) { *result=*first; //wenn diese Zuweisung fehlschlägt, wird *result nicht geändert ++first; ++result; } return result; }copyunterstützt die basic Garantie, solange der Zuweisungsoperator des verwendeten Typen diese Garantie ebenfalls unterstützt. Wenn wir dem Zuweisungsoperator nicht trauen können, dann können wir auch keinen Exception Sicheren Code schreiben. Jede Funktion muss deshalb die basic Garantie erfüllen.template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ForwardIterator marker = first; try { while(first!=last) { new (&*first) T(obj); //wenn der Konstruktor fehlschlägt, wird *first nicht geändert ++first; } } catch(...) { //Rollback while(marker!=first) { marker->~T(); //Elemente wieder zerstören ++marker; } throw; //rethrow da wird den Fehler nicht behandeln können } }unitialized_fillunterstützt die strong Garantie und wir brauchen deshalb Rollback Code um im Falle eines Fehlers den Ursprungszustand wiederherstellen zu können. Dank ScopeGuard kann man das aber auch eleganter lösen:template<typename T, typename Function> struct DelayedRangeExecute { private: T startValue; T const* endValue; Function func; public: DelayedRangeExecute(T const& value, Function func) : startValue(value), endValue(&value), func(func) { } void operator()() { while(startValue!=*endValue) { func(*startValue); ++startValue; } } }; template<typename T, typename Function> DelayedRangeExecute<T, Function> makeDelayedRangeExecute(T const& value, Function func) { return DelayedRangeExecute<T, Function>(value, func); } template<typename T> void destroy(T& obj) { obj.~T(); } template<typename ForwardIterator, typename T> void uninitialized_fill(ForwardIterator first, ForwardIterator last, T const& obj) { ScopeGuard guard = MakeGuard(makeDelayedRangeExecute(first, destroy)); while(first!=last) { new (&*first) T(obj); ++first; } guard.Dismiss(); }Auf den ersten Blick wirkt der Aufwand für DelayedRangeExecute sehr hoch - aber wenn man bedenkt dass wir
DelayedRangeExecutejetzt überall verwenden können wo wir ein Rollback über eine unbestimmte Iterator Range machen müssen, wirkt es nicht mehr so viel.Ein Beispiel für eine Funktion die die nothrow Garantie unterstützt ersparen wir uns. Denn nothrow Funktionen dürfen nur andere nothrow Funktionen verwenden oder sie müssten Fehler explizit ignorieren.
Arten von Fehlern
In dem Artikel Exception-Handling haben Sie bereits unterschiedliche Fehlerarten kennengelernt. Eine weitere Einteilung ist in Interne Fehler und in Externe Fehler. Externe Fehler sind Fehler die einfach passieren auch wenn Ihr Programm ganz korrekt geschrieben ist. Es kann eine Netzwerkverbindung abbrechen, der Speicherplatz ausgehen, der User nicht die notwendigen Rechte besitzen, etc. Diese Fehler passieren. Man kann sich nicht gegen sie schützen, man kann nur richtig reagieren. Aber es gibt auch noch Interne Fehler wie zB
strlen(NULL). Solche Fehler sollten nicht passieren und sollten in der Release Version alle behoben sein. Interne Fehler sind immer fatale Fehler, da man auf sie nicht richtig reagieren kann. Egal wasstrlen()macht wenn man ihm einen NULL Zeiger gibt, es ist ein falsches Resultat. Man kann natürlich argumentieren dass ein NULL Zeiger die laenge 0 hat - aber wie sieht das ganze mitfopen(NULL, "w")aus? fopen kann nun ebenfalls NULL liefern und sagen die Datei konnte nicht geoeffnet werden, aber warum? Was sagen wir dem User warum wir seine Lieblingsdatei nicht öffnen konnten? Irgendetwas ist schief gelaufen, nie hätte der NULL Zeiger an fopen übergeben werden dürfen.Assert
Um solche Internen von Externen Fehlern getrennt bearbeiten zu können hat C bzw. C++ uns die Möglichkeiten eines
assert()gegeben. assert ist ein Makro dass in der Release Version nichts macht, in der Debug Version aber (je nach Compiler) direkt den Debugger startet und uns zeigt: hier haben wir irgendwo einen Logikfehler versteckt. Das ideale Beispiel für assert ist deroperator[]einer Array Klasse. Zugriffe ausserhalb des Array Bereichs sind Logikfehler die nicht auftreten dürfen - sollte es uns dennoch einmal passieren über den Index hinaus zuzugreifen, springt gleich der Debugger an (sollte das bei Ihnen nicht der Fall sein, führen Sie in einemassertfolgenden Code aus:((*(char*)0)=0)- der Schreibzugriff auf einen NULL Zeiger ruft in der Regel den Debugger auf) und zeigt uns wo wir einen Fehler gemacht haben. Ganz wichtig aber ist es, Externe Fehler nie nie nie nie mit assert zu prüfen, da assert in der Release Version in der Regel abgeschaltet ist.C# und Java bieten auch Asserts an, aber diese Technik ist in diesen beiden Sprachen nicht weit verbreitet. Meistens werden Interne Fehler in mit Exceptions geahndet, was den (je nachdem von welcher Warte man es sieht) Vorteil oder Nachteil hat, dass Interne Fehler ignoriert werden können. Der Vorteil von asserts ist aber, dass man sie überall hinpacken kann da sie in der Release Version keine Performance kosten. Für viele kleine Tests mag das keinen Unterschied machen, aber asserts sind praktisch um Invarianten bzw. Pre/Post Conditions zu testen (was durchaus auch einmal länger dauern kann (Beispielsweise muss ein sortierter Container nach jeder Einfügeoperation immernoch sortiert sein, dies durchzutesten kann aber dauern))
Design By Contract
Ursprünglich stammt die Design By Contract Idee von Bertrand Meyers Programmiersprache Eiffel. Eiffel ist eine der wenigen Sprachen die eine starke Integration von Design By Contract in der Sprache selbst anbieten - aber die Idee hinter diesem Konzept können in alle Sprachen übertragen werden.
Jeder Funktionsaufruf ist genaugenommen nichts anderes als ein Vertragsabschluss zwischen der aufrufenden (caller) und der aufgerufenen (callee) Funktion. Der Caller erfüllt eine handvoll Vorbedingungen (Preconditions) wie zB der string ist 0-terminiert und den Pfad zu einer Datei zu zeigen. Der Callee dagegen garantiert dass eine bestimmte Situation eingetreten bzw. nicht eingetreten ist wenn die Funktion abgeschlossen ist - so zB garantiert fopen die Datei geöffnet zu haben und den Zugriff auf die Datei zu ermöglichen.
Die Theorie besagt, wenn sich alle Caller und Callees an den Vertrag halten, dann ist das Programm Fehlerfrei. Ganz so simpel ist es zwar nicht, aber Design by Contract ermöglicht uns dennoch 2 Fehlerquellen (bis zu einem gewissen Grad) auszuschliessen:
- Logikfehler beim Funktionsaufruf
- Fehler in der Logik der Funktion selbst
Sehen wir uns deshalb einmal etwas Pseudocode an (Vorlage dazu ist std::copy):
template <class InputIterator, class OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result) { precondition { first<=last && //valid range (result<first || last>result) //result not within [first,last) range //theoretisch fehlt hier die Überprüfung ob result genug Speicher hat //um die ganzen Elemente auch aufzunehmen } while(first!=last) { *result = *first; ++result; ++first; } return result; postcondition { equal(first, last, result) &&//Zugriff auf die originalen Werte return == result + (last-first) } }Wir können durch so einen Code garantieren dass sich Caller und Callee an den Vertrag gehalten haben - dass dabei nicht alle Fehler abgefangen werden ist klar (
[first,last)könnte auf zuviele oder zuwenig Items zeigen, es könnte nur eine flache statt einer tiefen Kopie der Elemente erzeugt werden oder es könnten Ressourcen Leaks entstehen) aber viele Fehler können so gefunden werden.Invarianten
Ein wichtiger Bestandteil von Design by Contract sind sogenannte Invarianten. Invariant wird die Garantie genannt, dass eine Klasse in einem konsisten Zustand ist.
std::mapzB ist ein sortierter, balanzierter Baum.std::mapmuss zu jedem Zeitpunkt sortiert und balanziert sein - dass ist also die Invariante. Invarianten werden immer überprüft nachdem eine öffentliche (public oder protected) Memberfunktion beendet wird. dh, nach jeder Operation wird noch einmal überprüft ob die map wirklich sortiert und balanziert ist. Die Theorie besagt: solange das Objekt in einem konsistenen Zustand ist, kann es zu keinem Fehler kommen. Auch hier ist die Theorie nicht 100% korrekt, aber Invarianten helfen uns logikfehler in Klassen zu finden.Praxis
Ein wichtiger Punkt von Design By Contract ist aber, dass wir diese Tests nur dann durchführen müssen, wenn wir unser Programm testen. In der Release Version müssen diese Tests nicht mehr enthalten sein - dies ermöglicht es uns Tests zu verwenden die sehr viel Zeit in Anspruch nehmen (zB eine map auf sortiertheit und balanziertheit zu testen). Da es sich aber nur um Logik-Fehler handelt die wir abfangen wollen, hat zB ein Vergleich ob eine Datei nun geöffnet werden konnte oder nicht, in den Postconditions wenig verloren.
Warum werden Invarianten nur in public und protected Funktionen aufgerufen? Das liegt daran, dass private Funktionen durchaus den Status des Objektes zerstören dürfen - sofern eine andere Funktion sie wieder herstellt. Als Beispiel nehmen wir wieder unsere Map:
class Map { //... public: void insert(map const& other) { do_insert(other); do_balance(); } }Erst fügen wir alle Elemente sortiert ein und danach balanzieren wir den Baum. do_insert zerstört den konsistenten Zustand des Objektes - aber da wir immer nach einem do_insert ein do_balance aufrufen, ist das kein Problem. Bedingung ist natürlich dass
do_insertunddo_balancenicht von aussen zugänglich sind - denn sonst können wir den konsistenten Zustand nicht mehr garantieren, da wir Niemanden davon abhalten könnendo_insertohnedo_balanceaufzurufen.Die wenigsten Sprachen unterstützen Design by Contract direkt - aber unabhängig ob man im Code direkt per Design By Contract die Validierung einbauen kann oder nicht, es ist meistens sinnvoll die Pre- und Postconditions zu notieren. Mit assert kann man dann zumindest die meisten Preconditions forcieren - um gute Postcondition-Checks schreiben zu können, braucht man aber in der Regel Unterstützung der Sprache (da man ja auf die originalen Werte zugreifen können muss nachdem die Funktion beendet wurde).
Design by Contract Libraries gibt für viele Sprachen, darunter natürlich auch für C++, C# und Java. Für die Implementierung von Invarianten bietet C# eine interessante Möglichkeit anhand von Conditional.
Betrand Meyer bietet in einem Interview für Artima einen tieferen Einblick in Design By Contract.
Execption Spezifikationen
Neben den Exception Garantien gibt es auch Exception Spezifikationen. Eine Exception Spezifikation sagt aus, welche Exceptiontypen eine Funktion werfen darf. Im Prinzip nicht viel anders als eine Liste mit erlaubten Error Codes - mit einem kleinen Unterschied: Die Funktion definiert Klassen die sie werfen darf, aber sie darf natürlich auch Subklassen davon werfen. Das ist gegenüber den Returncodes ein erheblicher Vorteil.
Ein weiterer Vorteil von Exception Spezifikationen ist, dass sie Tools ermöglichen die statisch untersuchen können ob alle möglichen geworfenen Exceptions auch gefangen werden.
Checked/Unchecked Exceptions
Java geht sogar einen Schritt weiter und definiert zwei Arten von Exceptions: Checked und Unchecked Exceptions.
Checked Exceptions sind Externe Fehler wie zB die Datei konnte nicht geöffnet werden weil wir die Rechte nicht haben oder die Netzwerkverbindung wurde unterbrochen. Unchecked Exceptions sind dagegen die Fälle bei denen wir in C++ ein assert (oder manche auch lieber eine std::logic_error Exception) nehmen würden, nämlich Vertragsverletzungen.
Java verlangt, dass man alle Checked Exceptions abfängt oder explizit weiter wirft. Das bedeutet nun in der Theorie, dass in einem Java Programm kein unerwarteter Externer Fehler auftreten kann, praktisch sieht es aber anders aus. Die Idee der Checked Exceptions ist nicht schlecht - da man damit versucht eben die beiden Arten von Fehlern zu trennen, die wir kennengelernt haben. Aber es gibt an der Umsetzung bzw. am Resultat der Umsetzung durchaus einige Kirtikpunkte:
- Versioning der Funktionen wird schwerer. In den meisten Faellen sind die einzelnen Exceptiontypen nicht so relevant, da man meistens ein catch-all macht, aber Checked Exceptions verbieten es Funktionen nachträglich einen neuen Fehler produzieren zu dürfen.
- Es ist nicht immer leicht für die Programmierer zu entscheiden was jetzt eine Checked Exception sein soll und was nicht. Nehmen wir als Beispiel eine Datenbank Anwendung. Der Abbruch der Verbindung zum Server während eines Queries ist definitiv eine Checked Exception. Doch was wenn wir die Datenbank lokal direkt in die Anwendung integrieren und keine Verbindung zu einem externen Server haben sondern nur ein WriteLock auf eine lokale Datei erstellen? Dann kann die Verbindung nicht mehr abbrechen, wir muessen aber dennoch auf diese Situation die nie eintreten kann reagieren.
- Checked Exceptions verleiten die Programmierer dazu
catch(Exception e){}zu schreiben.
Das bedeutet nicht, dass Checked Exceptions schlecht sind - sie lösen einige Probleme und bringen dafür ein paar andere Probleme ins Spiel. Sehr schön auch in Unchecked Exception - The Controversy oder Does Java need Checked Exceptions dagelegt. Nichtsdestotrotz sind sie ein essentielles Designmittel in Java um den Programmierer auf Fehler hinzuweisen. C++ und C# sowie die meisten Sprachen trennen Exception Typen aber nicht.
Die Implementierung der Exception Spezifikationen in C++, C# und Java sind recht unterschiedlich.
Implementierungen
In Java sind Exception Spezifikationen immer notwendig. Jede Methode muss genau definieren welche Checked Exceptions sie werfen darf. Die Spezifikation von Unchecked Exceptions ist dagegen optional. Wenn eine Methode eine Checked Exception werfen will, die sie laut der Spezifikation nicht werfen darf gibt es einen Compiler Fehler.
In C++ sind alle Exception Spezifikationen optional und da der Check welche Exception geworfen wird und welche geworfen werden dürfen erst zur Laufzeit stattfindet, ist er ziemlich unnütz. Wenn eine unerlaubte Exception geworfen wird, wird die Funktion
std::unexpected()aufgerufen welche im Normalfall eine Exception vom Typstd::bad_exceptionwirft. Da aber, wie gesagt, diese Tests alle zur Laufzeit stattfinden macht es keinen Sinn in C++ Exception Spezifikationen zu verwenden. Es kann vorallem auch gefährlich werden, da eben keine statischen Tests stattfinden, dass falsche Exception Spezifikationen Fehler einführen. Und Fehler die erst zur Laufzeit gefunden werden sind die schwersten zu finden. Einige Compiler, wie zum Beispiel der Microsoft C++ Compiler ignorieren Exception Spezifikationen gleich vollständig.C# geht einen komplett anderen Weg und trennt nicht in Checked/Unchecked Exceptions sondern verbietet jede Art der Exception Spezifikation.
Exception Translation
Oft kommt es vor, dass ein Fehler der aufgetreten ist zu Low-Levelig ist als dass man ihn weiter werfen will. Als Beispiel betrachten wir eine Datenbank Anwendung die alle Tabellen in Dateien ablegt. Bei einem Verbindungsaufbau wird ein WriteLock auf die entsprechende Datenbank Datei gemacht und darauf operiert. Wenn nun diese Datei nicht vorhanden ist, dann fliegt eine
FileNotFoundException. Der Anwender unseres Codes wird sich aber wundern warum einFileNotFoundfliegt, da er ja eigentlich keine Datei öffnen wollte, sondern eine Verbindung zu einer Datenbank. Wir offenbaren unsere Implementationsdetails. Das ist nie gut und wenn wir von Dateien weggehen und stattdessen einen echten Server irgendwo in unser Netzwerk stellen fliegt plötzlich nie wieder eineFileNotFoundException. Um dieses Problem zu lösen verwendet man Exception Translation. Das ist ein hochtrabender Namen für das Umwandeln einer Low Level Exception wieFileNotFoundin eine High Level Exception wieDatabaseConnectionException.Das ganze sieht wenig Spektakulär aus:
try { ConnectToDatabase(); } catch(FileNotFoundException e) { throw new DatabaseConnectionException(); }Exception Chaining
Das Problem bei Exception Propagation ist aber, wir verlieren die Low Level Daten warum die Operation fehlgeschlagen ist. Wir können jedesmal natürlich alle Informationen aus der Low Level Exception rauskitzeln und in die High Level Exception übertragen. Aber es gibt einen einfacheren Weg: Exception Chaining. Exception Chaining erlaubt uns genau diese Umwandlung einer
FileNotFoundExceptionin eineDatabaseConnectionExceptionException ohne Informationsverlust:try { ConnectToDatabase(); } catch(FileNotFoundException cause) { throw new DatabaseConnectionException(cause); }Der Vorteil von Exception Chaining ist der, dass wir uns bis zu der ursprünglichen Exception durchhandeln können und wir selbst durch das umwandeln von Low Level Exceptions in High Level Exceptions keine Information verlieren. Denn eine Exception ist nun nichts andere als ein Knoten in einer einfach verketteten Liste. Wir können problemlos alle Umwandlungsschritte nachvollziehen.
Die C++ Exception Klassen haben dieses Feature nicht eingebaut - auch hat man in C++ das Problem dass man dafür Exceptions kopieren müsste und eine Kopieroperation eine Exception werfen kann.
rethrow
Sie haben gesehen, dass man aus einem catch-Block Problemlos eine Exception werfen kann. Das führt uns zu einem interessanten Punkt: kann man auf einen Fehler reagieren und ihn dann weiter reichen? Es kommt öfters vor, dass man Fehler nicht komplett behandeln kann - meistens kann man nichts tun und nur den Cleanup Code ausführen. Dafür haben wir ja finally bzw. RAII kennengelernt. Manchmal müssen wir aber bei einem Fehler etwas anders reagieren als bei keinem Fehler - der finally Block unterscheidet ja nicht zwischen Fehlerzustand und Normale Beendung der Funktion. Nehmen wir an wir wollen den Fehler loggen:
try { something(); } catch(SpecificException& e) { log(e); throw e; //??? }Hier gibt es 2 Faelle zu Unterscheiden: throw und rethrow. Ein throw wirft eine neue Exception - dh, dass ein eventueller Stacktrace verloren geht oder die Zeilennummer/Datei in der die Exception geworfen wurde wird auf diese aktuelle Zeile gesetzt - wo der Fehler aber nicht auftrat. Ein rethrow erlaubt uns die Exception ohne Änderung weiterzuwerfen. In C++ und C# macht man ein rethrow über ein throw ohne Exception Paramater:
try { something(); } catch(SpecificException& e) { log(e); throw; }In Java dagegen gibt es keinen Unterschied zwischen throw und rethrow - jedes throw von einer bereits geworfenen Exception ist ein rethrow.
Unhandled Exceptions
Wenn wir eine Exception werfen (bzw. weiter werfen) und diese nicht fangen, wird sie zu einer sogenannten Uncaught/Unhandled Exception und unser Programm beendet sich. Der C++ Standard definiert nicht, ob in so einem Fall der Stack aufgeräumt (alle Ressourcen korrekt zerstört werden sollen) oder das Programm sofort beendet werden soll. Auf den 1. Blick sieht es komisch aus, dass es gut sein soll dass keine Ressourcen aufgeraeumt werden, aber das ist genau das Richtige in dieser Situation: Wenn etwas total unerwartetes passiert (und eine Unhandled Exception ist nichts anderes als ein Fehlerfall auf den wir nicht vorbereitet waren - ihn also nicht erwartet haben) dann sollte man die Anwendung so schnell wie möglich beenden. Denn in der Regel kann man sich von solchen Fehlern nicht mehr erholen, da man ja nicht weiss was genau passiert ist. Wenn wir den Fall einmal ausschliessen dass wir einen Fehler gemacht haben und eine Exception die wir fangen hätten sollen durchgelassen haben - dann ist die wahrscheinlichkeit groß, dass Anwendungsinterne Daten korrupt sind. uU haben wir einen Buffer Overflow produziert und irgendwo im RAM stehen ungültige Daten die eben diesen Fehler provoziert haben. In so einer Situation will man die Anwendung so schnell wie möglich beenden und sowenig Code wie möglich ausführen (da man nicht mehr garantieren kann, dass der Code fehlerfrei arbeitet).
Normalerweise haben wir einen globalen try-catch Block wo wir die meisten erwarteten Fehler abfangen, aber unerwartete Exceptions sollte man an das Betriebssystem durchlassen. Das Betriebssystem kann dann einen sehr schönen Crash Report erstellen - etwas das die Anwendung selber nicht kann. Denn das Betriebssystem kann garantiert funktionierenden Code ausführen (was die Anwendung ja nicht mehr kann). Essentielle Ressourcen kann man natürlich selber ruhig noch frei geben - aber jeden Destruktor aufzurufen waere zuviel des guten (denn mit jedem Code den wir ausführen steigt das Risiko noch mehr unerwartetes Verhalten zu produzieren).
Hinter den Kulissen
Betrachten wir uns einmal was hinter den Kulissen vorsich geht. Wie implementieren Compiler diesen Exception Mechanismus? Als Beispiel nehmen wir den VC++ 2005 heran. Mit VC++ 2008 hat sich in Bezug auf Exceptionhandling nichts Grundlegendes verändert, es wurden nur ein paar kleine Optimierungen eingebaut - die Struktur blieb aber gleich.
Sehen wir uns folgenden einfachen Code an:
class Class {}; void do_nothing() { } void might_throw() { if(rand() % 2) { throw SomeException(); } } void two_objects() { Class objA; might_throw(); Class objB; might_throw(); Class objC; } void pass_through() { two_objects(); } void foo() { try { pass_through(); } catch(SomeException& e) { do_nothing(); throw; } } int main() { foo(); }Der Compiler muss im Falle einer Exception genau wissen was er zu tun hat - er muss deshalb irgendwo Informationen haben wo das Programm steht und was es zu tun gibt. Unter Windows 32 Bit ist das ganze per einfach verketteter Liste geloest in der alle Funktionen stehen die im Falle einer Exception etwas tun müssen. Sehen wir uns diese Liste einmal an:
might_throwwirft eine Exception, aber es gibt nichts zu tun. Keine Objekte die zerstört werden müssen und keine catch Blöcke.two_objectsbraucht dagegen einen Eintrag in der Unwind-Liste. Denntwo_objectserstellt Objekte die zerstört werden muss wenn eine Exception fliegt.pass_throughhat keinen Eintrag in der Liste denn egal was passiert,pass_throughleitet die Exception nur weiter ohne selber zu reagieren.foodagegen hat einen catch Block und muss somit Code ausführen wenn eine Exception fliegt. Der catch Block enthält Code um zu überprüfen ob die Exception hier gefangen wird oder durchgelassen wird. Selbst wennfoodie Exception nicht fangen würde, müsste dieser Code dennoch ausgeführt werden.mainist wiepass_throughrecht langweilig.mainCRTStartupist eine magische Funktion der C/C++ Runtime. Hier werden globale Variablen wieerrnoinitialisiert, der Heap angelegt,argc/argvgefüllt, etc. und ebenfalls ein try catch Block ummaingelegt.Jedesmal wenn eine Funktion betreten wird, wird ein Eintrag in der Unwind-Liste gemacht. Da aber einige Funktionen keinen Code haben der abhängig von Exceptions ist, werden diese Funktionen nicht in der Liste eingetragen. Dieser Eintrag kostet natürlich Zeit und Speicher, deshalb optimiert der Compiler wo er nur kann. Static Data enthält Daten zu den jeweiligen Funktionen die den aktuellen Status angeben.
Die interessante Funktion ist
two_objects. Sehen wir unstwo_objectseinmal so an, wie ein sehr naiver Compiler sie implementieren könnte:void two_objects() { //Metadaten //eintrag in Unwind Liste Function this = new Function(); unwindList.add(&this); this.status=0; //objekte anlegen: Class* objA; Class* objB; Class* objC; //Class objA; - objekt initialisieren objA=new Class(); this.status=1; might_throw(); if(exception) goto cleanup; //Class objB; - objekt initialisieren objB=new Class(); this.status=2; might_throw(); if(exception) goto cleanup; //Class objC; - objekt initialisieren objC=new Class(); this.status=3; //aufräumen cleanup: if(this.status==3) { delete objC; this.status=2; } if(this.status==2) { delete objB; this.status=1; } if(this.status==1) { delete objA; this.status=0; } if(this.status==0) { unwindList.remove(&this); delete this; } }Der Cleanup Code wird aus dem "static Data" Block abgeleitet auf den das aktuelle Unwind Element zeigt. Diese status Variable immer auf dem Laufenden zu halten kostet ebenfalls Zeit und wird deshalb nur dann gemacht, wenn es wirklich notwendig ist.
this.status=3;waere in dem obigen Code wegoptimierbar.Unter Windows 64 Bit sieht das ganze schon etwas besser aus. Statt einer Unwind Liste haben wir eine Unwind Map und als Schlüssel verwenden wir den Wert des Instruction Pointers, IP, zu dem Zeitpunkt als die Exception geworfen wird.
Der Vorteil hier liegt auf der Hand: wir haben keine teure Liste die wir pro Funktionsaufruf ändern müssen, wir haben nur eine komplexe Map die wir einmal erstellt haben. Über den IP kann man den aktuellen Status der Funktion (und vorallem auch die Funktion selber in der man sich gerade befindet) herausfinden. Der Nachteil liegt im höherem Aufwand falls eine Exception geworfen wird. Da Exceptions aber nur fliegen wenn sowieso etwas nicht mit rechten Dingen zugeht, ist es durchaus vertretbar - vorallem wenn man dafür den nicht-Exception Pfad deutlich beschleunigen kann.
Das ganze soll nicht vor Exceptions abschrecken - sie sind zwar nicht gratis (aus Performance Sicht) aber man darf nicht vergessen dass ein
if()oder gar ganzeswitch()Orgien bei der if-then-else Fehlerbehandlung auch nicht gerade wenig Zeit kostet.Wenn nun eine Exception geworfen wird, kann die Funktion sich selber dank der status Informationen unwinden - aber wie genau wird der passende catch-Handler gefunden? VC++ geht hier einen 2-Pass Weg, es wird die Unwind Liste also 2 mal durchgegangen.
Beim 1. Pass wird ein passender Exceptionhandler gesucht. Wenn keiner gefunden wird, wird
terminate()aufgerufen welchesabort()aufruft und das Programm beendet. Wenn aber einer gefunden wurde, dann wird der 2. Pass ausgeführt in welchem das Unwinding beginnt.Exkurs: Exceptions in C
Im vorherigen Abschnitt haben wir einen Blick hinter die Kulissen des Exceptionhandlings geworfen. Doch C bzw. C++ wäre nicht C bzw. C++ wenn man das ganze nicht auch händisch implementieren könnte. Einige Exceptionimplementierungen basieren auf genau dem Prinzip das Sie gleich kennen lernen werden. Vorallem im Embedded Bereich wo öfters C++ Exceptions nicht verwendet können werden setzt man öfters C Exceptions ein.
Der Trick hinter Exceptions in C sind die beiden Funktion
setjmp()undlongjmp(), deshalb wird diese Art der Implementierung auch gerne sjlj-Exceptions genannt.setjmpsichert den aktuellen Kontext in einen sogenannten jump Buffer. Der Kontext enthält unter Anderem die auto Variablen am Stack und die Registerwerte.setjmpliefert immer 0 als Ergebnis. Nun verwendet manlongjmpum einen Kontext wiederherzustellen (einschließlich des Instruction Pointers), wir landen mit der Ausführung als wieder in der Zeile in der wirsetjmp()aufgerufen haben.longjmpgeben wir aber einen bestimmten Integer Wert mit und diesen liefertsetjmpuns jetzt - so können wir zwischen den einzelnen Fällen unterscheiden.Da das sehr theoretisch klingt, ein kleines Beispiel:
#include <stdio.h> #include <setjmp.h> #include <assert.h> jmp_buf jbuf; #define E_DIVBYZERO -1 #define E_NOCLEANDIV -2 int divide(int a, int b) { if(b==0) { longjmp(jbuf, E_DIVBYZERO); } if(a%b != 0) { longjmp(jbuf, E_NOCLEANDIV); } return a/b; } int main() { switch(setjmp(jbuf)) { case 0: { int a,b,c; puts("please input an integer"); scanf("%d", &a); puts("please input another integer"); scanf("%d", &b); c=divide(a, b); printf("%d divided by %d gives %d\n", a, b, c); return 0; } case E_DIVBYZERO: { fputs("The integers couldn't be divided, due to a division by zero error.\n", stderr); return -1; } case E_NOCLEANDIV: { fputs("The integers couldn't be divided without a remainder.\n", stderr); return -1; } default: assert(0); } assert(0); }divide()dividiert 2 integer Werte und liefert einen Fehler wenn der Divisor 0 ist oder die Division einen Rest ergibt. Sobald wir eine Fehlersituation individehaben, springen wir mitlongjmpin das switch in main. Dort wird das Ergebnis ausgewertet und der passende Case Zweig angesprungen.Ein Wort der Warnung ist hier aber angebracht: lesen Sie genau in ihrer Compilerdokumentation nach wie sich sjlj in einem C++ Programm verhält. Denn in einem C++ Programm muss der Destruktor von Objekten am Stack ausgeführt werden (etwas das wir uns in C ja sparen können).
Einen etwas tieferen Einblick in sjlj-Exceptions bieten Ihnen Tom Schotland und Peter Petersen.
Exception Safety Testen
Wie können wir garantieren dass unsere Klassen Exception sicher sind? Wir können natürlich den Code stundenlang analysieren und irgendwann sagen: so, jetzt haben wir alle Situationen bedacht. Das ist aber unpraktisch und in der Software Entwicklung lechzen wir nach Automatisierungen.
Unittest: eine komplette Automatisierung ist mir leider nicht bekannt, aber es gibt Techniken die man in seine Unittests einbauen kann. Die Idee ist eine Funktion
mightThrow()in jede Funktion zu packen die eine Exception werfen darf. Einfach ist das ganze wenn wir zB einen Container und ähnliches Testen wollen:class ThrowTestClass { private: int value; public: TestClass(int value=0) : value(value) { mightThrow(); } TestClass(TestClass const& other) : value(other.value) { mightThrow(); } int operator=(TestClass const& other) { this->value = other.value; mightThrow(); } //... }; int main() { std::vector<ThrowTestClass> vec; test(vec); }Die ganze Magie befindet sich in der Funktion mightThrow.
void mightThrow() { if(!throwCounter--) { throw ExceptionSafetyTestException(); } }Wir nehmen eine globale Variable und reduzieren sie immer um 1 wenn
mighThrowaufgerufen wird. WennthrowCounter0 erreicht hat, dann wird eine Exception geworfen. Idealerweise iteriertmightThrowdann durch alle Exceptions die die Funktion werfen darf, meistens ist das aber zuviel des guten und es reicht eine Standard Exception zu werfen. Sehen wir uns dazu jetzt die Testfunktion an:template<class Data, class Test> void basicGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { //nothing } invariants(copy); } } template<class Data, class Test> void strongGuaranteeCheck(Data& data, Test const& test) { bool finished=false; for(int nextThrowCounter=0; !finished; ++nextThrowCounter) { Data copy(data); throwCounter = nextThrowCounter; try { test.test(copy); finished=true; } catch(ExceptionSafetyTestException& e) { REQUIRE(copy == data); } invariants(copy); } }Mit Hilfe von Regular Expressions lässt sich die Dokumentation des Codes dazu nutzen die notwendigen throws zu generieren. Dabei wird auf einer Kopie des originalen Source Codes gearbeitet und am Anfang jeder Funktion die Exceptions werfen darf ein
mightThrow()eingefügt.Leider kenne ich keine Unittest Library die das unterstützt - aber vielleicht regt dieser Artikel ja den einen oder anderen an sowas in bestehende Librarys reinzupatchen.
Der Code der Testfunktion sollte leicht verständlich sein, deshalb sehen wir ihn uns nur kurz naeher an.
dataist ein Datenobjekt, zB ein Objekt einer Klasse undtestist ein Objekt dass den Test ausführt. So könntedatazB einstd::vectorsein undtestkönnte den operator= testen. Der throwCounter ist eine globale Variable die bestimmt wann mightThrow eine Exception wirft und anhandfinishederkennen wir, wann keine Exception mehr geworfen wurde (und deshalb der Test beendet ist). Wir arbeiten dabei die ganze Zeit nur auf einer Kopie der echten Daten, da wir ja (zumindest bei der strong Garantie) testen wollen ob der Zustand trotz Exception identisch geblieben ist. Mitinvariants()überprüfen wir zum Schluss ob die Invarianten noch alle stimmen.Interoperability von Exceptions
In C++ leiden wir unter dem Fehlen eines ABI-Standards. Wir können leider nicht garantieren dass eine Exception die ein Binary (zB eine DLL oder SO) verlaesst kompatibel mit den Exceptions in dem Binary ist, dass die Exception fängt. Natürlich ist es möglich diese Kompatibilitaet zu erzwingen und in einigen Situationen macht das auch durchaus Sinn, aber wir sollten nicht davon ausgehen dass dies immer zutrifft. Wir haben in C++ also das Problem, dass wir Exceptions nicht über Binary Grenzen hinweg werfen dürfen. Wir müssen in solchen Situationen zu dem alten if-then Error Handling zurückkehren.
Java und .NET haben dieses Problem nicht, da sie jeweils ein standardisiertes ABI haben und daher das werfen und fangen von Exceptions über Binary Grenzen hinweg kein Problem darstellt.
Exception sicheres Klassen Design
Nach welchen Richtlinien schreibt man denn nun Exception sichere Klassen? Das Paradebeispiel dafür ist eine Stack Klasse wie
std::stack- wobeistd::stackja eigentlich nur ein Container Adapter ist. Eine naive Implementierung einer Stack Klasse könnte so aussehen:template<typename T> class Stack { private: T* data; std::size_t used; std::size_t space; public: explicit Stack(std::size_t expectedElements = 100) : data(static_cast<T*>(operator new(expectedElements*sizeof T))) , used(0) , space(expectedElements) { } Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); } ~Stack() { std::destroy(data, data+used); operator delete(data); } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; } T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; } bool empty() const { return used==0; } std::size_t size() const { return used; } void swap(Stack& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } };Hier gibt es eine Menge Probleme. Gehen wir sie der Reihe nach an:
Stack(Stack const& other) : data(static_cast<T*>(operator new(other.used*sizeof T))) , used(other.used) , space(other.used) { std::uninitialized_copy(other.data, other.data+other.used, data); }Sollte eine Kopieroperation in
std::uninitialized_copyfehlschlagen, so wird der Speicher auf den data zeigt nicht aufgeräumt.void push(T const& obj) { if(space>used) { std::consruct(data+used, obj); ++used; return; } space*=2+1; T* temp=operator new(space*sizeof T); std::uninitialized_copy(data, data+used, temp); std::construct(temp+used, obj); std::swap(data, temp); std::destroy(temp, temp+used); operator delete(temp); ++used; }space wird erhöht bevor die Kopieroperationen beendet sind. Sollte new oder
std::copy()fehlschlagen bleibtspaceauf dem erhöhten Wert obwohl keine Erhöhung stattfand.T pop() { if(empty()) throw StackEmptyException(); T temp(data[--used]); std::destroy(data+used); return temp; }Sollte eine der beiden Kopieroperation fehlschlagen, geht das Objekt für immer verloren da wir es bereits aus unserem Stack gelöscht haben - es aber nie beim Caller ankam.
Eine elegantere Variante diese Probleme zu umgehen wäre folgende Implementierung:
template<typename T> class StackImpl { public: T* data; std::size_t used; std::size_t space; explicit StackImpl(std::size_t elements) : data(static_cast<T*>(operator new(elements*sizeof T))) , used(0) , space(elements) { } ~StackImpl() { std::destroy(data, data+used); operator delete(data); } void swap(StackImpl& other) { std::swap(data, other.data); std::swap(used, other.used); std::swap(space, other.space); } private: StackImpl(StackImpl const&); StackImpl& operator=(StackImpl& const); }; template<typename T> class Stack { private: StackImpl<T> impl; public: explicit Stack(std::size_t expectedElements = 100) : impl(expectedElements) { } Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; } Stack& operator=(Stack& const other) { Stack temp(other); swap(temp); return *this; } void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; } void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } bool empty() const { return impl.used==0; } std::size_t size() const { return impl.used; } void swap(Stack& other) { impl.swap(other.impl); } };Da wir eine Hilfsklasse verwenden die das Speichermanagement übernimmt, entstehen im Konstruktor keine Speicherlecks mehr:
Stack(Stack const& other) : impl(other.impl.used) { std::uninitialized_copy(other.impl.data, other.impl.data+other.impl.used, impl.data); impl.used=other.impl.used; }Sollte
std::uninitialized_copyfehlschlagen wird dennoch impl zerstört und der Speicher korrekt freigegeben. Wichtig ist, dassusederst gesetzt wird nachdem das Kopieren erfolgreich war.void push(T const& obj) { if(impl.space == impl.used) { Stack temp(impl.space*2+1); std::unitialized_copy(impl.data, impl.data+impl.used, temp.impl.data); temp.impl.used=impl.used; swap(temp); } std::construct(impl.data+impl.used, obj); ++impl.used; }Wir verwenden hier das bekannte Copy&Swap um den Speicherbereich zu vergrößern. Wir reduzieren dadurch den nötigen Code und gewinnen Robustheit.
void pop() { if(empty()) throw StackEmptyException(); std::destroy(impl.data+impl.used-1); --impl.used; } T& top() { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; } T const& top() const { if(empty()) throw StackEmptyException(); return impl.data[impl.used-1]; }Ein
pop()dass den gepopten Wert by Value liefert, kann nie Exception Sicher sein. Wir brauchen daher einetop()Methode um an das oberste Element zu gelangen. Nebenbei gewinnen wir dadurch noch die Möglichkeit Stack als ein konstantes Objekt verwenden zu können, da wir nun mittop()an das oberste Element kommen ohne den Stack ändern zu müssen.Design von Exception Klassen
Je nachdem mit welcher Sprache man arbeitet sehen Exceptions immer leicht anders aus. Exceptions können das Debuggen erleichtern wenn sie wichtige Informationen wie Was ist passiert?, Wo ist es passiert? und uU auch ein Warum ist es passiert? mitteilen. Das essentielste davon ist "Was ist passiert?". In der C++ Standard Library über die virtuelle Funktion exception::what() gelöst. Java und C# bieten jeweils noch eine Antwort auf die Frage "wo ist es passiert?" Anhand eines Stack Traces. C++ bietet soetwas nicht eingebaut, aber man kann dennoch an einen Stack Trace gelangen.
Die einfachste Möglichkeit einen Stack Trace zu bekommen ist einen Debugger mitlaufen zu lassen - in der Debug Version während wir noch testen - werden wir das vermutlich sowieso immer machen. Aber wenn wir keinen Debugger mitlaufen lassen haben, können wir die System API verwenden (sofern wir mit Debug Informationen kompiliert haben) oder aber eine fertige Lösung.
Das wichtigste Feature dass Exception Klassen bieten müssen ist eine durchdachte Hierachie. Denn wenn jeder Fehler der erzeugt wir lediglich vom Typ
StandardExceptionist, kann man nur sehr schwer darauf reagieren. Es ist wichtig einen Mittelweg aus zu tiefer Hierachie und zu breiter Hierachie zu finden. Denn wenn wir eine Exception von einer anderen erben lassen muss dies wirklich eine "A ist spezialfall von B"-Situation sein. Oft ist so eine Entscheidung nicht leicht zu treffen: wenn ich eine Datei nicht öffnen kann weil mir die Rechte fehlen, ist das dann eineIOExceptionoder eineSecurityException?Der Konstruktor einer Exceptionklasse darf nie eine Exception erzeugen - denn wir wissen ja: sollte eine Exception auftreten während eine Exception behandelt wird, wird das Programm beendet. Das bedeutet auch, dass man mit Speicherreservierungen vorsichtig sein muss.
Exception Sicherheit ohne try/catch
Der große Vorteil von C++ Exceptions ist RAII. Anstatt überall try/catch schreiben zu müssen, können wir mit RAII die Fehlerfälle meistens sehr gut abfangen ohne sie explizit zu behandeln.
Betrachten wir folgenden Code:
class Class { private: char* name; int* array; public: Class(char const* name) : name(new char[strlen(name)+1]), array(new int[100]) { strcpy(this->name, name); fill(array); } //... };Das Problem ist offensichtlich: wenn eine der beiden Allokationen fehlschlägt, wird die andere nicht mehr rückgängig gemacht. Wir könnten also mit try/catch versuchen das Problem zu lösen:
class Class { private: char* name; int* array; public: Class(char const* name) : name(0), array(0) { try { this->name = new char[strlen(name)+1]; array = new int[100]; } catch(std::bad_alloc& e) { delete [] this->name; delete [] array; throw; } strcpy(this->name, name); fill(array); } //... };Das funktioniert zwar, aber es geht besser:
class Class { private: std::string name; std::vector<int> array; public: Class(char const* name) : name(name), array(100) { fill(array); } //... };Nicht nur dass wir jetzt keine Memory-Leaks mehr haben, wir haben auch noch den Code reduziert und schlanker gemacht. Meistens ist es eine gute Idee dynamische Allokationen in eine Ressourcen Klasse zu stecken, da so nicht nur Fehler verhindert werden sondern der Code auch deutlich einfacher gestaltet bleibt.
Besonders problematisch sind dynamische Allokationen in einem Funktionsaufruf:
foo(new Bar(), new Baz());Mit Smart Pointern wie zB scoped_ptr/auto_ptr oder shared_ptr kann man diese Probleme umgehen indem die Smart Pointer die Ressource verwalten.
Die weite Welt
Exception Handling ist nur eine mögliche Lösung für das komplexe Problem der Fehlerbehandlung. Sie haben in diesem Artikel bereits ein paar Methoden kennengelernt, es gibt aber noch weit mehr. Jede dieser Methoden hat Vorteile und Nachteile, es gibt keine beste Lösung hier.
-
Error Stack
Jeder Fehler der auftritt wird auf einen bestimmten Stack gesetzt und die Funktion beendet sich selbst. An bestimmten Code Stellen kann man dann auf Fehler testen die ja alle auf diesem Error Stack liegen. Jeder Code kann einen behandelten Fehler vom Stack poppen - man hat somit ein feineres System was Fehlerbehandlung betrifft als wir bei Exceptions haben (wo es nur den Zustand Fehler (Exception wurde geworfen) und nicht Fehler (keine Exception geworfen) gibt.
Deferred Error Handling
iostreammacht es vor: wenn ein Fehler auftritt, dann setzen wir ein internes error-flag und teilen so mit dass etwas schiefgegangen ist.Callbacks
Unter Unix sind Signals recht bekannt, in der Windows-Welt eher nicht. Dennoch bieten Signale eine interessante Möglichkeit Fehler zu handhaben. Jedesmal wenn ein Fehler auftritt wird ein Signal generiert, auf dass eine Anwendung (oder ein Teil einer Anwendung) per Callback reagieren kann indem man das Callback für das entsprechende Signal registriert.
Zu diesen 3 Methoden gibt es unter C++ Exception Alternatives auch ein bisschen Lesestoff wenn Sie mehr erfahren wollen.
Conditions
Nicht jeder Fehler ist ein fataler Fehler. Conditions ermöglichen es an definierten Stellen von einem Fehler zu recovern.
Fehler passieren und egal was wir für eine Methode verwenden um sie zu Handhaben, wir müssen acht geben.
-
So. Endlich wieder etwas zeit gefunden...
Bei der copy-Geschichte haben wir unterschiedliche Blickwinkel - ich hoffe du kannst meine version aktzeptieren denn ich finde sie passend.
logic_error habe ich erwaehnt und ein paar kleine weitere verbesserungen durchgefuehrt. nur haengt das forum gerade etwas da der artikel zu lang ist
-
Shade Of Mine schrieb:
Bei der copy-Geschichte haben wir unterschiedliche Blickwinkel - ich hoffe du kannst meine version aktzeptieren denn ich finde sie passend.
Klar, ist dein Artikel.
Shade Of Mine schrieb:
logic_error habe ich erwaehnt und ein paar kleine weitere verbesserungen durchgefuehrt. nur haengt das forum gerade etwas da der artikel zu lang ist
Das kenne ich nur zu gut. Für längere Artikel ist das aktuelle Verfahren absolute ungeeignete.
-
falls es keine technischen einwaende mehr gibt, werde ich es am wochenende auf [R] setzen.