[X] Semantic Desktop
-
Semantic Desktop die nächste Evolution des Rechners?
-
1. Einleitung
-
2. Semantic Web
-
3. Geschichte
-
4. Was ist ein Semantic Desktop?
-
5. Technologien/Standards
-
5.1 RDF / RDF Schema
-
5.2 OWL
-
5.3 SWRL
-
5.4 SPARQL
-
6. Fazit
-
7. Referenzen
1. Einleitung
Das Internet revolutionierte die Art und Weise mit der wir Kommunizieren. E-Mails, Instant Messenger(IM) und andere Dienste gehören zu unserem Alltag und dieser scheint immer schwerer zu bewältigen ohne diese Anwendungen. Doch das dadurch resultierende Informationsaufkommen lässt sich immer schwerer bändigen. Um dem entgegen zu wirken entstammt die Idee des Semantic Desktop.
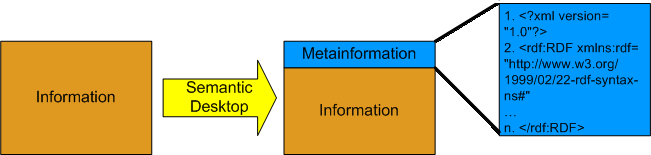
Das Ziel des Semantic Desktop ist es den Umgang und das Erstellen von Inhalten zu erleichtern und zu beschleunigen. Dies soll durch das Deklarieren von Inhalten geschehen. Es soll eine einheitliche Beschreibung von Informationen entstehen. Dies bezieht sich nicht auf die Inhalte, sondern das wir Sie für den Computer verständlich beschreiben. Dies geschieht wie bei MP3 Tags nur das das System nicht auf Audio Daten beschränkt ist.
Da der Semantic Desktop eine Implementierung von Semantic Web Technologien auf den Desktop ist. Wird als erstes die Idee des Semantic Web beschrieben und es wird dann näher auf den Semantic Desktop eingegangen.2. Semantic Web
Das Ziel des Semantic Web ist es das Web für den Computer benutzbar zu machen.
Zurzeit funktioniert das Web über Hyperlinks. Die Seiten werden mit Hyperlinks miteinander verbunden und man kann so durch das Web Navigieren. Diese Art des Vernetzens verteilt die Aufgabe der Verbindungen setzen auf den Anbieter bzw. Erzeuger von Informationen. Das birgt die Problematik das Informationen verschwinden bzw. nicht wieder gefunden werden können. Da man den Pfad kennen muss der zu der Information führt. Dieses Problem ist schon lange bekannt und die derzeitige Lösungsstrategie sind Suchmaschinen. Doch deren Funktion ist durch Spamer und der riesigen Informationsflut mittlerweile sehr eingeschränkt und mit immer steigendem Aufwand zu gebrauchen.
Die Strategie des Semantic Web ist es den Seiten selbst oder in Datenbanken Meta Information anzufügen. Die Aussagen über die Information beinhalten, Wie der Autor, Thema, Themengebiete und andere Angaben die zu der Website passen. Dies führt zu einer Art Weltwissen, einem System das eine Repräsentation des Menschlichen Wissens Darstellt und das in einer Ontologie Strukturiert wird.Dafür gliedert sich das Semantic Web in 4 Ebenen auf.
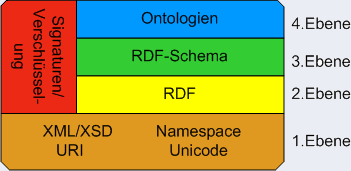
- 1.Ebene korrekten Darstellung von Inhalten
Hier sind Standards definiert die ein Medienneutrale (uniformierte) Darstellung erlauben. Als Keycode liegt das Unicode Format vor.
Zur Speicherung wird das XML Format verwendet. Das eine Medien- und Sprachneutralität Darstellung ermöglicht.
Das Referenzieren von Ressourcen geschieht mittels URI’s (Der bekannteste Identifier ist der Locator [URL]). URI’s können wie folgt aussehen:ftp://ftp.is.co.za/rfc/rfc1808.txt http://www.ietf.org/rfc/rfc2396.txt ldap://[2001:db8::7]/c=GB?objectClass?one mailto:John.Doe@example.com news:comp.infosystems.www.servers.unix tel:+1-816-555-1212 telnet://192.0.2.16:80/ urn:oasis:names:specification:docbook:dtd:xml:4.1.2Es werden zwar einige dieser Protokolle nicht im Semantic Web benutzt aber es macht Sinn wenn man das in Verbindung mit dem Semantic Desktop bringt. Die erste Ebene ist damit die direkte Schnittstelle zum „alten“ Web.
- 2.Ebene RDF Graphen
Hier beginnt eigentlich das Semantic Web. Denn hier beschreiben wir unsere Inhalte. Also ihnen wird eine Bedeutung(Semantic) zu geordnet. Dafür wird RDF benutzt, das ich später beschreiben werde. [siehe RDF Kapitel]
- 3.Ebene RDF Schema
Das RDF Schema dient zum beschreiben von RDF-Triples. Das RDF-Klassen und Beziehungssystem ist ähnlich dem Typen System von Objekt-Orientierten Programmiersprachen. Es unterscheidet sich darin das die Definition einer Klasse im RDF Vokabular, nicht durch Attribute und deren Typen gestaltet wird, sondern durch die Terme auf die sich die Ressourcen beziehen.
Diese RDF-Triples definieren Regeln bzw. Aussagen wie:
Tür -> subclass -> Auto Tür -> Typ -> Material Material -> Typ -> Metall VW Käfer -> Typ -> AutoSo können Beziehungen zwischen den Inhalten auf den Seiten gesetzt werden. Wobei die Beziehungen auch auf Teile der Seite oder Absätze bezogen werden können. Dadurch können Texte erstellt werden aus diesen Textbausteinen.
- 4.Ebene Ontologien
In dieser Ebene wird es richtig spannend. Denn in dieser Ebene können wir auf einheitliche beschriebene Inhalte mit gleichem Vokabular zugreifen. In dieser Ebene werden Ontologien erstellt. Also es werden die in der vorherigen Ebene definierten Regeln hierarchisch Organisiert. Wenn wir das auf unser Beispiel beziehen. Können wir folgende Frage beantworten und zwar "Aus was besteht die Tür eines VW Käfer?". Da wir wissen das der Käfer ein Auto ist und ein Auto eine Tür hat und eine Tür aus Material besteht und Metall ein Material ist können wir sagen das die Tür des Käfers aus Metall besteht. Um sich das zu vereinfachen kann man das als eine Relationale Datenbank ansehen, nur das hier noch ein Objekt Modell dazu gekommen ist. Mann kann also Tabellen als Typ angeben bei der Deklaration der Tabellenspalten.
- Verifizieren
Zum Verifizieren von Daten werden Signaturen und Verschlüsselungsverfahren genutzt. Das die Echtheit der Daten gewährleistet.
3. Geschichte
Bevor wie uns ins Technische begeben ist erst mal eine kleine Geschichtsstunde angesetzt. Den es ist schon Interessant woher diese Ideen Stammen.
Die erste Beschreibung des Semantic Desktop, geschah 1945 durch Vannevar Bush in dem Artikel “As we may think”(Man glaubt es kaum ein vorfahre von George W. Bush). Er beschrieb ein Gerät namens “Memex” das alle Aufzeichnungen - Text, Bild und Ton - seines Benutzers speichern kann und alle Kommunikationsmittel vereint. Das bewältigt dieses Gerät sehr schnell und für den Benutzer sehr intuitive. Das Gerät sollte aber völlig analog funktionieren und Mikrofilm als Speichermedium nutzen. Weitere Wurzeln findet man bei Ted Nelson. Der 1960 ein System beschrieb, das aus verknüpften Informationen bestand. Die in einer Informationsgesellschaft gehandelt wurden. Er nannte das System "Xanadu". Der erste versuch solch ein System umzusetzen fand durch Tim Berners-Lee(Begründer des Internet) statt. Der sein Programm "Enquire-Within-Upon-Everything" nannte. Wobei der Name alles sagt. Das in der Lage war Informationen über Personen, Projekte, Hardwareressourcen und wie Sie miteinander verknüpft waren, zu beschreiben. Es sollte die Dokumentationen die am CERN zu der Zeit geschrieben wurden Strukturieren und einfacher zugänglich machen. Es fand aber keinen Anklang.Als nächstes folgt das Semantic Web. Das 1998 von Tim Berners Lee eingeführt wurde. Er fordert eine Stärkung der Nutzbarkeit der Daten und arbeitet auch an den entsprechenden Standards wie RDF mit.
Der Begriff Semantic Desktop wurde durch Stefan Decken beschrieben und von Leo Sauermann 2003 aufgegriffen um die verschiedenen Technologien und Ideen in einem Hauptbegriff zusammen zu fassen. Wobei Stefan Decker und Martin Frank den Begriff Networked Semantic Desktop, 2004 formulierten. Was den Semantic Desktop um eine P2P Funktion erweitert in der die Ontologien untereinander getauscht werden können.
4. Was ist ein Semantic Desktop?
Die Definition des Semantik Desktop leitet sich aus den Beschreibungen von Vannevar Bush ab. Da er aber ein Analoges System beschrieb wurde die Definition nach ihrer technischen Realisierung angepasst.
auch ein schlachtplan ergibt sich ähnlich dem Semantic Web Paper von Tim-Berners-Lee.Ein Semantic Desktop (SD) ist ein Gerät, das in der Lage ist alle digitalen Informationen seines Benutzers zu speichern. Diese werden als Semantic Web Ressourcen interpretiert und als RDF Graphen gespeichert. Ressourcen aus dem Web können gespeichert, bearbeitet und der Inhalt kann mit anderen Benutzern geteilt werden.
Ontologien repräsentieren das persönliche mentale Model seines Benutzers. Sie stellen damit den „Klebstoff“ zwischen Informationen und dem „System“ da. Anwendungen eines Semantic Desktop speichern, lesen und kommunizieren via Ontologien und Semantic Web Protokollen. Dadurch ist der Semantic Desktop eine Erweiterung des Gedächtnisses seines Benutzers.Wenn man es grob zusammenfassen möchte, wäre ein Semantic Desktop ein lokales Semantic Web. Der unterschied ist aber das man hier nicht eine riesige "relationale" Datenbank anstrebt, sondern das Entwickeln von Anwendungen die diese Daten auswerten und aufbereiten können.
Es werden Programme nicht mehr ein Problem lösen, sondern eher in einem Verbund miteinander Kommunizieren. Es werden also intelligentere Anwendungen angestrebt, die sich mehr auf seinen Benutzer anpassen und ihm ständig wiederkehrende arbeiten wie das sortieren von Dateien abnehmen. Da sie nach ihrer Bedeutung strukturiert werden. Man spricht auch in diesem Zusammenhang auch von Software Agenten.Die ersten Versuche solche Systeme laufen schon. Es gibt einmal das Smart Web Projekt des DFKI. Das eine Software für Mobile Endgeräte ist, die durch Sprach- und Tastatureingaben gesteuert werden kann. Es ist aber nur möglich Fragen zu stellen und auch nur zu bestimmten Themengebieten. Was aber trotzdem beeindruckend ist, weil es eine Aussicht ist auf weiterführende Projekte ist wie die nächsten.
Das DFKI hat noch ein zweites Projekt, und zwar gnowsis das eine Semantic Desktop System darstellt. Im Mittelpunkt steht ein Web-Server der die Handhabung der Ontologie übernimmt. Gnowsis bietet ein Framework an, zur Anbindung an bestehenden Software Lösungen. Es wird versucht die Inhalte aus diesen Anwendungen zu nutzen und in der Ontologie im Server abzubilden.
Als weiteres Projekt zu erwähnen ist haystack vom MIT. Das ein E-Mail Client, Adressbuch, Kalender und Dateisystem ist. Im Gegensatz zum gnowsis Projekt wird hier nicht ein Framework mit Pipelines zu Anwendungen realisiert, sondern ein einheitliches System.5. Technologien/Standards:
Hier werden die Techniken genauer beleuchtet, die in der Einleitung erwähnt wurden.
5.1 RDF - Resource Description Framework
Das Ressource Description Framework ist eine Sprache um Informationen über Ressourcen im Internet Darzustellen. Streng genommen ist es keine eigene Sprache, sondern ein XML Dialekt. Es geht aber hier um die Darstellung von Metadaten, also um Informationen über Informationen. Was im ersten Moment etwas Schizophren klingt. Es geht aber in diesem Fall um Informationen wie der Autor eines Textes oder die Art des Textes. Man kann das natürlich auch auf andere Informationen wie Musik, Video oder jede andere Ressource beziehen. Dabei können die Informationen Variieren. Definiert wurde Sie aber um zusätzliche Informationen über Web Dokumente zu Definieren und sie maschinell verarbeiten zu können. RDF ist konzipiert um diese Art von Informationen zwischen Anwendungen auszutauschen ohne den Verlust der Bedeutung. Dabei werden Informationen mittels URI’s identifiziert und beschrieben.
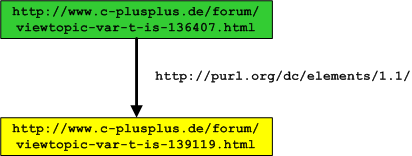
RDF ist wie folgt aufgebaut. Es besteht aus drei Objekttypen, den Ressourcen, Eigenschaftselementen und den Objekten. Die auch als Subjekt, Objekt und Prädikat beschrieben werden. Durch Kombination der drei Typen wird eine Aussage über eine Ressource formuliert. Um das ganze anschaulich zu machen beschreiben wir einen RDF Graph für diesen Artikel:
- Das Subjekt ist die URL des Artikels "http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html"
- Das Objekt Ordnet der Information eine Bedeutung zu in unserem Fall "http://purl.org/dc/elements/1.1/Creator".
Um Eigenschaften zu definieren wird der Dienst PURL genutzt PURL steht für Persistent Uniform Ressource Locator. Das ist eine Verlinkung von einer URL auf eine URL. Dieser Dienst ist für URL's die in Büchern oder Zeitschriften veröffentlicht wurden. Denn nach ein paar Jahren kann der Link nicht mehr gültig sein und man kann so den Link auf eine andere Seite oder auf die neue URL der Seite setzen und so bleibt die URL im Buch gültig.
Don't say "color" say <http://example.com/2002/std6#col>Damit die Anwendungen unter den Eigenschaften immer das gleiche verstehen hat die DCMI (Dublin Core Metadata Initiative) ein paar Standard Terme mit PURL's verlinked. Näheres findet ihr unter http://dublincore.org. Dies sind die vorher beschriebenen RDF Schema.
- Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichts sagend ist verlinken wir auf den Artikel im Forum in dem ich mich beschreibe. Also tragen wir bei Objekt den folgenden Link ein " http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html". Aber hier könnte auch ein Link auf einen XFN(XHtml Friends Network) oder FOAF(Friend-Of-A-Friend) Eintrag stehen.
Der RDF Graph dazu sieht so aus.
RDF Graphen werden mittels eines XML Syntax beschrieben. Als Beispiel nehmen wir den gerade beschriebenen RDF Graphen.
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:exterms="http://purl.org/dc/elements/1.1/"> 4. <rdf:Description rdf:about="http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html"> 5. <exterms:Creator>http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html</exterms:Creator> 6. </rdf:Description> 7. </rdf:RDF>- In der ersten Zeile wird nur definiert welche XML Version benutzt wird.
- Die zweite Zeile definiert den RDF Namespace und alle tags die mit <rdf: beginnen sind Teil des RDF Syntax.
- Die dritte Zeile ist auch eine Namespace Deklaration und sagt aus, dass wir die Eigenschaften des DCMI benutzen um unsere Graphen zu beschreiben.
- Die vierte Zeile ist die Ressource die Beschrieben wird
- Die fünfte Zeile beginnt dem tag exterms:Creator und ist die Eigenschaft. Der Term, der in dem tag eingeschlossen ist, ist das Objekt.
- Die sechste Zeile schließt die Description
- Die siebte Zeile beendet unseren RDF Graphen.
5.2 OWL
Die Web Ontology Language(OWL) ist eine Sprache zum beschreiben von Ontologien, wobei sie sich in 3 Sprach Ebenen unterteilt. Mit OWL lassen sich Ausdrücke formulieren ähnlich der Prädikaten-Logik. Die verschiedenen Ebenen unterscheiden sich in der Ausdrucksfähigkeit. OWL basiert auf den RDF-Syntax und DAML+OIL.
OWL Lite
OWL Light dient zum Beschreiben einfacher Taxonomien. Es sind die Grundlegenden Funktionen zum definieren von Klassen und setzen von Abhängigkeiten.
OWL DL
DL steht für Description Logic(Beschreibungslogik) und ist gleichzusetzen mit der ersten Stufe der Prädikatenlogik.
OWL Full
OWL Full ermöglicht Ausdrücke aus Prädikatenlogiken höherer Stufe.
Hier ein Beispiel:
<owl:Class rdf:ID="WhiteWine"> <owl:intersectionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Wine" /> <owl:Restriction> <owl:onProperty rdf:resource="#hasColor" /> <owl:hasValue rdf:resource="#White" /> </owl:Restriction> </owl:intersectionOf> </owl:Class>Dies ist ein Beispiel für eine IntersectionOf Abfrage. Es ist wird die „Collection“ auf Weißweine überprüft.
5.3 SWRL
SWRL steht für Semantic Web Rule Language und ist eine Zusammenführung von OWL Lite und OWL DL, nur das hier die Lesbarkeit durch den Menschen im Vordergrund steht. Es lehnt sich dabei an EBNF(Extended-Backus-Nau-Form) in seiner Syntax an.
Der Syntax sieht so aus:
axiom ::= rule rule ::= 'Implies(' [ URIreference ] { annotation } antecedent consequent ')' antecedent ::= 'Antecedent(' { atom } ')' consequent ::= 'Consequent(' { atom } ')' atom ::= description '(' i-object ')' | dataRange '(' d-object ')' | individualvaluedPropertyID '(' i-object i-object ')' | datavaluedPropertyID '(' i-object d-object ')' | sameAs '(' i-object i-object ')' | differentFrom '(' i-object i-object ')' | builtIn '(' builtinID { d-object } ')' builtinID ::= URIreference i-object ::= i-variable | individualID d-object ::= d-variable | dataLiteral i-variable ::= 'I-variable(' URIreference ')' d-variable ::= 'D-variable(' URIreference ')'Der konkrete XML Syntax sieht so aus.
<swrlx:Ontology swrlx:name = xsd:anyURI > Content: (owlx:VersionInfo | owlx:PriorVersion | owlx:BackwardCompatibleWith | owlx:IncompatibleWith | owlx:Imports | owlx:Annotation | owlx:Class[axiom] | owlx:EnumeratedClass(D,F) | owlx:SubClassOf(D,F) | owlx:EquivalentClasses | owlx:DisjointClasses(D,F) | owlx:DatatypeProperty | owlx:ObjectProperty | owlx:SubPropertyOf | owlx:EquivalentProperties | owlx:Individual[axiom] | owlx:SameIndividual | owlx:DifferentIndividuals | ruleml:imp[axiom] | ruleml:var[axiom])* </swrlx:Ontology>5.4 SPARQL
SPARQL ist ein rekursives Akronym und steht für "SPARQL Protocol and RDF Query Language". Durch SPARQL wird die Aussage klar das aus dem WWW, eine Globale Datenbank zu erstellen.
SPARQL ist eine Sprache um Informationen aus einem RDF Graphen zu erhalten. Die Grundstruktur erinnert einen stark an SQL. Da ein ähnlicher bzw. der Syntax darauf gebaut wurde. Abfragen bestehen aus vier Grund Bausteinen. einer PREFIX Zeile in der Variablen definiert werden können. Eine SELECT Anweisung in der die Datenbestände angegeben werden können die durchsucht werden sollen. Eine WHERE Zeile in der ausgewählt wurde welche Daten aus den vorher angegebenen Quellen extrahiert werden sollen.SPARQL ist eine Abfrage(query) Sprache und dient nur dem Abfragen von Inhalten, im Gegensatz zu den Ontologie Sprachen. Hier ein Beispiel, indem nach den Artikeln von „mosta“ gefragt wird:
PREFIX page: http://www.c-plusplus.net/forum/Artikel SELECT ?topic WHERE{ ?x page:topic ?mosta }6. Fazit
Im groben und Ganzen ist es eine toll klingende Sache, wobei ich bisher die Nachteile wissentlich verschwiegen habe. Denn das Problem ist, dass man alle Inhalte selbst Editieren muss. Das heißt man muss selber die Ontologien bauen. Diese Problematik wird sich aber mit der Zeit legen. Wenn es nämlich schon fertige "default" Ontologien gibt, die für uns dann das grundlegende Einsortieren übernehmen können. Bei den jetzigen Systemen läuft das aber alles per Fuß. Was sich in etwa wie die ersten Spracherkennungssoftware verhält, nur mit einer längeren „Trainingsphase“.
7. Referenzen
Das RFC zum URI Standard
http://www.gbiv.com/protocols/uri/rfc/rfc3986.html
Das RDF-Schema Paper vom W3C
http://www.w3.org/TR/rdf-schema/
Der Artikel von Vannevar Bush
http://en.wikipedia.org/wiki/As_We_May_Think
Das SWRL Paper
http://www.w3.org/Submission/SWRL/
-
-
ha ich hab den Artikel doch noch dieses Jahr fertig bekommen;-p. Wär nett, wenn ich eine Einschätzung über den Artikel bekommen könnte bevor er rausgeht. Also ob Inhaltlich alles stimmig ist. Den ich hab den bestimmt 10 mal neu angefangen und immer wieder aus Textgruppen zusammengefühgt.
gruß und guten rutsch an die redaktion
-
Cool, aber für 'ne inhaltliche Prüfung muss er zuerst auf Status T, dann für die Rechtschreibprüfung auf R
")
-
da keiner bisher was zu meckern hat. Stell ich den Artikel auf Rechtschreibprüfung . Wenn jmd. etwas nicht schlüssig erscheint kann er es ja trotzdem sagen
-
hab ihn jetzt gelesen, mir ist nichts aufgefallen, außer:
Der unterschied ist aber das man hier eine riesige "relationale" Datenbank anstrebt, sondern das Entwickeln von Anwendungen die diese Daten auswerten und aufbereiten können.
Müsste es nicht "keine riesige "relationale" Datenbank" heißen?
MfG
GPC
-
korrigiert heißt jetzt so:
hier nicht eine riesige "relationale" Datenbank anstrebt
-
soll ich den Artikel auf fertig stellen? oder prüft denn noch wär anders auf rechtschreibfehler?
-
Ich schau heute oder morgen noch drüber.
-
Semantic Desktop die nächste Evolution des Rechners?
-
1 Einleitung
-
2 Semantic Web
-
3 Geschichte
-
4 Was ist ein Semantic Desktop?
-
5 Technologien/Standards
-
5.1 RDF / RDF Schema
-
5.2 OWL
-
5.3 SWRL
-
5.4 SPARQL
-
6 Fazit
-
7 Referenzen
1 Einleitung
Das Internet revolutionierte die Art und Weise mit der wir kommunizieren. E-Mails, Instant Messenger(IM) und andere Dienste gehören zu unserem Alltag und dieser scheint immer schwerer ohne diese Anwendungen zu bewältigen zu sein. Doch das dadurch resultierende Informationsaufkommen lässt sich immer schwerer bändigen. Um dem entgegen zu wirken entstammt die Idee des Semantic Desktop.
Das Ziel des Semantic Desktop ist es, den Umgang mit und das Erstellen von Inhalten zu erleichtern und zu beschleunigen. Dies soll durch das Deklarieren von Inhalten geschehen. Es soll eine einheitliche Beschreibung von Informationen entstehen. Dies bezieht sich nicht auf die Inhalte, sondern dass wir Sie für den Computer verständlich beschreiben. Dies geschieht wie bei MP3-Tags, nur dass das System nicht auf Audio-Daten beschränkt ist.
Da der Semantic Desktop eine Implementierung von Semantic-Web-Technologien auf den Desktop ist, wird als erstes die Idee des Semantic Web beschrieben und es wird dann näher auf den Semantic Desktop eingegangen.2 Semantic Web
Das Ziel des Semantic Web ist es, das Web für den Computer benutzbar zu machen.
Zurzeit funktioniert das Web über Hyperlinks. Die Seiten werden mit Hyperlinks miteinander verbunden und man kann so durch das Web navigieren. Diese Art des Vernetzens verteilt die Aufgabe, Verbindungen zu setzen, auf den Anbieter bzw. Erzeuger von Informationen. Das birgt die Problematik, dass Informationen verschwinden bzw. nicht wieder gefunden werden können, da man den Pfad kennen muss, der zu der Information führt. Dieses Problem ist schon lange bekannt und die derzeitige Lösungsstrategie sind Suchmaschinen. Doch deren Funktion ist durch Spammer und der riesigen Informationsflut mittlerweile sehr eingeschränkt und mit immer steigendem Aufwand zu gebrauchen.
Die Strategie des Semantic Web ist es, den Seiten selbst oder in Datenbanken Meta-Information anzufügen, die Aussagen über die Information beinhalten, wie Autor, Thema, Themengebiete und andere Angaben, die zu der Website passen. Dies führt zu einer Art Weltwissen, einem System, das eine Repräsentation des menschlichen Wissens darstellt und das in einer Ontologie strukturiert wird.Dafür gliedert sich das Semantic Web in 4 Ebenen auf.
- 1. Ebene: korrekte Darstellung von Inhalten
Hier sind Standards definiert die ein medienneutrale (uniformierte) Darstellung erlauben. Als Keycode liegt das Unicode-Format vor.
Zur Speicherung wird das XML-Format verwendet, das eine medien- und sprachneutrale Darstellung ermöglicht.
Das Referenzieren von Ressourcen geschieht mittels URIs (Der bekannteste Identifier ist der Locator [URL]). URIs können wie folgt aussehen:ftp://ftp.is.co.za/rfc/rfc1808.txt http://www.ietf.org/rfc/rfc2396.txt ldap://[2001:db8::7]/c=GB?objectClass?one mailto:John.Doe@example.com news:comp.infosystems.www.servers.unix tel:+1-816-555-1212 telnet://192.0.2.16:80/ urn:oasis:names:specification:docbook:dtd:xml:4.1.2Es werden zwar einige dieser Protokolle nicht im Semantic Web benutzt, aber es ist sinnvoll, wenn man das in Verbindung mit dem Semantic Desktop bringt. Die erste Ebene ist damit die direkte Schnittstelle zum „alten“ Web.
- 2. Ebene: RDF-Graphen
Hier beginnt eigentlich das Semantic Web. Denn hier beschreiben wir unsere Inhalte. Also ihnen wird eine Bedeutung (Semantic) zugeordnet. Dafür wird RDF benutzt, das ich später beschreiben werde. [siehe RDF-Kapitel]
- 3. Ebene: RDF-Schema
Das RDF-Schema dient zum Beschreiben von RDF-Triples. Das RDF-Klassen- und Beziehungssystem ist ähnlich dem Typensystem von objektorientierten Programmiersprachen. Es unterscheidet sich darin, dass die Definition einer Klasse im RDF-Vokabular nicht durch Attribute und deren Typen gestaltet wird, sondern durch die Terme auf die sich die Ressourcen beziehen.
Diese RDF-Triples definieren Regeln bzw. Aussagen wie:
Tür -> subclass -> Auto Tür -> Typ -> Material Material -> Typ -> Metall VW Käfer -> Typ -> AutoSo können Beziehungen zwischen den Inhalten auf den Seiten gesetzt werden. Wobei die Beziehungen auch auf Teile der Seite oder Absätze bezogen werden können. Dadurch können aus diesen Textbausteinen Texte erstellt werden.
- 4. Ebene: Ontologien
In dieser Ebene wird es richtig spannend. Denn in dieser Ebene können wir auf einheitliche beschriebene Inhalte mit gleichem Vokabular zugreifen. In dieser Ebene werden Ontologien erstellt. Also es werden die in der vorherigen Ebene definierten Regeln hierarchisch organisiert. Wenn wir das auf unser Beispiel beziehen, können wir folgende Frage beantworten und zwar "Aus was besteht die Tür eines VW Käfer?". Da wir wissen, dass der Käfer ein Auto ist und ein Auto eine Tür hat und eine Tür aus Material besteht und Metall ein Material ist, können wir sagen das die Tür des Käfers aus Metall besteht. Um sich das zu vereinfachen, kann man das als eine relationale Datenbank ansehen, nur dass hier noch ein Objektmodell dazu gekommen ist. Man kann also Tabellen als Typ angeben bei der Deklaration der Tabellenspalten.
- Verifizieren
Zum Verifizieren von Daten werden Signaturen und Verschlüsselungsverfahren genutzt, die die Echtheit der Daten gewährleisten.
3. Geschichte
Bevor wir uns ins Technische begeben, ist erst einmal eine kleine Geschichtsstunde angesetzt. Denn es ist schon interessant woher diese Ideen stammen.
Die erste Beschreibung des Semantic Desktop, geschah 1945 durch Vannevar Bush in dem Artikel “As we may think”(Man glaubt es kaum ein Vorfahre von George W. Bush). Er beschrieb ein Gerät namens “Memex”, das alle Aufzeichnungen - Text, Bild und Ton - seines Benutzers speichern kann und alle Kommunikationsmittel vereint. Das bewältigt dieses Gerät sehr schnell und für den Benutzer sehr intuitiv. Das Gerät sollte aber völlig analog funktionieren und Mikrofilm als Speichermedium nutzen. Weitere Wurzeln findet man bei Ted Nelson, der 1960 ein System beschrieb, das aus verknüpften Informationen bestand, die in einer Informationsgesellschaft gehandelt wurden. Er nannte das System "Xanadu". Der erste Versuch solch ein System umzusetzen fand durch Tim Berners-Lee (Begründer des Internet) statt, der sein Programm "Enquire-Within-Upon-Everything" nannte (wobei der Name alles sagt), das in der Lage war, Informationen über Personen, Projekte, Hardwareressourcen und wie sie miteinander verknüpft waren, zu beschreiben. Es sollte die Dokumentationen, die am CERN zu der Zeit geschrieben wurden, strukturieren und einfacher zugänglich machen. Es fand aber keinen Anklang.Als nächstes folgt das Semantic Web, das 1998 von Tim Berners-Lee eingeführt wurde. Er fordert eine Stärkung der Nutzbarkeit der Daten und arbeitet auch an den entsprechenden Standards wie RDF mit.
Der Begriff Semantic Desktop wurde durch Stefan Decken beschrieben und von Leo Sauermann 2003 aufgegriffen, um die verschiedenen Technologien und Ideen in einem Hauptbegriff zusammenzufassen. Wobei Stefan Decker und Martin Frank den Begriff Networked Semantic Desktop 2004 formulierten, was den Semantic Desktop um eine P2P-Funktion erweitert in der die Ontologien untereinander getauscht werden können.
4 Was ist ein Semantic Desktop?
Die Definition des Semantik Desktop leitet sich aus den Beschreibungen von Vannevar Bush ab. Da er aber ein analoges System beschrieb, wurde die Definition nach ihrer technischen Realisierung angepasst.
~auch ein schlachtplan ergibt sich ähnlich dem Semantic Web Paper von Tim-Berners-Lee. -- unverständlich~Ein Semantic Desktop (SD) ist ein Gerät, das in der Lage ist, alle digitalen Informationen seines Benutzers zu speichern. Diese werden als Semantic-Web-Ressourcen interpretiert und als RDF-Graphen gespeichert. Ressourcen aus dem Web können gespeichert, bearbeitet und der Inhalt kann mit anderen Benutzern geteilt werden.
Ontologien repräsentieren das persönliche mentale Modell seines Benutzers. Sie stellen damit den „Klebstoff“ zwischen Informationen und dem „System“ dar. Anwendungen eines Semantic Desktop speichern, lesen und kommunizieren via Ontologien und Semantic-Web-Protokollen. Dadurch ist der Semantic Desktop eine Erweiterung des Gedächtnisses seines Benutzers.Wenn man es grob zusammenfassen möchte, wäre ein Semantic Desktop ein lokales Semantic Web. Der Unterschied ist aber, dass man hier nicht eine riesige "relationale" Datenbank anstrebt, sondern das Entwickeln von Anwendungen die diese Daten auswerten und aufbereiten können.
Es werden Programme nicht mehr ein Problem lösen, sondern eher in einem Verbund miteinander kommunizieren. Es werden also intelligentere Anwendungen angestrebt, die sich mehr auf seinen Benutzer anpassen und ihm ständig wiederkehrende Arbeiten, wie das Sortieren von Dateien, abnehmen, da sie nach ihrer Bedeutung strukturiert werden. Man spricht in diesem Zusammenhang auch von Software-Agenten.Die ersten Versuche solcher Systeme laufen schon. Es gibt einmal das Smart-Web-Projekt des DFKI. Das eine Software für mobile Endgeräte ist, die durch Sprach- und Tastatureingaben gesteuert werden kann. Es ist aber nur möglich, Fragen zu stellen und auch nur zu bestimmten Themengebieten. Was aber trotzdem beeindruckend ist, weil es eine Aussicht ist, auf weiterführende Projekte ist, wie die nächsten.
Das DFKI hat noch ein zweites Projekt, und zwar gnowsis das ein Semantic-Desktop-System darstellt. Im Mittelpunkt steht ein Web-Server der die Handhabung der Ontologie übernimmt. Gnowsis bietet ein Framework zur Anbindung an bestehende Softwarelösungen an. Es wird versucht, die Inhalte aus diesen Anwendungen zu nutzen und in der Ontologie im Server abzubilden.
Als weiteres Projekt zu erwähnen ist haystack vom MIT, das ein E-Mail-Client, Adressbuch, Kalender und Dateisystem ist. Im Gegensatz zum gnowsis-Projekt wird hier nicht ein Framework mit Pipelines zu Anwendungen realisiert, sondern ein einheitliches System.5 Technologien/Standards:
Hier werden die Techniken genauer beleuchtet, die in der Einleitung erwähnt wurden.
5.1 RDF - Resource Description Framework
Das Ressource Description Framework ist eine Sprache um Informationen über Ressourcen im Internet darzustellen. Streng genommen ist es keine eigene Sprache, sondern ein XML-Dialekt. Es geht aber hier um die Darstellung von Metadaten, also um Informationen über Informationen, was im ersten Moment etwas schizophren klingt. Es geht aber in diesem Fall um Informationen wie der Autor eines Textes oder die Art des Textes. Man kann das natürlich auch auf andere Informationen wie Musik, Video oder jede andere Ressource beziehen. Dabei können die Informationen variieren. Definiert wurde Sie aber um zusätzliche Informationen über Web-Dokumente zu definieren und sie maschinell verarbeiten zu können. RDF ist konzipiert um diese Art von Informationen zwischen Anwendungen auszutauschen ohne den Verlust der Bedeutung. Dabei werden Informationen mittels URIs identifiziert und beschrieben.
RDF ist wie folgt aufgebaut. Es besteht aus drei Objekttypen, den Ressourcen, Eigenschaftselementen und den Objekten, die auch als Subjekt, Objekt und Prädikat beschrieben werden. Durch Kombination der drei Typen wird eine Aussage über eine Ressource formuliert. Um das ganze anschaulich zu machen beschreiben wir einen RDF Graph für diesen Artikel:
- Das Subjekt ist die URL des Artikels: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html".
- Das Objekt ordnet der Information eine Bedeutung zu, in unserem Fall "http://purl.org/dc/elements/1.1/Creator".
Um Eigenschaften zu definieren wird der Dienst PURL genutzt. PURL steht für Persistent Uniform Resource Locator. Das ist eine Verlinkung von einer URL auf eine URL. Dieser Dienst ist für URLs die in Büchern oder Zeitschriften veröffentlicht wurden. Denn nach ein paar Jahren kann der Link nicht mehr gültig sein und man kann so den Link auf eine andere Seite oder auf die neue URL der Seite setzen und so bleibt die URL im Buch gültig.
Don't say "color" say <http://example.com/2002/std6#col>Damit die Anwendungen unter den Eigenschaften immer das gleiche verstehen, hat die DCMI (Dublin Core Metadata Initiative) ein paar Standard-Terme mit PURLs verlinkt. Näheres finden Sie unter http://dublincore.org. Dies sind die vorher beschriebenen RDF-Schema.
- Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichtssagend ist, verlinken wir auf den Artikel im Forum, in dem ich mich beschreibe. Also tragen wir bei Objekt den folgenden Link ein: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html". Aber hier könnte auch ein Link auf einen XFN- (XHtml Friends Network) oder FOAF-(Friend-Of-A-Friend)Eintrag stehen.
Der RDF-Graph dazu sieht so aus.
RDF-Graphen werden mittels eines XML-Syntax beschrieben. Als Beispiel nehmen wir den gerade beschriebenen RDF-Graphen.
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:exterms="http://purl.org/dc/elements/1.1/"> 4. <rdf:Description rdf:about="http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html"> 5. <exterms:Creator>http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html</exterms:Creator> 6. </rdf:Description> 7. </rdf:RDF>- In der ersten Zeile wird nur definiert, welche XML-Version benutzt wird.
- Die zweite Zeile definiert den RDF-Namespace und alle tags die mit <rdf: beginnen sind Teil der RDF-Syntax.
- Die dritte Zeile ist auch eine Namespace-Deklaration und sagt aus, dass wir die Eigenschaften des DCMI benutzen, um unsere Graphen zu beschreiben.
- Die vierte Zeile ist die Ressource die beschrieben wird.
- Die fünfte Zeile beginnt mit dem tag exterms:Creator und ist die Eigenschaft. Der Term, der in dem tag eingeschlossen ist, ist das Objekt.
- Die sechste Zeile schließt die Description.
- Die siebte Zeile beendet unseren RDF-Graphen.
5.2 OWL
Die Web Ontology Language (OWL) ist eine Sprache zum Beschreiben von Ontologien, wobei sie sich in 3 Sprachebenen unterteilt. Mit OWL lassen sich Ausdrücke formulieren ähnlich der Prädikatenlogik. Die verschiedenen Ebenen unterscheiden sich in der Ausdrucksfähigkeit. OWL basiert auf den RDF-Syntax und DAML+OIL.
OWL Lite
OWL Light dient zum Beschreiben einfacher Taxonomien. Es sind die grundlegenden Funktionen zum Definieren von Klassen und Setzen von Abhängigkeiten.
OWL DL
DL steht für Description Logic (Beschreibungslogik) und ist gleichzusetzen mit der ersten Stufe der Prädikatenlogik.
OWL Full
OWL Full ermöglicht Ausdrücke aus Prädikatenlogiken höherer Stufe.
Hier ein Beispiel:
<owl:Class rdf:ID="WhiteWine"> <owl:intersectionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Wine" /> <owl:Restriction> <owl:onProperty rdf:resource="#hasColor" /> <owl:hasValue rdf:resource="#White" /> </owl:Restriction> </owl:intersectionOf> </owl:Class>Dies ist ein Beispiel für eine IntersectionOf-Abfrage. Es wird die „Collection“ auf Weißweine überprüft.
5.3 SWRL
SWRL steht für Semantic Web Rule Language und ist eine Zusammenführung von OWL Lite und OWL DL, nur dass hier die Lesbarkeit durch den Menschen im Vordergrund steht. Es lehnt sich dabei an EBNF (Extended-Backus-Naur-Form) in seiner Syntax an.
Der Syntax sieht so aus:
axiom ::= rule rule ::= 'Implies(' [ URIreference ] { annotation } antecedent consequent ')' antecedent ::= 'Antecedent(' { atom } ')' consequent ::= 'Consequent(' { atom } ')' atom ::= description '(' i-object ')' | dataRange '(' d-object ')' | individualvaluedPropertyID '(' i-object i-object ')' | datavaluedPropertyID '(' i-object d-object ')' | sameAs '(' i-object i-object ')' | differentFrom '(' i-object i-object ')' | builtIn '(' builtinID { d-object } ')' builtinID ::= URIreference i-object ::= i-variable | individualID d-object ::= d-variable | dataLiteral i-variable ::= 'I-variable(' URIreference ')' d-variable ::= 'D-variable(' URIreference ')'Der konkrete XML Syntax sieht so aus.
<swrlx:Ontology swrlx:name = xsd:anyURI > Content: (owlx:VersionInfo | owlx:PriorVersion | owlx:BackwardCompatibleWith | owlx:IncompatibleWith | owlx:Imports | owlx:Annotation | owlx:Class[axiom] | owlx:EnumeratedClass(D,F) | owlx:SubClassOf(D,F) | owlx:EquivalentClasses | owlx:DisjointClasses(D,F) | owlx:DatatypeProperty | owlx:ObjectProperty | owlx:SubPropertyOf | owlx:EquivalentProperties | owlx:Individual[axiom] | owlx:SameIndividual | owlx:DifferentIndividuals | ruleml:imp[axiom] | ruleml:var[axiom])* </swrlx:Ontology>5.4 SPARQL
SPARQL ist ein rekursives Akronym und steht für "SPARQL Protocol and RDF Query Language". Durch SPARQL wird die Aussage klar aus dem WWW eine globale Datenbank zu erstellen.
SPARQL ist eine Sprache um Informationen aus einem RDF-Graphen zu erhalten. Die Grundstruktur erinnert einen stark an SQL, da ein ähnlicher bzw. der Syntax darauf gebaut wurde.**???** Abfragen bestehen aus vier Grundbausteinen: einer PREFIX-Zeile in der Variablen definiert werden können, einer SELECT-Anweisung, in der die Datenbestände angegeben werden können, die durchsucht werden sollen, einer WHERE-Zeile in der ausgewählt wurde, welche Daten aus den vorher angegebenen Quellen extrahiert werden sollen.SPARQL ist eine Abfrage(query)sprache und dient nur dem Abfragen von Inhalten, im Gegensatz zu den Ontologie-Sprachen. Hier ein Beispiel, indem nach den Artikeln von „mosta“ gefragt wird:
PREFIX page: http://www.c-plusplus.net/forum/Artikel SELECT ?topic WHERE{ ?x page:topic ?mosta }6 Fazit
Im Großen und Ganzen ist es eine toll klingende Sache, wobei ich bisher die Nachteile wissentlich verschwiegen habe. Denn das Problem ist, dass man alle Inhalte selbst editieren muss. Das heißt, man muss selbst die Ontologien bauen. Diese Problematik wird sich aber mit der Zeit legen. Wenn es nämlich schon fertige "default" Ontologien gibt, die für uns dann das grundlegende Einsortieren übernehmen können. Bei den jetzigen Systemen läuft das aber alles per Fuß. Was sich in etwa wie die ersten Spracherkennungssoftware verhält, nur mit einer längeren „Trainingsphase“.
7 Referenzen
Das RFC zum URI-Standard
http://www.gbiv.com/protocols/uri/rfc/rfc3986.html
Das RDF-Schema Paper vom W3C
http://www.w3.org/TR/rdf-schema/
Der Artikel von Vannevar Bush
http://en.wikipedia.org/wiki/As_We_May_Think
Das SWRL Paper
http://www.w3.org/Submission/SWRL/
-
-
Schau mal noch in Kapitel 4 und 5.4, da habe ich je einen Satz markiert, den ich für unverständlich halte. Da fehlt irgendwie etwas.
Und dann noch etwas, was ich nicht verstehe:
Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichtssagend ist, verlinken wir auf den Artikel im Forum, in dem ich mich beschreibe. Also tragen wir bei Objekt den folgenden Link ein: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html".
Im vorigen Absatz hast du doch geschrieben, dass das Objekt "http://purl.org/dc/elements/1.1/Creator" wäre. Jetzt sagst du aber, dass es "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html" ist. Stimmt das so?
-
Semantic Desktop die nächste Evolution des Rechners?
-
1 Einleitung
-
2 Semantic Web
-
3 Geschichte
-
4 Was ist ein Semantic Desktop?
-
5 Technologien/Standards
-
5.1 RDF / RDF Schema
-
5.2 OWL
-
5.3 SWRL
-
5.4 SPARQL
-
6 Fazit
-
7 Referenzen
1 Einleitung
Das Internet revolutionierte die Art und Weise mit der wir kommunizieren. E-Mails, Instant Messenger(IM) und andere Dienste gehören zu unserem Alltag und dieser scheint immer schwerer ohne diese Anwendungen zu bewältigen zu sein. Doch das dadurch resultierende Informationsaufkommen lässt sich immer schwerer bändigen. Um dem entgegen zu wirken entstammt die Idee des Semantic Desktop.
Das Ziel des Semantic Desktop ist es, den Umgang mit und das Erstellen von Inhalten zu erleichtern und zu beschleunigen. Dies soll durch das Deklarieren von Inhalten geschehen. Es soll eine einheitliche Beschreibung von Informationen entstehen. Dies bezieht sich nicht auf die Inhalte, sondern dass wir Sie für den Computer verständlich beschreiben. Dies geschieht wie bei MP3-Tags, nur dass das System nicht auf Audio-Daten beschränkt ist.
Da der Semantic Desktop eine Implementierung von Semantic-Web-Technologien auf den Desktop ist, wird als erstes die Idee des Semantic Web beschrieben und es wird dann näher auf den Semantic Desktop eingegangen.2 Semantic Web
Das Ziel des Semantic Web ist es, das Web für den Computer benutzbar zu machen.
Zurzeit funktioniert das Web über Hyperlinks. Die Seiten werden mit Hyperlinks miteinander verbunden und man kann so durch das Web navigieren. Diese Art des Vernetzens verteilt die Aufgabe, Verbindungen zu setzen, auf den Anbieter bzw. Erzeuger von Informationen. Das birgt die Problematik, dass Informationen verschwinden bzw. nicht wieder gefunden werden können, da man den Pfad kennen muss, der zu der Information führt. Dieses Problem ist schon lange bekannt und die derzeitige Lösungsstrategie sind Suchmaschinen. Doch deren Funktion ist durch Spammer und der riesigen Informationsflut mittlerweile sehr eingeschränkt und mit immer steigendem Aufwand zu gebrauchen.
Die Strategie des Semantic Web ist es, den Seiten selbst oder in Datenbanken Meta-Information anzufügen, die Aussagen über die Information beinhalten, wie Autor, Thema, Themengebiete und andere Angaben, die zu der Website passen. Dies führt zu einer Art Weltwissen, einem System, das eine Repräsentation des menschlichen Wissens darstellt und das in einer Ontologie strukturiert wird.Dafür gliedert sich das Semantic Web in 4 Ebenen auf.
- 1. Ebene: korrekte Darstellung von Inhalten
Hier sind Standards definiert die ein medienneutrale (uniformierte) Darstellung erlauben. Als Keycode liegt das Unicode-Format vor.
Zur Speicherung wird das XML-Format verwendet, das eine medien- und sprachneutrale Darstellung ermöglicht.
Das Referenzieren von Ressourcen geschieht mittels URIs (Der bekannteste Identifier ist der Locator [URL]). URIs können wie folgt aussehen:ftp://ftp.is.co.za/rfc/rfc1808.txt http://www.ietf.org/rfc/rfc2396.txt ldap://[2001:db8::7]/c=GB?objectClass?one mailto:John.Doe@example.com news:comp.infosystems.www.servers.unix tel:+1-816-555-1212 telnet://192.0.2.16:80/ urn:oasis:names:specification:docbook:dtd:xml:4.1.2Es werden zwar einige dieser Protokolle nicht im Semantic Web benutzt, aber es ist sinnvoll, wenn man das in Verbindung mit dem Semantic Desktop betrachtet. Die erste Ebene ist damit die direkte Schnittstelle zum „alten“ Web.
- 2. Ebene: RDF-Graphen
Hier beginnt eigentlich das Semantic Web. Denn hier beschreiben wir unsere Inhalte. Also ihnen wird eine Bedeutung (Semantic) zugeordnet. Dafür wird RDF benutzt, das ich später beschreiben werde. [siehe RDF-Kapitel]
- 3. Ebene: RDF-Schema
Das RDF-Schema dient zum Beschreiben von RDF-Triples. Das RDF-Klassen- und Beziehungssystem ist ähnlich dem Typensystem von objektorientierten Programmiersprachen. Es unterscheidet sich darin, dass die Definition einer Klasse im RDF-Vokabular nicht durch Attribute und deren Typen gestaltet wird, sondern durch die Terme auf die sich die Ressourcen beziehen.
Diese RDF-Triples definieren Regeln bzw. Aussagen wie:
Tür -> subclass -> Auto Tür -> Typ -> Material Material -> Typ -> Metall VW Käfer -> Typ -> AutoSo können Beziehungen zwischen den Inhalten auf den Seiten gesetzt werden. Wobei die Beziehungen auch auf Teile der Seite oder Absätze bezogen werden können. Dadurch können aus diesen Textbausteinen Texte erstellt werden.
- 4. Ebene: Ontologien
In dieser Ebene wird es richtig spannend. Denn in dieser Ebene können wir auf einheitliche beschriebene Inhalte mit gleichem Vokabular zugreifen. In dieser Ebene werden Ontologien erstellt. Also es werden die in der vorherigen Ebene definierten Regeln hierarchisch organisiert. Wenn wir das auf unser Beispiel beziehen, können wir folgende Frage beantworten und zwar "Aus was besteht die Tür eines VW Käfer?". Da wir wissen, dass der Käfer ein Auto ist und ein Auto eine Tür hat und eine Tür aus Material besteht und Metall ein Material ist, können wir sagen das die Tür des Käfers aus Metall besteht. Um sich das zu vereinfachen, kann man das als eine relationale Datenbank betrachten, nur dass hier noch ein Objektmodell dazu gekommen ist. Man kann also Tabellen als Typ angeben bei der Deklaration der Tabellenspalten.
- Verifizieren
Zum Verifizieren von Daten werden Signaturen und Verschlüsselungsverfahren genutzt, die die Echtheit der Daten gewährleisten.
3. Geschichte
Bevor wir uns ins Technische begeben, ist erst einmal eine kleine Geschichtsstunde angesetzt. Denn es ist schon interessant zu wissen woher diese Ideen stammen.
Die erste Beschreibung des Semantic Desktop, geschah 1945 durch Vannevar Bush in dem Artikel “As we may think”(Man glaubt es kaum ein Vorfahre von George W. Bush). Er beschrieb ein Gerät namens “Memex”, das alle Aufzeichnungen - Text, Bild und Ton - seines Benutzers speichern kann und alle Kommunikationsmittel vereint. Das bewältigt dieses Gerät sehr schnell und für den Benutzer sehr intuitiv. Das Gerät sollte aber völlig analog funktionieren und Mikrofilm als Speichermedium nutzen. Weitere Wurzeln findet man bei Ted Nelson, der 1960 ein System beschrieb, das aus verknüpften Informationen bestand, die in einer Informationsgesellschaft gehandelt wurden. Er nannte das System "Xanadu". Der erste Versuch solch ein System umzusetzen fand durch Tim Berners-Lee (Begründer des Internet) statt, der sein Programm "Enquire-Within-Upon-Everything" nannte (wobei der Name alles sagt), das in der Lage war, Informationen über Personen, Projekte, Hardwareressourcen und wie sie miteinander verknüpft waren, zu beschreiben. Es sollte die Dokumentationen, die am CERN zu der Zeit geschrieben wurden, strukturieren und einfacher zugänglich machen. Es fand aber keinen Anklang.Als nächstes folgt das Semantic Web, das 1998 von Tim Berners-Lee eingeführt wurde. Er fordert eine Stärkung der Nutzbarkeit der Daten und arbeitet auch an den entsprechenden Standards wie RDF mit.
Der Begriff Semantic Desktop wurde durch Stefan Decken beschrieben und von Leo Sauermann 2003 aufgegriffen, um die verschiedenen Technologien und Ideen in einem Hauptbegriff zusammenzufassen. Wobei Stefan Decker und Martin Frank den Begriff Networked Semantic Desktop 2004 formulierten, was den Semantic Desktop um eine P2P-Funktion erweitert in der die Ontologien untereinander getauscht werden können.
4 Was ist ein Semantic Desktop?
Die Definition des Semantik Desktop leitet sich aus den Beschreibungen von Vannevar Bush ab. Da er aber ein analoges System beschrieb, wurde die Definition nach ihrer technischen Realisierung angepasst.
Daraus ergibt sich ein Schlachtplan ergibt sich ähnlich dem Semantic Web Paper[roadmap] von Tim-Berners-Lee.Ein Semantic Desktop (SD) ist ein Gerät, das in der Lage ist, alle digitalen Informationen seines Benutzers zu speichern. Diese werden als Semantic-Web-Ressourcen interpretiert und als RDF-Graphen gespeichert. Ressourcen aus dem Web können gespeichert, bearbeitet und der Inhalt kann mit anderen Benutzern geteilt werden.
Ontologien repräsentieren das persönliche mentale Modell seines Benutzers. Sie stellen damit den „Klebstoff“ zwischen Informationen und dem „System“ dar. Anwendungen eines Semantic Desktop speichern, lesen und kommunizieren via Ontologien und Semantic-Web-Protokollen. Dadurch ist der Semantic Desktop eine Erweiterung des Gedächtnisses seines Benutzers.Wenn man es grob zusammenfassen möchte, wäre ein Semantic Desktop ein lokales Semantic Web. Der Unterschied ist aber, dass man hier nicht eine riesige "relationale" Datenbank anstrebt, sondern das Entwickeln von Anwendungen die diese Daten auswerten und aufbereiten können.
Es werden Programme nicht mehr ein Problem lösen, sondern eher in einem Verbund miteinander kommunizieren. Es werden also intelligentere Anwendungen angestrebt, die sich mehr auf seinen Benutzer anpassen und ihm ständig wiederkehrende Arbeiten, wie das Sortieren von Dateien, abnehmen, da sie nach ihrer Bedeutung strukturiert werden. Man spricht in diesem Zusammenhang auch von Software-Agenten.Die ersten Versuche solcher Systeme laufen schon. Es gibt einmal das Smart-Web-Projekt des DFKI. Das eine Software für mobile Endgeräte ist, die durch Sprach- und Tastatureingaben gesteuert werden kann. Es ist aber nur möglich, Fragen zu stellen und auch nur zu bestimmten Themengebieten. Was aber trotzdem beeindruckend ist, weil es eine Aussicht ist, auf weiterführende Projekte ist, wie die nächsten.
Das DFKI hat noch ein zweites Projekt, und zwar gnowsis das ein Semantic-Desktop-System darstellt. Im Mittelpunkt steht ein Web-Server der die Handhabung der Ontologie übernimmt. Gnowsis bietet ein Framework zur Anbindung an bestehende Softwarelösungen an. Es wird versucht, die Inhalte aus diesen Anwendungen zu nutzen und in der Ontologie im Server abzubilden.
Als weiteres Projekt zu erwähnen ist haystack vom MIT, das ein E-Mail-Client, Adressbuch, Kalender und Dateisystem ist. Im Gegensatz zum gnowsis-Projekt wird hier nicht ein Framework mit Pipelines zu Anwendungen realisiert, sondern ein einheitliches System.5 Technologien/Standards:
Hier werden die Techniken genauer beleuchtet, die in der Einleitung erwähnt wurden.
5.1 RDF - Resource Description Framework
Das Ressource Description Framework ist eine Sprache um Informationen über Ressourcen im Internet darzustellen. Streng genommen ist es keine eigene Sprache, sondern ein XML-Dialekt. Es geht aber hier um die Darstellung von Metadaten, also um Informationen über Informationen, was im ersten Moment etwas schizophren klingt. Es geht aber in diesem Fall um Informationen wie der Autor eines Textes oder die Art des Textes. Man kann das natürlich auch auf andere Informationen wie Musik, Video oder jede andere Ressource beziehen. Dabei können die Informationen variieren. Definiert wurde Sie aber um zusätzliche Informationen über Web-Dokumente zu definieren und sie maschinell verarbeiten zu können. RDF ist konzipiert um diese Art von Informationen zwischen Anwendungen auszutauschen ohne den Verlust der Bedeutung. Dabei werden Informationen mittels URIs identifiziert und beschrieben.
RDF ist wie folgt aufgebaut. Es besteht aus drei Objekttypen, den Ressourcen, Eigenschaftselementen und den Objekten, die auch als Subjekt, Objekt und Prädikat beschrieben werden. Durch Kombination der drei Typen wird eine Aussage über eine Ressource formuliert. Um das ganze anschaulich zu machen beschreiben wir einen RDF Graph für diesen Artikel:
- Das Subjekt ist die URL des Artikels: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html".
- Das Objekt ordnet der Information eine Bedeutung zu, in unserem Fall "http://purl.org/dc/elements/1.1/Creator".
Um Eigenschaften zu definieren wird der Dienst PURL genutzt. PURL steht für Persistent Uniform Resource Locator. Das ist eine Verlinkung von einer URL auf eine URL. Dieser Dienst ist für URLs die in Büchern oder Zeitschriften veröffentlicht wurden. Denn nach ein paar Jahren kann der Link nicht mehr gültig sein und man kann so den Link auf eine andere Seite oder auf die neue URL der Seite setzen und so bleibt die URL im Buch gültig.
Don't say "color" say <http://example.com/2002/std6#col>Damit die Anwendungen unter den Eigenschaften immer das gleiche verstehen, hat die DCMI (Dublin Core Metadata Initiative) ein paar Standard-Terme mit PURLs verlinkt. Näheres finden Sie unter http://dublincore.org. Dies sind die vorher beschriebenen RDF-Schema.
- Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichtssagend ist, verlinken wir auf den Artikel im Forum, in dem ich mich beschreibe. Also tragen wir bei Prädikat den folgenden Link ein: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html". Aber hier könnte auch ein Link auf einen XFN- (XHtml Friends Network) oder FOAF-(Friend-Of-A-Friend)Eintrag stehen.
Der RDF-Graph dazu sieht so aus.
RDF-Graphen werden mittels eines XML-Syntax beschrieben. Als Beispiel nehmen wir den gerade beschriebenen RDF-Graphen.
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:exterms="http://purl.org/dc/elements/1.1/"> 4. <rdf:Description rdf:about="http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html"> 5. <exterms:Creator>http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html</exterms:Creator> 6. </rdf:Description> 7. </rdf:RDF>- In der ersten Zeile wird nur definiert, welche XML-Version benutzt wird.
- Die zweite Zeile definiert den RDF-Namespace und alle tags die mit <rdf: beginnen sind Teil der RDF-Syntax.
- Die dritte Zeile ist auch eine Namespace-Deklaration und sagt aus, dass wir die Eigenschaften des DCMI benutzen, um unsere Graphen zu beschreiben.
- Die vierte Zeile ist die Ressource die beschrieben wird.
- Die fünfte Zeile beginnt mit dem tag exterms:Creator und ist die Eigenschaft. Der Term, der in dem tag eingeschlossen ist, ist das Objekt.
- Die sechste Zeile schließt die Description.
- Die siebte Zeile beendet unseren RDF-Graphen.
5.2 OWL
Die Web Ontology Language (OWL) ist eine Sprache zum Beschreiben von Ontologien, wobei sie sich in 3 Sprachebenen unterteilt. Mit OWL lassen sich Ausdrücke formulieren ähnlich der Prädikatenlogik. Die verschiedenen Ebenen unterscheiden sich in der Ausdrucksfähigkeit. OWL basiert auf den RDF-Syntax und DAML+OIL.
OWL Lite
OWL Light dient zum Beschreiben einfacher Taxonomien. Es sind die grundlegenden Funktionen zum Definieren von Klassen und Setzen von Abhängigkeiten.
OWL DL
DL steht für Description Logic (Beschreibungslogik) und ist gleichzusetzen mit der ersten Stufe der Prädikatenlogik.
OWL Full
OWL Full ermöglicht Ausdrücke aus Prädikatenlogiken höherer Stufe.
Hier ein Beispiel:
<owl:Class rdf:ID="WhiteWine"> <owl:intersectionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Wine" /> <owl:Restriction> <owl:onProperty rdf:resource="#hasColor" /> <owl:hasValue rdf:resource="#White" /> </owl:Restriction> </owl:intersectionOf> </owl:Class>Dies ist ein Beispiel für eine IntersectionOf-Abfrage. Es wird die „Collection“ auf Weißweine überprüft.
5.3 SWRL
SWRL steht für Semantic Web Rule Language und ist eine Zusammenführung von OWL Lite und OWL DL, nur dass hier die Lesbarkeit durch den Menschen im Vordergrund steht. Es lehnt sich dabei an EBNF (Extended-Backus-Naur-Form) in seiner Syntax an.
Der Syntax sieht so aus:
axiom ::= rule rule ::= 'Implies(' [ URIreference ] { annotation } antecedent consequent ')' antecedent ::= 'Antecedent(' { atom } ')' consequent ::= 'Consequent(' { atom } ')' atom ::= description '(' i-object ')' | dataRange '(' d-object ')' | individualvaluedPropertyID '(' i-object i-object ')' | datavaluedPropertyID '(' i-object d-object ')' | sameAs '(' i-object i-object ')' | differentFrom '(' i-object i-object ')' | builtIn '(' builtinID { d-object } ')' builtinID ::= URIreference i-object ::= i-variable | individualID d-object ::= d-variable | dataLiteral i-variable ::= 'I-variable(' URIreference ')' d-variable ::= 'D-variable(' URIreference ')'Der konkrete XML Syntax sieht so aus.
<swrlx:Ontology swrlx:name = xsd:anyURI > Content: (owlx:VersionInfo | owlx:PriorVersion | owlx:BackwardCompatibleWith | owlx:IncompatibleWith | owlx:Imports | owlx:Annotation | owlx:Class[axiom] | owlx:EnumeratedClass(D,F) | owlx:SubClassOf(D,F) | owlx:EquivalentClasses | owlx:DisjointClasses(D,F) | owlx:DatatypeProperty | owlx:ObjectProperty | owlx:SubPropertyOf | owlx:EquivalentProperties | owlx:Individual[axiom] | owlx:SameIndividual | owlx:DifferentIndividuals | ruleml:imp[axiom] | ruleml:var[axiom])* </swrlx:Ontology>5.4 SPARQL
SPARQL ist ein rekursives Akronym und steht für "SPARQL Protocol and RDF Query Language". Durch SPARQL wird die Aussage klar aus dem WWW eine globale Datenbank zu erstellen.
SPARQL ist eine Sprache um Informationen aus einem RDF-Graphen zu erhalten. Die Grundstruktur erinnert einen stark an SQL, da ein ähnlicher Syntax benutzt wurde bzw. der Syntax darauf aufgebaut wurde. Abfragen bestehen aus vier Grundbausteinen: einer PREFIX-Zeile in der Variablen definiert werden können, einer SELECT-Anweisung, in der die Datenbestände angegeben werden können, die durchsucht werden sollen, einer WHERE-Zeile in der ausgewählt wurde, welche Daten aus den vorher angegebenen Quellen extrahiert werden sollen.SPARQL ist eine Abfrage(query)sprache und dient nur dem Abfragen von Inhalten, im Gegensatz zu den Ontologie-Sprachen. Hier ein Beispiel, indem nach den Artikeln von „mosta“ gefragt wird:
PREFIX page: http://www.c-plusplus.net/forum/Artikel SELECT ?topic WHERE{ ?x page:topic ?mosta }6 Fazit
Im Großen und Ganzen ist es eine toll klingende Sache, wobei ich bisher die Nachteile wissentlich verschwiegen habe. Denn das Problem ist, dass man alle Inhalte selbst editieren muss. Das heißt, man muss selbst die Ontologien bauen. Diese Problematik wird sich aber mit der Zeit legen. Wenn es nämlich schon fertige "default" Ontologien gibt, die für uns dann das grundlegende Einsortieren übernehmen können. Bei den jetzigen Systemen läuft das aber alles per Fuß. Was sich in etwa wie die ersten Spracherkennungssoftware verhält, nur mit einer längeren „Trainingsphase“.
7 Referenzen
Das RFC zum URI-Standard
http://www.gbiv.com/protocols/uri/rfc/rfc3986.html
Das RDF-Schema Paper vom W3C
http://www.w3.org/TR/rdf-schema/
Der Artikel von Vannevar Bush
http://en.wikipedia.org/wiki/As_We_May_Think
Das SWRL Paper
http://www.w3.org/Submission/SWRL/
-
-
-predator- schrieb:
Schau mal noch in Kapitel 4 und 5.4, da habe ich je einen Satz markiert, den ich für unverständlich halte. Da fehlt irgendwie etwas.
done
-predator- schrieb:
Und dann noch etwas, was ich nicht verstehe:
Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichtssagend ist, verlinken wir auf den Artikel im Forum, in dem ich mich beschreibe. Also tragen wir bei Objekt den folgenden Link ein: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html".
Im vorigen Absatz hast du doch geschrieben, dass das Objekt "http://purl.org/dc/elements/1.1/Creator" wäre. Jetzt sagst du aber, dass es "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html" ist. Stimmt das so?
da hab ich mich verschrieben das heißt natürlich Prädikat.
kuck es dir nochmal an, wenn nichts mehr falsch ist stell ich den artikel auf fertig um.
Ach was ich noch wissen wollte ist wie liest sich der Artikel?
-
Daraus ergibt sich ein Schlachtplan ergibt sich ähnlich dem Semantic Web Paper[roadmap] von Tim-Berners-Lee.
Nochmal bitte
-
Semantic Desktop - die nächste Evolution des Rechners?
-
1 Einleitung
-
2 Semantic Web
-
3 Geschichte
-
4 Was ist ein Semantic Desktop?
-
5 Technologien/Standards
-
5.1 RDF / RDF Schema
-
5.2 OWL
-
5.3 SWRL
-
5.4 SPARQL
-
6 Fazit
-
7 Referenzen
1 Einleitung
Das Internet revolutionierte die Art und Weise mit der wir kommunizieren. E-Mails, Instant Messenger(IM) und andere Dienste gehören zu unserem Alltag und dieser scheint immer schwerer ohne diese Anwendungen zu bewältigen zu sein. Doch das dadurch resultierende Informationsaufkommen lässt sich immer schwerer bändigen. Um dem entgegen zu wirken entstammt die Idee des Semantic Desktop.
Das Ziel des Semantic Desktop ist es, den Umgang mit und das Erstellen von Inhalten zu erleichtern und zu beschleunigen. Dies soll durch das Deklarieren von Inhalten geschehen. Es soll eine einheitliche Beschreibung von Informationen entstehen. Dies bezieht sich nicht auf die Inhalte, sondern dass wir Sie für den Computer verständlich beschreiben. Dies geschieht wie bei MP3-Tags, nur dass das System nicht auf Audio-Daten beschränkt ist.
Da der Semantic Desktop eine Implementierung von Semantic-Web-Technologien auf den Desktop ist, wird als erstes die Idee des Semantic Web beschrieben und es wird dann näher auf den Semantic Desktop eingegangen.2 Semantic Web
Das Ziel des Semantic Web ist es, das Web für den Computer benutzbar zu machen.
Zurzeit funktioniert das Web über Hyperlinks. Die Seiten werden mit Hyperlinks miteinander verbunden und man kann so durch das Web navigieren. Diese Art des Vernetzens verteilt die Aufgabe, Verbindungen zu setzen, auf den Anbieter bzw. Erzeuger von Informationen. Das birgt die Problematik, dass Informationen verschwinden bzw. nicht wieder gefunden werden können, da man den Pfad kennen muss, der zu der Information führt. Dieses Problem ist schon lange bekannt und die derzeitige Lösungsstrategie sind Suchmaschinen. Doch deren Funktion ist durch Spammer und der riesigen Informationsflut mittlerweile sehr eingeschränkt und mit immer steigendem Aufwand zu gebrauchen.
Die Strategie des Semantic Web ist es, den Seiten selbst oder in Datenbanken Meta-Information anzufügen, die Aussagen über die Information beinhalten, wie Autor, Thema, Themengebiete und andere Angaben, die zu der Website passen. Dies führt zu einer Art Weltwissen, einem System, das eine Repräsentation des menschlichen Wissens darstellt und das in einer Ontologie strukturiert wird.Dafür gliedert sich das Semantic Web in 4 Ebenen auf.
- 1. Ebene: korrekte Darstellung von Inhalten
Hier sind Standards definiert die ein medienneutrale (uniformierte) Darstellung erlauben. Als Keycode liegt das Unicode-Format vor.
Zur Speicherung wird das XML-Format verwendet, das eine medien- und sprachneutrale Darstellung ermöglicht.
Das Referenzieren von Ressourcen geschieht mittels URIs (Der bekannteste Identifier ist der Locator [URL]). URIs können wie folgt aussehen:ftp://ftp.is.co.za/rfc/rfc1808.txt http://www.ietf.org/rfc/rfc2396.txt ldap://[2001:db8::7]/c=GB?objectClass?one mailto:John.Doe@example.com news:comp.infosystems.www.servers.unix tel:+1-816-555-1212 telnet://192.0.2.16:80/ urn:oasis:names:specification:docbook:dtd:xml:4.1.2Es werden zwar einige dieser Protokolle nicht im Semantic Web benutzt, aber es ist sinnvoll, wenn man das in Verbindung mit dem Semantic Desktop betrachtet. Die erste Ebene ist damit die direkte Schnittstelle zum „alten“ Web.
- 2. Ebene: RDF-Graphen
Hier beginnt eigentlich das Semantic Web. Denn hier beschreiben wir unsere Inhalte. Also ihnen wird eine Bedeutung (Semantic) zugeordnet. Dafür wird RDF benutzt, das ich später beschreiben werde. [siehe RDF-Kapitel]
- 3. Ebene: RDF-Schema
Das RDF-Schema dient zum Beschreiben von RDF-Triples. Das RDF-Klassen- und Beziehungssystem ist ähnlich dem Typensystem von objektorientierten Programmiersprachen. Es unterscheidet sich darin, dass die Definition einer Klasse im RDF-Vokabular nicht durch Attribute und deren Typen gestaltet wird, sondern durch die Terme auf die sich die Ressourcen beziehen.
Diese RDF-Triples definieren Regeln bzw. Aussagen wie:
Tür -> subclass -> Auto Tür -> Typ -> Material Material -> Typ -> Metall VW Käfer -> Typ -> AutoSo können Beziehungen zwischen den Inhalten auf den Seiten gesetzt werden. Wobei die Beziehungen auch auf Teile der Seite oder Absätze bezogen werden können. Dadurch können aus diesen Textbausteinen Texte erstellt werden.
- 4. Ebene: Ontologien
In dieser Ebene wird es richtig spannend. Denn in dieser Ebene können wir auf einheitliche beschriebene Inhalte mit gleichem Vokabular zugreifen. In dieser Ebene werden Ontologien erstellt. Also es werden die in der vorherigen Ebene definierten Regeln hierarchisch organisiert. Wenn wir das auf unser Beispiel beziehen, können wir folgende Frage beantworten und zwar "Aus was besteht die Tür eines VW Käfer?". Da wir wissen, dass der Käfer ein Auto ist und ein Auto eine Tür hat und eine Tür aus Material besteht und Metall ein Material ist, können wir sagen das die Tür des Käfers aus Metall besteht. Um sich das zu vereinfachen, kann man das als eine relationale Datenbank betrachten, nur dass hier noch ein Objektmodell dazu gekommen ist. Man kann also Tabellen als Typ angeben bei der Deklaration der Tabellenspalten.
- Verifizieren
Zum Verifizieren von Daten werden Signaturen und Verschlüsselungsverfahren genutzt, die die Echtheit der Daten gewährleisten.
3 Geschichte
Bevor wir uns ins Technische begeben, ist erst einmal eine kleine Geschichtsstunde angesetzt. Denn es ist schon interessant zu wissen woher diese Ideen stammen.
Die erste Beschreibung des Semantic Desktop, geschah 1945 durch Vannevar Bush in dem Artikel “As we may think”(Man glaubt es kaum ein Vorfahre von George W. Bush). Er beschrieb ein Gerät namens “Memex”, das alle Aufzeichnungen - Text, Bild und Ton - seines Benutzers speichern kann und alle Kommunikationsmittel vereint. Das bewältigt dieses Gerät sehr schnell und für den Benutzer sehr intuitiv. Das Gerät sollte aber völlig analog funktionieren und Mikrofilm als Speichermedium nutzen. Weitere Wurzeln findet man bei Ted Nelson, der 1960 ein System beschrieb, das aus verknüpften Informationen bestand, die in einer Informationsgesellschaft gehandelt wurden. Er nannte das System "Xanadu". Der erste Versuch solch ein System umzusetzen fand durch Tim Berners-Lee (Begründer des Internet) statt, der sein Programm "Enquire-Within-Upon-Everything" nannte (wobei der Name alles sagt), das in der Lage war, Informationen über Personen, Projekte, Hardwareressourcen und wie sie miteinander verknüpft waren, zu beschreiben. Es sollte die Dokumentationen, die am CERN zu der Zeit geschrieben wurden, strukturieren und einfacher zugänglich machen. Es fand aber keinen Anklang.Als nächstes folgt das Semantic Web, das 1998 von Tim Berners-Lee eingeführt wurde. Er fordert eine Stärkung der Nutzbarkeit der Daten und arbeitet auch an den entsprechenden Standards wie RDF mit.
Der Begriff Semantic Desktop wurde durch Stefan Decken beschrieben und von Leo Sauermann 2003 aufgegriffen, um die verschiedenen Technologien und Ideen in einem Hauptbegriff zusammenzufassen. Wobei Stefan Decker und Martin Frank den Begriff Networked Semantic Desktop 2004 formulierten, was den Semantic Desktop um eine P2P-Funktion erweitert in der die Ontologien untereinander getauscht werden können.
4 Was ist ein Semantic Desktop?
Die Definition des Semantik Desktop leitet sich aus den Beschreibungen von Vannevar Bush ab. Da er aber ein analoges System beschrieb, wurde die Definition nach ihrer technischen Realisierung angepasst.
Daraus ergibt sich ein Schlachtplan ähnlich dem Semantic Web Paper[roadmap] von Tim Berners-Lee.Ein Semantic Desktop (SD) ist ein Gerät, das in der Lage ist, alle digitalen Informationen seines Benutzers zu speichern. Diese werden als Semantic-Web-Ressourcen interpretiert und als RDF-Graphen gespeichert. Ressourcen aus dem Web können gespeichert, bearbeitet und der Inhalt kann mit anderen Benutzern geteilt werden.
Ontologien repräsentieren das persönliche mentale Modell seines Benutzers. Sie stellen damit den „Klebstoff“ zwischen Informationen und dem „System“ dar. Anwendungen eines Semantic Desktop speichern, lesen und kommunizieren via Ontologien und Semantic-Web-Protokollen. Dadurch ist der Semantic Desktop eine Erweiterung des Gedächtnisses seines Benutzers.Wenn man es grob zusammenfassen möchte, wäre ein Semantic Desktop ein lokales Semantic Web. Der Unterschied ist aber, dass man hier nicht eine riesige "relationale" Datenbank anstrebt, sondern das Entwickeln von Anwendungen die diese Daten auswerten und aufbereiten können.
Es werden Programme nicht mehr ein Problem lösen, sondern eher in einem Verbund miteinander kommunizieren. Es werden also intelligentere Anwendungen angestrebt, die sich mehr auf seinen Benutzer anpassen und ihm ständig wiederkehrende Arbeiten, wie das Sortieren von Dateien, abnehmen, da sie nach ihrer Bedeutung strukturiert werden. Man spricht in diesem Zusammenhang auch von Software-Agenten.Die ersten Versuche solcher Systeme laufen schon. Es gibt einmal das Smart-Web-Projekt des DFKI. Das eine Software für mobile Endgeräte ist, die durch Sprach- und Tastatureingaben gesteuert werden kann. Es ist aber nur möglich, Fragen zu stellen und auch nur zu bestimmten Themengebieten. Was aber trotzdem beeindruckend ist, weil es eine Aussicht ist, auf weiterführende Projekte ist, wie die nächsten.
Das DFKI hat noch ein zweites Projekt, und zwar gnowsis das ein Semantic-Desktop-System darstellt. Im Mittelpunkt steht ein Web-Server der die Handhabung der Ontologie übernimmt. Gnowsis bietet ein Framework zur Anbindung an bestehende Softwarelösungen an. Es wird versucht, die Inhalte aus diesen Anwendungen zu nutzen und in der Ontologie im Server abzubilden.
Als weiteres Projekt zu erwähnen ist haystack vom MIT, das ein E-Mail-Client, Adressbuch, Kalender und Dateisystem ist. Im Gegensatz zum gnowsis-Projekt wird hier nicht ein Framework mit Pipelines zu Anwendungen realisiert, sondern ein einheitliches System.5 Technologien/Standards:
Hier werden die Techniken genauer beleuchtet, die in der Einleitung erwähnt wurden.
5.1 RDF - Resource Description Framework
Das Ressource Description Framework ist eine Sprache um Informationen über Ressourcen im Internet darzustellen. Streng genommen ist es keine eigene Sprache, sondern ein XML-Dialekt. Es geht aber hier um die Darstellung von Metadaten, also um Informationen über Informationen, was im ersten Moment etwas schizophren klingt. Es geht aber in diesem Fall um Informationen wie der Autor eines Textes oder die Art des Textes. Man kann das natürlich auch auf andere Informationen wie Musik, Video oder jede andere Ressource beziehen. Dabei können die Informationen variieren. Definiert wurde Sie aber um zusätzliche Informationen über Web-Dokumente zu definieren und sie maschinell verarbeiten zu können. RDF ist konzipiert um diese Art von Informationen zwischen Anwendungen auszutauschen ohne den Verlust der Bedeutung. Dabei werden Informationen mittels URIs identifiziert und beschrieben.
RDF ist wie folgt aufgebaut. Es besteht aus drei Objekttypen, den Ressourcen, Eigenschaftselementen und den Objekten, die auch als Subjekt, Objekt und Prädikat beschrieben werden. Durch Kombination der drei Typen wird eine Aussage über eine Ressource formuliert. Um das ganze anschaulich zu machen beschreiben wir einen RDF Graph für diesen Artikel:
- Das Subjekt ist die URL des Artikels: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html".
- Das Objekt ordnet der Information eine Bedeutung zu, in unserem Fall "http://purl.org/dc/elements/1.1/Creator".
Um Eigenschaften zu definieren wird der Dienst PURL genutzt. PURL steht für Persistent Uniform Resource Locator. Das ist eine Verlinkung von einer URL auf eine URL. Dieser Dienst ist für URLs die in Büchern oder Zeitschriften veröffentlicht wurden. Denn nach ein paar Jahren kann der Link nicht mehr gültig sein und man kann so den Link auf eine andere Seite oder auf die neue URL der Seite setzen und so bleibt die URL im Buch gültig.
Don't say "color" say <http://example.com/2002/std6#col>Damit die Anwendungen unter den Eigenschaften immer das gleiche verstehen, hat die DCMI (Dublin Core Metadata Initiative) ein paar Standard-Terme mit PURLs verlinkt. Näheres finden Sie unter http://dublincore.org. Dies sind die vorher beschriebenen RDF-Schema.
- Das Prädikat ist der Autor "mosta". Da aber der Nick sehr nichtssagend ist, verlinken wir auf den Artikel im Forum, in dem ich mich beschreibe. Also tragen wir bei Prädikat den folgenden Link ein: "http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html". Aber hier könnte auch ein Link auf einen XFN- (XHtml Friends Network) oder FOAF-(Friend-Of-A-Friend)Eintrag stehen.
Der RDF-Graph dazu sieht so aus.
RDF-Graphen werden mittels eines XML-Syntax beschrieben. Als Beispiel nehmen wir den gerade beschriebenen RDF-Graphen.
1. <?xml version="1.0"?> 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 3. xmlns:exterms="http://purl.org/dc/elements/1.1/"> 4. <rdf:Description rdf:about="http://www.c-plusplus.net/forum/viewtopic-var-t-is-136407.html"> 5. <exterms:Creator>http://www.c-plusplus.net/forum/viewtopic-var-t-is-139119.html</exterms:Creator> 6. </rdf:Description> 7. </rdf:RDF>- In der ersten Zeile wird nur definiert, welche XML-Version benutzt wird.
- Die zweite Zeile definiert den RDF-Namespace und alle tags die mit <rdf: beginnen sind Teil der RDF-Syntax.
- Die dritte Zeile ist auch eine Namespace-Deklaration und sagt aus, dass wir die Eigenschaften des DCMI benutzen, um unsere Graphen zu beschreiben.
- Die vierte Zeile ist die Ressource die beschrieben wird.
- Die fünfte Zeile beginnt mit dem tag exterms:Creator und ist die Eigenschaft. Der Term, der in dem tag eingeschlossen ist, ist das Objekt.
- Die sechste Zeile schließt die Description.
- Die siebte Zeile beendet unseren RDF-Graphen.
5.2 OWL
Die Web Ontology Language (OWL) ist eine Sprache zum Beschreiben von Ontologien, wobei sie sich in 3 Sprachebenen unterteilt. Mit OWL lassen sich Ausdrücke formulieren ähnlich der Prädikatenlogik. Die verschiedenen Ebenen unterscheiden sich in der Ausdrucksfähigkeit. OWL basiert auf den RDF-Syntax und DAML+OIL.
OWL Lite
OWL Light dient zum Beschreiben einfacher Taxonomien. Es sind die grundlegenden Funktionen zum Definieren von Klassen und Setzen von Abhängigkeiten.
OWL DL
DL steht für Description Logic (Beschreibungslogik) und ist gleichzusetzen mit der ersten Stufe der Prädikatenlogik.
OWL Full
OWL Full ermöglicht Ausdrücke aus Prädikatenlogiken höherer Stufe.
Hier ein Beispiel:
<owl:Class rdf:ID="WhiteWine"> <owl:intersectionOf rdf:parseType="Collection"> <owl:Class rdf:about="#Wine" /> <owl:Restriction> <owl:onProperty rdf:resource="#hasColor" /> <owl:hasValue rdf:resource="#White" /> </owl:Restriction> </owl:intersectionOf> </owl:Class>Dies ist ein Beispiel für eine IntersectionOf-Abfrage. Es wird die „Collection“ auf Weißweine überprüft.
5.3 SWRL
SWRL steht für Semantic Web Rule Language und ist eine Zusammenführung von OWL Lite und OWL DL, nur dass hier die Lesbarkeit durch den Menschen im Vordergrund steht. Es lehnt sich dabei an EBNF (Extended-Backus-Naur-Form) in seiner Syntax an.
Der Syntax sieht so aus:
axiom ::= rule rule ::= 'Implies(' [ URIreference ] { annotation } antecedent consequent ')' antecedent ::= 'Antecedent(' { atom } ')' consequent ::= 'Consequent(' { atom } ')' atom ::= description '(' i-object ')' | dataRange '(' d-object ')' | individualvaluedPropertyID '(' i-object i-object ')' | datavaluedPropertyID '(' i-object d-object ')' | sameAs '(' i-object i-object ')' | differentFrom '(' i-object i-object ')' | builtIn '(' builtinID { d-object } ')' builtinID ::= URIreference i-object ::= i-variable | individualID d-object ::= d-variable | dataLiteral i-variable ::= 'I-variable(' URIreference ')' d-variable ::= 'D-variable(' URIreference ')'Der konkrete XML Syntax sieht so aus.
<swrlx:Ontology swrlx:name = xsd:anyURI > Content: (owlx:VersionInfo | owlx:PriorVersion | owlx:BackwardCompatibleWith | owlx:IncompatibleWith | owlx:Imports | owlx:Annotation | owlx:Class[axiom] | owlx:EnumeratedClass(D,F) | owlx:SubClassOf(D,F) | owlx:EquivalentClasses | owlx:DisjointClasses(D,F) | owlx:DatatypeProperty | owlx:ObjectProperty | owlx:SubPropertyOf | owlx:EquivalentProperties | owlx:Individual[axiom] | owlx:SameIndividual | owlx:DifferentIndividuals | ruleml:imp[axiom] | ruleml:var[axiom])* </swrlx:Ontology>5.4 SPARQL
SPARQL ist ein rekursives Akronym und steht für "SPARQL Protocol and RDF Query Language". Durch SPARQL wird die Aussage klar aus dem WWW eine globale Datenbank zu erstellen.
SPARQL ist eine Sprache um Informationen aus einem RDF-Graphen zu erhalten. Die Grundstruktur erinnert einen stark an SQL, da eine ähnliche Syntax benutzt wurde bzw. die Syntax darauf aufgebaut wurde. Abfragen bestehen aus vier Grundbausteinen: einer PREFIX-Zeile in der Variablen definiert werden können, einer SELECT-Anweisung, in der die Datenbestände angegeben werden können, die durchsucht werden sollen, einer WHERE-Zeile in der ausgewählt wurde, welche Daten aus den vorher angegebenen Quellen extrahiert werden sollen.SPARQL ist eine Abfrage(query)sprache und dient nur dem Abfragen von Inhalten, im Gegensatz zu den Ontologie-Sprachen. Hier ein Beispiel, indem nach den Artikeln von „mosta“ gefragt wird:
PREFIX page: http://www.c-plusplus.net/forum/Artikel SELECT ?topic WHERE{ ?x page:topic ?mosta }6 Fazit
Im Großen und Ganzen ist es eine toll klingende Sache, wobei ich bisher die Nachteile wissentlich verschwiegen habe. Denn das Problem ist, dass man alle Inhalte selbst editieren muss. Das heißt, man muss selbst die Ontologien bauen. Diese Problematik wird sich aber mit der Zeit legen. Wenn es nämlich schon fertige "default" Ontologien gibt, die für uns dann das grundlegende Einsortieren übernehmen können. Bei den jetzigen Systemen läuft das aber alles per Fuß, was sich in etwa wie die ersten Spracherkennungssoftware verhält, nur mit einer längeren „Trainingsphase“.
7 Referenzen
Das RFC zum URI-Standard
http://www.gbiv.com/protocols/uri/rfc/rfc3986.html
Das RDF-Schema Paper vom W3C
http://www.w3.org/TR/rdf-schema/
Der Artikel von Vannevar Bush
http://en.wikipedia.org/wiki/As_We_May_Think
Das SWRL Paper
http://www.w3.org/Submission/SWRL/
-
-
So, ich habe den Satz aus Kapitel 4 nochmal angepasst und die kor-Tags entfernt, du brauchst den Artikel jetzt eigentlich nur noch einmal übernehmen.
Ach was ich noch wissen wollte ist wie liest sich der Artikel?
Ich finde ihn stellenweise etwas zu abstrakt, aber das lässt sich bei der Thematik wohl eher schlecht vermeiden.
-
Mir fällt auf, dass mal " " und mal „ “ verwendet werden.
Das liest sich irgendwie komisch.Könnte man da überall " " draus machen? Die sehen nicht so fusselig aus.
-
-predator- schrieb:
Ach was ich noch wissen wollte ist wie liest sich der Artikel?
Ich finde ihn stellenweise etwas zu abstrakt, aber das lässt sich bei der Thematik wohl eher schlecht vermeiden.
kannst du das bitte ausführen?
-
mosta schrieb:
-predator- schrieb:
Ach was ich noch wissen wollte ist wie liest sich der Artikel?
Ich finde ihn stellenweise etwas zu abstrakt, aber das lässt sich bei der Thematik wohl eher schlecht vermeiden.
kannst du das bitte ausführen?
Naja, mit den Abschnitten zu OWL, SWRL und SPARQL kann ich jetzt z.B. nicht so viel anfangen. Die Informationen sind mir da zu komprimiert... Aber es ist schwierig, das an einzelnen Punkten festzumachen, es ist nur ein subjektiver Eindruck.
PS: Was mir gerade noch aufgefallen ist: es heißt die Syntax, nicht der. Ich habe anscheinend ein paar mal vergessen, das zu korrigieren. Könntest du das noch schnell reineditieren?
Kapitel 5.1:
RDF-Graphen werden mittels eines XML-Syntax beschrieben.
Muss heißen: mittels einer
Kapitel 5.2:
OWL basiert auf den RDF-Syntax und DAML+OIL.
auf der RDF-Syntax
Kapitel 5.3:
Der Syntax sieht so aus:
Die Syntax
Der konkrete XML Syntax sieht so aus.
Die konkrete XML-Syntax**Bindestrich!**
-
-predator- schrieb:
mosta schrieb:
-predator- schrieb:
Ach was ich noch wissen wollte ist wie liest sich der Artikel?
Ich finde ihn stellenweise etwas zu abstrakt, aber das lässt sich bei der Thematik wohl eher schlecht vermeiden.
kannst du das bitte ausführen?
Naja, mit den Abschnitten zu OWL, SWRL und SPARQL kann ich jetzt z.B. nicht so viel anfangen. Die Informationen sind mir da zu komprimiert... Aber es ist schwierig, das an einzelnen Punkten festzumachen, es ist nur ein subjektiver Eindruck.
das hab ich befürchtet aber es soll nur einen Eindruck der Sprachen vermitteln die genutzt werden. Weil das ansonsten zu detaliert und trocken wird. Denn ich muss dann vorher SAchen wie die Prädikaten Logik und XML erklären müsste. Ich hab nur die beführchtung das ich mich zu kurz gehalten habe.
Die Änderungen hab ich gesetzt.
-
Ich denke, das ist schon OK.
Die Sprachen genauer zu beschreiben würde den Rahmen des Artikels sprengen.
Wenn sich jemand für das Thema interessiert, bekommt er so einige Stichworte, zu denen er sich über den Artikel hinaus weiter informieren kann.