[X] Das Thema RSS Feed!
-
MFK schrieb:
Ich sehe da ziemlich oft Leerzeichen um Bindestriche herum. Z.B.:
HttpWebRequest – Klasse
Software - Engineering
Eigentlich gehören da keine Leerzeichen hin, IMHO. Ist das beabsichtigt? Gibt es da einen Style-Guide?
Das wäre soweit ich weiß der erste Artikel, wo das so ist. Ich denke, die gehören da nicht hin - aber ich bin kein Rechtschreib-Ass.
")
Einen Styleguide haben wir nicht.
-
Naja, diese Leerzeichen sind eher stylisch, hat absolut nichts mit korrekter Schreibweise zu tun. Da muß man auch kein Rechtschreib-Ass für sein um das zu wissen. Macht euch mal nicht schlechter als ihr seid! (speziell estartu_de)
-
Artchi, ich schreibe meistens frei nach Schnauze - dass es trotzdem oft passt ist Glück.
Wegen dem Bindestrich: Ich handhabe das für mich so
Wort-Wort <- Wortverbinder für zusammengesetzte Worte
Wort - Wort <- Verbinder für Satzteile (s.o.)
-
Grundkonzept zur Entwicklung eines RSS Feed-Readers unter Verwendung von .NET 1.1
Autor: sclearscreen
Entwicklungsplattform: Windows XP
IDE: Visual Studio 2003
Vorwort
Ich bin registrierter Nutzer des Forums http://www.c-plusplus.net und ich bin absolut überzeugt von der dahinter liegenden Idee solcher Foren.
Eines schönen Abends auf einem Besuch entdeckte ich ein Problemposting eines Unregistrierten in der Richtung „Wie kann ich ein RSS Feed anzeigen“. Nun ich konnte ihm leider nicht helfen, weil ich der Meinung bin, man sollte darüber Ahnung haben, bevor man seinen Senf dazugibt. Zu diesem Zeitpunkt beschäftigte ich mich auch mit einer neuen Entwicklungsumgebung/Framework.
Hinzu kommt noch, dass ich zu diesem Zeitpunkt in einer Weiterbildung war, die sich eben mit dieser Entwicklungumgebung beschäftigt.
Ich dachte nur: „Wie passend! Mal sehen, wie schnell man sich in diese Webtechnik einarbeiten kann.“ Ich wollte das dann auch gleich mit dem Inhalt meiner Weiterbildung verknüpfen.
Nur so viel schon im Voraus: Die Mühe und die gewonnene Erfahrung im Umgang mit der schönen IDE waren es echt wert. Über Lösungen, die ich selbst geschafft habe, kann ich mich immer freuen wie ein Schneekönig. Zudem kann man sehr viel Motivation für Kommendes rausholen.Ein Dozent in meiner Weiterbildung sagte mal zu mir, .NET in Verbindung mit der Microsoft IDE mache ihn süchtig. Ja, in diesem Fall trifft das auch für mich zu - ich weiß jetzt von zwei Abhängigen.
Diese selbstgestellte Aufgabe war sehr reizvoll in Verbindung mit .NET.1. Nur für den Leser, der sich unter RSS Feed noch nichts vorstellen kann
RSS Feed ist eine weitere Möglichkeit, Informationen zu irgendwelchen Themen, die im Internet/Intranet gehostet werden, schnell zusammenzufassen. Der Nutzer solcher RSS Feeds benutzt so genannte RSS Feed-Readerapplikationen, um sich einen schnellen Überblick über neue Informationen zu verschaffen.
Mögliches Szenario wäre: Man hat eine Lieblingswebseite, die ein RSS Feed beinhaltet.
Da hat man sich nun endlich einen RSS Feed-Reader auf seinem Rechner installiert und bevor man auf die Seite surft, holt man sich erstmal einen schnellen Themenüberblick über seine Lieblingswebseite, ob es Neuigkeiten gibt. Denn viele Webseiten haben auch viel sinnfreie Informationen, die einen nicht interessieren.Es ist eine Tatsache, dass RSS Feed ein Dateiformat ist! Hierbei wird XML angewandt und XML kann dabei auch seine Stärken voll zur Entfaltung bringen. Lesern, die sich schon näher mit XML beschäftigt haben, ist zu sagen, dass diese XML-Dokumente (RSS Feeds) datenzentriert aufbereitet sind. D.h., diese Daten sind auch sehr geeignet für das Arbeiten in Verbindung mit Datenbanken und dergleichen.
Wem schon mal folgende Symbole auf Webseiten untergekommen sind



hatte also schon Berührung mit einem oder mehreren RSS Feeds. Diese Symbole/Grafiken kennzeichnen auf einer Webseite Links auf die Datei, die die Informationen des RSS Feeds enthält. Strukturiert ist die Information dort dann eben mit XML. Man macht auf diese Links einen Linksklick/Rechtsklick und erhält in jedem Fall einen URL, den man in seinen RSS Feed-Reader einspeist. Dadurch wird diese Applikation in die Lage versetzt, mittels HTTP oder anderweitigem das XML–Dokument aus dem Netz zu ziehen. Der Reader kann dann das XML–Dokument parsen.
2. Technische Spezifikationen und Versionen von RSS Feed
Wie gesagt, mein Beitrag soll das Grundkonzept sowie das Rüstzeug liefern, damit ein Programmierer/Entwickler einen RSS Feed–Reader mittels des .NET–Frameworks entwickeln kann. Deshalb sollte man sich die folgenden Links ruhig einmal zu Gemüte führen. Schließlich findet man dort das nötige Wissen, durch welche Elementags RSS Feeds strukturiert sind, was wiederum wichtig ist, wenn man Informationen in XML–Dokumenten suchen will!
Hier also erstmal die besagten Internetlinks:http://www.xml.com/pub/a/2002/12/18/dive-into-xml.html
http://www.uatsap.com/de/rss/manual/3
http://blogs.law.harvard.edu/tech/rss
http://www.microsoft.com/germany/msdn/library/data/xml/EntwickelnEinesNewsAggregatorsFuerDesktops.mspx
http://msdn.microsoft.com/coding4fun/xmlforfun/simplerss/default.aspx?print=trueIm Kern ergibt sich daraus, dass diese Webdienste in verschiedene Versionen im Netz laufen.
Version 0.91
Version 1.0
Version 2.0Man sollte jetzt ruhig einmal gooooooogeln, um Webseiten mit solchen Diensten zu finden (siehe die markanten
orangen Symbole). Und man sollte sich dabei auch gleich mal die Zeit nehmen, um das XML–Skript dieser RSS Feeds
zu lesen. Bringt man nun obige Links, die sich mit der Spezifikation von RSS beschäftigen, in Zusammenhang mit konkreten RSS Feeds, erkennt man schnell, dass einige XML–Elementags optional sind und andere immer auftauchen!
Genau die Tags, die in allen Versionen von RSS vorkommen (gemeint sind nicht die optionalen), sollte ein RSS Feed–Reader auch aus einem Webdokument rausparsen können. In Zukunft ist natürlich zu erwarten, dass es nicht bei den paar Versionen bleiben wird. Aber das ist man ja von der IT–Branche gewohnt. Ein RSS Feed (Webdokument) ist mittels XML–Tags strukturiert. Im folgenden Abschnitt gehe ich anhand der vorliegenden Versionsspezifikationen darauf ein, welche Elemente die absolut notwendigen Elementtags sind.3.Die Grundelemente des RSS Feed
3.1 Das Grundgerüst des XML-Skriptes<rss ...>
<channel>
.
.
.
</channel>
</rss>
*Das Wurzelelement heißt rss, wobei das auch attributiert sein kann z.B. RSS–Versions.
Wer so manches über XML gelesen hat, wird vielleicht auch wissen, dass man in XML auch mit Namensräumen arbeiten - ähnlich C/C++ der Scope–Operator - kann.
Es könnte nun Folgendes auftauchen (siehe doppelter Doppelpunkt):<rss::name ...>
<channel::name ...></channel::name>
</rss::name>
*3.2 Die wichtigen Tagelemente zwischen dem Channel–Tag
<item>
<title>...</title>
<link>...</link>
<description>...</description>
</item>
*Diese Tags sind innerhalb des Channel–Elements sind unbedingt erforderlich. Pro Information, die der RSS Feed verwaltet, wiederholt sich das Element item. Es sollte auch einleuchtend sein, dass diese Elemente attributiert sein können und dass auch Namensräume wiederum zum Einsatz kommen können. Wenn jemandem nicht klar ist, was mit Attributierung und Namensräumen bei XML gemeint ist, der sollte sich nochmal mit XML beschäftigen.
Zu der gerade vorangegangenen Bemerkung sei hierzu auf diesen Link verwiesen http://de.selfhtml.org/
Bleibt also nur noch, wie unser RSS Feed-Reader arbeiten sollte. Die Tagnamen sind selbst erklärend genug, denke ich.4. Die angestrebte Arbeitsweise des Feed Readers
4. 1 Die GrundfunktionalitätMan muss den URL zum RSS Feed erfassen können.
Man setzt HTTP ein, um den Zugriff auf das Webdokument (RSS Feed) zu erlangen.
Man lädt sich die Daten per HTTP lokal auf seinen Rechner.
Man muss die Daten (im XML – Skript) parsen.
Man stellt die geparsten Daten geeignet dar.4.2 Unterstützende Klassen des .NET–Frameworks für die Problemstellung
TextBox–Klasse o. Ähnliches zum Erfassen des URL auf das RSS Feed
HttpWebRequest–Klasse, um per HTTP eine Verbindung zum Webdokument (RSS Feed) zu erhalten
HttpWepResponse–Klasse ist eng in Verbindung mit der HttpWebRequest–Klasse zu sehen, da diese
Klasse eine Instanz vom Typ HttpWebResponse erzeugt. Zudem beinhaltet diese Instanz das Webdokument. Wir können es somit lokal verwerten. Diese Instanz erzeugt nun wiederum ein [kor]Stream–Objekt[/kor], was man einem XmlTextReader–Objekt zuführen kann.
Mit der [kor]XmlTextReader–Klasse[/kor] lässt sich das gewonnene XML–Dokument eben auf die Elemente parsen, die ich unter den Punkten 3.1 und 3.2 angesprochen habe.Wenn man ganz zu Fuß parsen möchte, gibt es im .NET–Namensraum System.Text.Regularexpressions auch die sehr nützliche Klasse Regex. Dazu sollte man das Webdokument, was im HttpWebResponse–Objekt steckt, in eine Variable vom Type String bringen. In der MSDN.microsoft.com stehen schöne Beispiele, wie man Regex–Klasse einsetze kann. Einen Link will ich natürlich nicht vorenthalten:
http://search.microsoft.com/search/results.aspx?qu=Regex&View=msdn&st=b&c=0&s=1&swc=0
4.3 Interoperabilität oder Browserautomation - ein anderer nützlicher Ansatzpunkt
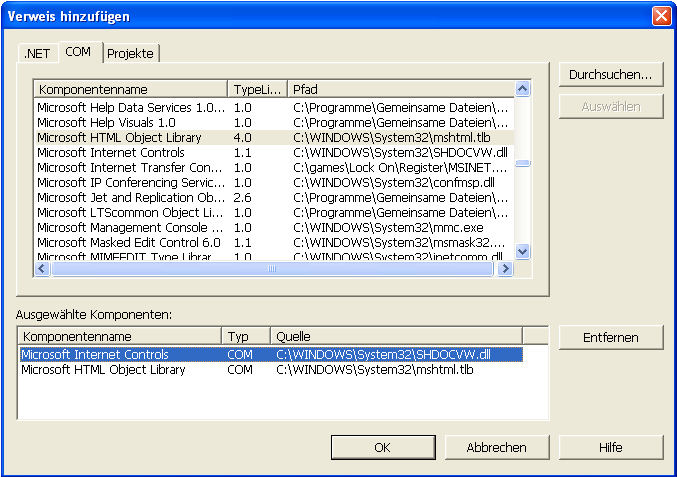
Die Grafik zeigt, dass man in seinem .NET–Projekt Verweise aufnehmen muss, zwei an der Zahl, wenn man diese
interessante Technik auch benutzen will.SHDOCVW.dll hat intern eine Klasse SHDocVw.InternetExplorer zur bidirektionalen Verbindung zwischen Browser und unserer Anwendung.
mshtml.tlb bietet eine unterstützende Klasse zur Konvertierung einer Information, die in einer Instanz von SHDocVw.InternetExplorer vorliegt.Nur so viel: Mit einer Instanz SHDocVw.InternetExplorer haben wir einen direkten Draht zu unserem Internet Explorer.
Wenn dieser eine Seite fertig geladen hat, liegt in derem öffentlichen Member Document die Webseite lokal vor.
Man muss diesen Member in Objekt des Types mshtml.HTMLDocumentClass umcasen, um es konkret verwertbar zu machen. Diesen Typ hat man nur, wenn man den zweiten Verweis in seinem Projekt hat (siehe der obige Grafik).Um mehr über Interoperabilität zu erfahren, sollte man einmal http://www.google.de/ benutzen. Folgender Suchbegriff, den man mit Google verwenden sollte, sollte Einiges bringen:
intext:"SHDocVw.InternetExplorer" + intext:"mshtml.HTMLDocumentClass"
Codeschnipsel sind da manchmal sehr aufschlussreich. An der Stelle füge ich selbstverständlich auch einen Link ein, der auf einen Beitrag von mir verlinkt:
Wie lange der Link aktiv auf meinen Beitrag verweist, hängt natürlich davon ab, wie lange die Webdatenbank des Forums Beiträge speichert. Da der Beitrag aber, denke ich, nicht im .NET-FAQ des Forums(http://www.c-plusplus.net/forum/viewforum-var-f-is-29.html) ist, wird er irgendwann einmal tot sein.
Aber egal, denn mit Google wird man mit etwas Geschick Ähnliches jederzeit reproduzieren können!5 Das GUI meines RSS Feed–Readers auf Basis der vorangegangenen vier Punkte
In den vier Punkten sind viel Internetrecherchen und Gedankengänge von mir eingeflossen. Software–Engineering durch UML, PAP und Nassi Schneidermann habe ich bewusst weggelassen. Das Beispielprojekt ist so einfach, dass sich das meines Erachtens nicht gelohnt hätte.
Der Menüpunkt "Konfiguration" erlaubt, dass der RSS Feed–Reader auch über einen Proxyserver funktioniert.
Als Ausgangspunkt für eine Weiterentwicklung sollte das Projekt eine ausreichende Grundlage sein.
Das Projekt kann man sich natürlich in Form einer gepackten Datei (WinRAR) runterladen.http://www.c-plusplus.net/magazin/bilder/RSS/Version1.1a.rar
Nachwort
An manchen Stellen bin ich vielleicht vom Hundertsten ins Tausendste gekommen oder vielleicht auch nur fast.
Und um es kurz und knackig zu halten, sollte so etwas selbstverständlich nicht passieren. Trotzdem sollte
der Beitrag auch etwas über den Tellerrand lunzen, siehe die Interoperabilität, in der natürlich viel mehr steckt.Mit freundlichen Grüßen
sclearscreen
-
In der Regel gilt Zusammenschreibung (d. h. OHNE Leerzeichen und ohne Bindestrich). Da es sich aber oft um englische Wörter handelt und die noch nicht lange im Umkreis sind (zumindest für den Ottonormalleser, der keine Ahnung von Programmierung hat), sollte man das der besseren Leserlichkeit halber mitm Bindestrich machen.
Namen sollte man auch abtrennen (z. B. "Windows-Programmierung").Aber ansonsten sollte man den Bindestrich vermeiden, weil es meistens, ja, unästhetisch aussiehst und mehr trennt als bindet, vor allem beim Bindungs-"s" wie bei (Widerrufs-Recht -> scheiße -> Widerrufsrecht). Da wären wir schon beim dritten Punkt: Er kann auch benutzt werden, um hervorzuheben. "Das sollst du be-achten", sagt unsere Lehrer sehr gerne, wobei er das erste "e" bei beachten in die Länge zieht.
Ende der kleinen Lehrstunde.
")
Mr. B
-
Kleiner Nachtrag zur Lehrstunde:
Auch bei Abkürzungen ist der Bindestrich zu benutzen: XML-Dokument.Scope-Operator und Software-Engineering könnte man hier noch zusammenschreiben, aber ich finde, dass die aufeinandertreffenden Vokale etwas seltsam aussehen, weil der erste nicht gesprochen wird.
-
Grundkonzept zur Entwicklung eines RSS*-*Feed-Readers unter Verwendung von .NET 1.1
Autor: sclearscreen
Entwicklungsplattform: Windows XP
IDE: Visual Studio 2003
Vorwort
Ich bin registrierter Nutzer des Forums http://www.c-plusplus.net und ich bin absolut überzeugt von der dahinter liegenden Idee solcher Foren.
Eines schönen Abends auf einem Besuch entdeckte ich ein Problemposting eines Unregistrierten in der Richtung „Wie kann ich ein RSS***-***Feed anzeigen“. Nun ich konnte ihm leider nicht helfen, weil ich der Meinung bin, man sollte darüber Ahnung haben, bevor man seinen Senf dazugibt. Zu diesem Zeitpunkt beschäftigte ich mich auch mit einer neuen Entwicklungsumgebung/Framework.
Hinzu kommt noch, dass ich zu diesem Zeitpunkt in einer Weiterbildung war, die sich eben mit dieser Entwicklung***s***umgebung beschäftigt.
Ich dachte nur: „Wie passend! Mal sehen, wie schnell man sich in diese Webtechnik einarbeiten kann.“ Ich wollte das dann auch gleich mit dem Inhalt meiner Weiterbildung verknüpfen.
Nur so viel schon im Voraus: Die Mühe und die gewonnene Erfahrung im Umgang mit der schönen IDE waren es echt wert. Über Lösungen, die ich selbst geschafft habe, kann ich mich immer freuen wie ein Schneekönig. Zudem kann man sehr viel Motivation für Kommendes rausholen.Ein Dozent in meiner Weiterbildung sagte mal zu mir, .NET in Verbindung mit der Microsoft IDE mache ihn süchtig. Ja, in diesem Fall trifft das auch für mich zu - ich weiß jetzt von zwei Abhängigen.
Diese selbstgestellte Aufgabe war sehr reizvoll in Verbindung mit .NET.1. Nur für den Leser, der sich unter RSS*-*Feed noch nichts vorstellen kann
RSS***-Feed ist eine weitere Möglichkeit, Informationen zu irgendwelchen Themen, die im Internet/Intranet gehostet werden, schnell zusammenzufassen. Der Nutzer solcher RSS-Feeds benutzt so genannte RSS-Feed-Readerapplikationen, um sich einen schnellen Überblick über neue Informationen zu verschaffen.
Mögliches Szenario wäre: Man hat eine Lieblingswebseite, die ein RSS-Feed beinhaltet.
Da hat man sich nun endlich einen RSS-Feed-Reader auf seinem Rechner installiert und bevor man auf die Seite surft, holt man sich erstmal einen schnellen Themenüberblick über seine Lieblingswebseite, ob es Neuigkeiten gibt. Denn viele Webseiten haben auch viel***e sinnfreie Informationen, die einen nicht interessieren.Es ist eine Tatsache, dass RSS***-Feed ein Dateiformat ist! Hierbei wird XML angewandt und XML kann dabei auch seine Stärken voll zur Entfaltung bringen. Lesern, die sich schon näher mit XML beschäftigt haben, ist zu sagen, dass diese XML-Dokumente (RSS-***Feeds) datenzentriert aufbereitet sind. D. h., diese Daten sind auch sehr geeignet für das Arbeiten in Verbindung mit Datenbanken und dergleichen.
Wem schon mal folgende Symbole auf Webseiten untergekommen sind
hatte also schon Berührung mit einem oder mehreren RSS***-Feeds. Diese Symbole/Grafiken kennzeichnen auf einer Webseite Links auf die Datei, die die Informationen des RSS-Feeds enthält. Strukturiert ist die Information dort dann eben mit XML. Man macht auf diese Links einen Linksklick/Rechtsklick und erhält in jedem Fall eine URL, die man in seinen RSS-***Feed-Reader einspeist. Dadurch wird diese Applikation in die Lage versetzt, mittels HTTP oder anderweitigem das XML–Dokument aus dem Netz zu ziehen. Der Reader kann dann das XML–Dokument parsen.
2. Technische Spezifikationen und Versionen von RSS*-*Feed
Wie gesagt, mein Beitrag soll das Grundkonzept sowie das Rüstzeug liefern, damit ein Programmierer/Entwickler einen RSS***-Feed–Reader mittels des .NET–Frameworks entwickeln kann. Deshalb sollte man sich die folgenden Links ruhig einmal zu Gemüte führen. Schließlich findet man dort das nötige Wissen, durch welche Element***t***ags RSS-***Feeds strukturiert sind, was wiederum wichtig ist, wenn man Informationen in XML–Dokumenten suchen will!
Hier also erstmal die besagten Internetlinks:http://www.xml.com/pub/a/2002/12/18/dive-into-xml.html
http://www.uatsap.com/de/rss/manual/3
http://blogs.law.harvard.edu/tech/rss
http://www.microsoft.com/germany/msdn/library/data/xml/EntwickelnEinesNewsAggregatorsFuerDesktops.mspx
http://msdn.microsoft.com/coding4fun/xmlforfun/simplerss/default.aspx?print=trueIm Kern ergibt sich daraus, dass diese Webdienste in verschiedene Versionen im Netz laufen.
Version 0.91
Version 1.0
Version 2.0Man sollte jetzt ruhig einmal googeln~man braucht es ja nicht zu übertreiben
~, um Webseiten mit solchen Diensten zu finden (siehe die markanten orangefarbenen~orange wird nicht gebeugt~ Symbole). Und man sollte sich dabei auch gleich mal die Zeit nehmen, um das XML–Skript dieser RSS***-Feeds
zu lesen. Bringt man nun obige Links, die sich mit der Spezifikation von RSS beschäftigen, in Zusammenhang mit konkreten RSS-Feeds, erkennt man schnell, dass einige XML–Element***t***ags optional sind und andere immer auftauchen!
Genau die Tags, die in allen Versionen von RSS vorkommen (gemeint sind nicht die optionalen), sollte ein RSS-Feed–Reader auch aus einem Webdokument rausparsen können. In Zukunft ist natürlich zu erwarten, dass es nicht bei den paar Versionen bleiben wird. Aber das ist man ja von der IT–Branche gewohnt. Ein RSS-***Feed (Webdokument) ist mittels XML–Tags strukturiert. Im folgenden Abschnitt gehe ich anhand der vorliegenden Versionsspezifikationen darauf ein, welche Elemente die absolut notwendigen Elementtags sind.3. Die Grundelemente des RSS*-*Feed
3.1 Das Grundgerüst des XML-Skriptes<rss ...>
<channel>
.
.
.
</channel>
</rss>
*Das Wurzelelement heißt rss, wobei das auch attributiert sein kann z.B. RSS–Versions.
Wer so manches über XML gelesen hat, wird vielleicht auch wissen, dass man in XML auch mit Namensräumen arbeiten ***kann, ähnlich wie der Scope–Operator in C/C++.***~merkwürdige Satzstellung~
Es könnte nun Folgendes auftauchen (siehe doppelter Doppelpunkt):<rss::name ...>
<channel::name ...></channel::name>
</rss::name>
*3.2 Die wichtigen Tagelemente zwischen dem Channel–Tag
<item>
<title>...</title>
<link>...</link>
<description>...</description>
</item>
*Diese Tags innerhalb des Channel–Elements sind unbedingt erforderlich. Pro Information, die der RSS***-Feed verwaltet, wiederholt sich das Element item. Es sollte auch einleuchtend sein, dass diese Elemente attributiert sein können und dass auch Namensräume wiederum zum Einsatz kommen können. Wenn jemandem nicht klar ist, was mit Attributierung und Namensräumen bei XML gemeint ist, der sollte sich noch einmal mit XML beschäftigen.
Zu der gerade vorangegangenen Bemerkung sei hierzu auf diesen Link verwiesen http://de.selfhtml.org/
Bleibt also nur noch, wie unser RSS-***Feed-Reader arbeiten sollte. Die Tagnamen sind selbst erklärend genug, denke ich.4. Die angestrebte Arbeitsweise des Feed*-*Readers
4. 1 Die GrundfunktionalitätMan muss die URL zum RSS***-Feed erfassen können.
Man setzt HTTP ein, um den Zugriff auf das Webdokument (RSS-***Feed) zu erlangen.
Man lädt sich die Daten per HTTP lokal auf seinen Rechner.
Man muss die Daten (im XML–Skript) parsen.
Man stellt die geparsten Daten geeignet dar.4.2 Unterstützende Klassen des .NET–Frameworks für die Problemstellung
TextBox–Klasse oder Ähnliches zum Erfassen der URL auf das RSS***-Feed
HttpWebRequest–Klasse, um per HTTP eine Verbindung zum Webdokument (RSS-***Feed) zu erhalten
HttpWepResponse–Klasse ist eng in Verbindung mit der HttpWebRequest–Klasse zu sehen, da diese
Klasse eine Instanz vom Typ HttpWebResponse erzeugt. Zudem beinhaltet diese Instanz das Webdokument. Wir können es somit lokal verwerten. Diese Instanz erzeugt nun wiederum ein Stream–Objekt, was man einem XmlTextReader–Objekt zuführen kann.
Mit der XmlTextReader–Klasse lässt sich das gewonnene XML–Dokument eben auf die Elemente parsen, die ich unter den Punkten 3.1 und 3.2 angesprochen habe.Wenn man ganz von Hand~"zu Fuß" passt irgendwie nicht...~ parsen möchte, gibt es im .NET–Namensraum System.Text.Regularexpressions auch die sehr nützliche Klasse Regex. Dazu sollte man das Webdokument, was im HttpWebResponse–Objekt steckt, in eine Variable vom Typ String bringen. In der MSDN.microsoft.com stehen schöne Beispiele, wie man die Regex–Klasse einsetze***n*** kann. Einen Link will ich natürlich nicht vorenthalten:
http://search.microsoft.com/search/results.aspx?qu=Regex&View=msdn&st=b&c=0&s=1&swc=0
4.3 Interoperabilität oder Browserautomation - ein anderer nützlicher Ansatzpunkt
Die Grafik zeigt, dass man in seinem .NET–Projekt Verweise aufnehmen muss, zwei an der Zahl, wenn man diese
interessante Technik auch benutzen will.SHDOCVW.dll hat intern eine Klasse SHDocVw.InternetExplorer zur bidirektionalen Verbindung zwischen Browser und unserer Anwendung.
mshtml.tlb bietet eine unterstützende Klasse zur Konvertierung einer Information, die in einer Instanz von SHDocVw.InternetExplorer vorliegt.Nur so viel: Mit einer Instanz SHDocVw.InternetExplorer haben wir einen direkten Draht zu unserem Internet Explorer.
Wenn dieser eine Seite fertig geladen hat, liegt in dere***n*** öffentlichen Member Document die Webseite lokal vor.
Man muss diesen Member in ein Objekt des Typs mshtml.HTMLDocumentClass umcas***t***en, um es konkret verwertbar zu machen. Diesen Typ hat man nur, wenn man den zweiten Verweis in seinem Projekt hat (siehe der obige Grafik).Um mehr über Interoperabilität zu erfahren, sollte man einmal http://www.google.de/ benutzen. Folgender Suchbegriff, den man mit Google verwenden sollte, sollte Einiges bringen:
intext:"SHDocVw.InternetExplorer" + intext:"mshtml.HTMLDocumentClass"
Codeschnipsel sind da manchmal sehr aufschlussreich. An der Stelle füge ich selbstverständlich auch einen Link ein, der auf einen Beitrag von mir verlinkt:
Wie lange der Link aktiv auf meinen Beitrag verweist, hängt natürlich davon ab, wie lange die Webdatenbank des Forums Beiträge speichert. Da der Beitrag aber, denke ich, nicht im .NET-FAQ des Forums(http://www.c-plusplus.net/forum/viewforum-var-f-is-29.html) ist, wird er irgendwann einmal tot sein.
Aber egal, denn mit Google wird man mit etwas Geschick Ähnliches jederzeit reproduzieren können!5 Das GUI meines RSS*-*Feed–Readers auf Basis der vorangegangenen vier Punkte
In den vier Punkten sind viel Internetrecherchen und Gedankengänge von mir eingeflossen. Software–Engineering durch UML, PAP und Nassi Schneidermann habe ich bewusst weggelassen. Das Beispielprojekt ist so einfach, dass sich das meines Erachtens nicht gelohnt hätte.
Der Menüpunkt "Konfiguration" erlaubt, dass der RSS***-***Feed–Reader auch über einen Proxyserver funktioniert.
Als Ausgangspunkt für eine Weiterentwicklung sollte das Projekt eine ausreichende Grundlage sein.
Das Projekt kann man sich natürlich in Form einer gepackten Datei (WinRAR) runterladen.http://www.c-plusplus.net/magazin/bilder/RSS/Version1.1a.rar
Nachwort
An manchen Stellen bin ich vielleicht vom Hundertsten ins Tausendste gekommen oder vielleicht auch nur fast.
Und um es kurz und knackig zu halten, sollte so etwas selbstverständlich nicht passieren. Trotzdem sollte
der Beitrag auch etwas über den Tellerrand lunzen, siehe die Interoperabilität, in der natürlich viel mehr steckt.Mit freundlichen Grüßen
sclearscreen
-
Warum die URL? Ich wäre für maskulinum, weil das L für Locator steht, und AFAIK alle Worte auf -or aus dem Lateinischen im Deutschen männlich sind.
Nachtrag: Erledigt, die weibliche Form scheint tatsächlich die verbreitetere zu sein.
-
Keine Ahnung warum es weiblich ist, aber im Duden stehts so
-
MFK schrieb:
Warum die URL? Ich wäre für maskulinum, weil das L für Locator steht, und AFAIK alle Worte auf -or aus dem Lateinischen im Deutschen männlich sind.
Ditto.
-predator- schrieb:
Keine Ahnung warum es weiblich ist, aber im Duden stehts so
Duden schrieb:
URL, die; -, -s, (selten:) der; -s, -s
"Der URL" ist also durchaus auch laut Duden korrekt.
-
MFK schrieb:
Nachtrag: Erledigt, die weibliche Form scheint tatsächlich die verbreitetere zu sein.
Was sie nicht richtiger macht.
-
Kann momentan von daheim nichts machen.
Da mein EPOX Mainboard den Dienst versagt hat. Habe mir schon ein Neues bestellt.
Ich hoffe es kommt die Woche noch.mfg sclearscreen
-
@all
so mein System tut wieder seinen Dienst
@-predator-
@MFK
und an die Anderen, erstmal vielen Dank Eurer Mühe
So wie ich schon sagte mein System läuft wieder (10 Elkos auf meinem alten Board waren Tod) werde meinen Beitrag nun morgen endlich überarbeiten können.Das Ergebnis der Änderungen auf Basis Eurer Vorarbeit stelle ich dann wieder hier rein versteht sich.
Mit freundlichen Grüssen sclearscreen
-
Grundkonzept zur Entwicklung eines RSS Feed Readers unter Verwendung von .NET 1.1
Autor: sclearscreen
Entwicklungsplattform: WindowsXP
IDE: Visual Studio 2003
Vorwort
Ich bin registrierter Nutzer des Forums http://www.c-plusplus.net und ich bin absolut überzeugt von
der dahinter liegenden Idee solcher Foren.
Eines schönen Abends auf einem Besuch entdeckte ich ein Problemposting eines Unregistrierten,
in der Richtung „Wie kann ich ein RSS Feed anzeigen“. Nun ich konnte ihm leider nicht helfen,
weil ich der Meinung bin man sollte darüber Ahnung haben, bevor man seinen Senf dazugibt. Zu diesem Zeitpunkt beschäftigt ich mich auch mit einer neuen Entwicklungsumgebung/Framework.
Hinzu kommt noch das ich zu diesem Zeitpunkt in einer Weiterbildung war, die sich mit eben dieser Entwicklungumgebung beschäftigt.
Ich dachte nur: „Wie passend! Mal sehn wie schnell man sich in diese Webtechnik einarbeiten kann.“ Ich wollte das dann auch gleich mit dem Inhalt meiner Weiterbildung verknüpfen.
Nur soviel schon im Voraus die Mühe und die gewonnene Erfahrung im Umgang mit der schönen IDE waren es echt wert. Über Lösungen die man selbst geschafft habe kann ich mich immer freuen wie ein Schneekönig, zudem kann man sehr viel Motivation für Kommendes rausholen.Ein Dozent in meiner Weiterbildung sagt mal zu mir .NET in Verbindung mit der Microsoft IDE
macht Ihn süchtig. Ja in meinem Fall trifft das auch für mich zu, ich weiß jetzt von zwei Abhängigen.
Diese selbstgestellte Aufgabe war sehr reizvoll in Verbindung mit .NET1. Nur für den Leser der sich unter RSS Feed noch nichts vorstellen kann
RSS Feed ist eine weitere Möglichkeit, Informationen zu irgendwelchen Themen, die im Internet/Intranet gehostet werden, schnell zusammenzufassen. Der Nutzer solcher RSS Feeds, benutzt sogenannte RSS Feed – Readerapplikationen um sich einen schnellen Überblick über neue Informationen zu verschaffen.
Denkbares Szenario wäre, man hat eine Lieblingswebseite die eine RSS Feed beinhaltet.
Dann hat man sich schlussendlich einen RSS Feed – Reader auf seinen Rechner installiert. Und bevor man auf die Seite surft holt man sich erstmal einen schnellen Themenüberblick über seine Lieblingswebseite ob es Neuigkeiten gibt. Denn viele Webseiten haben auch viel sinnfreie Informationen die einen nicht interessieren.Es ist eine Tatsache das RSS Feed ein Dateiformat ist! Hierbei wird XML angwendet und XML kann dabei auch seine Stärken voll zur Entfalltung bringen. Für Leser die sich schon näher mit XML beschäftigt haben ist zu sagen, das diese
XML – Dokumente (RSS Feeds) datenzentriert aufbereitet sind. D.h. Diese Daten sind auch sehr geiegnet für das Arbeiten in Verbindung mit Datenbanken und dergleichen.Wem schonmal fogende Symboliken auf Webseiten untergekommen sind
hatte also schon Behrührung mit einem oder mehren RSS Feed. Diese Symboliken/Grafiken kennzeichnen auf einer
Webseite Links auf die Datei die die Informationen des RSS Feeds enthält. Strukturiert ist die Information dort dann eben mittels XML. Man macht auf diese Links einen Linksklick/Rechtsklick und erhält in jedem Fall einen URL den
man in seinen RSS Feed–Reader einspeisst. Dadurch wird diese Applikation in die Lage versetzt mittels HTTP oder
anderweitig das XML–Dokument aus dem Netz zu ziehen. Der Reader kann dann das XML–Dokument parsen.2. Technische Spezifikationen und Versionen von RSS Feed
Wie gesagt mein Beitrag soll das Grundkonzept sowie das Rüstzeug liefern. Damit ein Programmierer/Entwickler
einen RSS Feed–Reader mittels des .NET – Framework entwickeln kann. Deshalb sollte man sich die folgenden Links
ruhig einmal zu Gemüte führen. Schliesslich findet man dort das nötige „Know How“ durch welche Elementags
RSS Feeds strukturiert sind. Was wiederum wichtig ist wenn man Information in XML–Dokumenten suchen will!
Hier also erstmal die besagten Internetlinks:http://www.xml.com/pub/a/2002/12/18/dive-into-xml.html
http://www.uatsap.com/de/rss/manual/3
http://blogs.law.harvard.edu/tech/rss
http://www.microsoft.com/germany/msdn/library/data/xml/EntwickelnEinesNewsAggregatorsFuerDesktops.mspx
http://msdn.microsoft.com/coding4fun/xmlforfun/simplerss/default.aspx?print=trueIm Kern ergibt sich daraus das diese Web – Dienste in verschiedene Versionen im Netz laufen.
Version 0.91
Version 1.0
Version 2.0Man sollte jetzt ruhig einmal gooooooogeln um Webseiten mit solchen Diensten zu finden, siehe die markanten
orangen Symbole. Und man sollte sich dabei auch gleich mal die Zeit nehmen, um den XML–Skript dieser RSS Feeds
zu lesen. Bringt man nun obige Links, die sich mit der Spezifikation von RSS beschäftigen, in Zusammenhang mit konkreten RSS Feeds erkennt man schnell das einige XML – Elementags optional sind und andere immer auftauchen!
Genau die Tags die in allen Versionen von RSS vorkommen (gemeint sind nicht die optionalen) sollte ein RSS Feed – Reader auch aus einem Webdokument rausparsen können. In Zukunft ist nathürlich zu erwarten das es nicht bei den
paar Versionen bleiben wird. Aber das ist man ja von der IT–Branche gewöhnt. Ein RSS Feed (Webdokument) ist
mittels XML – Tags strukturiert. Im folgenden Abschnitt gehe ich darauf ein welche Elemente, anhand der vorliegenden Versionsspezifikationen, die absolut notwendigen Elementtags sind.3.Die Grundelemente des RSS Feed
3.1 Das Grundgerüst des XML-Skriptes<rss ...>
<channel>
.
.
.
</channel>
</rss>
*Das Wurzelelement heisst rss wobei das auch attributiert sein kann z.B. RSS–Version.
Wer auch manches über XML gelesen hat wird vielleicht auch wissen das man in XML auch mit Namensräumen arbeiten ähnlich C/C++ der Scope – Operator kann dann folgendes auftauchen.
Siehe doppelter Doppelpunkt.<rss::name ...>
<channel::name ...></channel::name>
</rss::name>
*3.2Die wichtigen Tagelemente zwischen dem Channel–Tag
<item>
<title>...</title>
<link>...</link>
<description>...</description>
</item>
*Diese Tags sind innerhalb des Channel–Elements sind unbedingt erforderlich. Pro Information die der RSS Feed verwaltet wiederholt sich das Element item. Es sollte auch einleuchtend sein das diese Element auch attributiert sein können, als auch das wiederum Namensräume zum Einsatz kommen können. Wenn einem nicht klar ist was mit Attributierung und Namensräumen bei XML gemeint ist der sollte sich nochmal mit XML beschäftigen.
Zu gerade vorangegangener Bemerkung sei hierzu auf diesen Link verwiesen http://de.selfhtml.org/
Bleibt also nur noch wie unsere RSS Feed Reader arbeiten sollte. Die Tagnamen sind selbsterklärend genug, denke ich.4.Die angestrebte Arbeitsweise des Feed Reader
4. 1 Die GrundfunktionalitätMan muss den URL zum RSS Feed erfassen können
Man setzt HTTP ein um den Zugriff auf das Webdokument (RSS Feed) zu erlangen
Man lädt sich die Daten per HTTP lokal auf seinen Rechner
Man muss die Daten (im XML – Skript) parsen
Man stellt die geparsten Daten geeignet dar4.2Unterstützende Klassen des .NET–Framework für die Problemstellung
TextBox–Klasse o. Ähnliches zum erfassen des URL auf den RSS Feed
HttpWebRequest–Klasse um per HTTP eine Verbindung zum Webdokument (RSS Feed) zu erhalten
HttpWepResponse–Klasse ist eng in Verbindung mit der HttpWebRequest–Klasse zu sehen, da diese
Klasse eine Instanz vom Typ HttpWebResponse erzeugt Zudem beinhalte diese Instanz das Webdokument, es ist somit lokal für uns verwertbar. Diese Instanz erzeugt nun wiederum ein Stream–Objekt was man einem XmlTextReader–Objekt zuführen kann.
Mit der XmlTextReader–Klasse lässt sich das gewonnene XML–Dokument parsen, eben auf die Elemente die ich unter den Punkten 3.1 als auch 3.2 angesprochen habe.Wenn man ganz zu Fuss parsen möchte gibt es im .NET–Namensraum System.Text.Regularexpressions auch die sehr nützliche Klasse Regex. Dazu sollte man das Webdokument was im HttpWebResponse–Objekt steckt, in eine
Variable vom Type String bringen. In der MSDN.microsoft.com stehen schöne Beispiel wie man Regex–Klasse einsetzen tut. Einen Link will ich nathürlich nicht vorenthalten siehe:http://search.microsoft.com/search/results.aspx?qu=Regex&View=msdn&st=b&c=0&s=1&swc=0
4.3Interoperabilität oder Browserautomation ein anderer nützlicher Ansatzpunk
Die Grafik zeigt das man in seinem .NET–Projekt Verweise aufnehmen muss, 2 an der Zahl, wenn man diese
interessante Technik auch benutzen will.SHDOCVW.dll hat intern eine Klasse SHDocVw.InternetExplorer zur bidirektionalen Verbindung zwischen Browser
und unserer Anwendung
mshtml.tlb bietet eine unterstützende Klasse zur Konvertierung einer Information, die in einer Instanz von SHDocVw.InternetExplorer vorliegtNur soviel mit einer Instanz SHDocVw.InternetExplorer haben wir eine direkt Draht zu unserem Internetexplorer.
Wenn dieser eine Seite fertig geladen hat, liegt in deren öffentlichen Member Document die Webseite lokal vor.
Man muss diesen Member in Objekt des Types mshtml.HTMLDocumentClass umcasen um es konkret verwertbar zu machen. Diesen Typ hat man nur wenn man den 2. Verweis in seinem Projekt hat siehe der obigen Grafik.Um mehr über Interoperabilität zu erfahren sollte man einmal http://www.google.de/ benutzen. Folgender Suchquery sollte einiges bringen, den man mit Google verwenden sollte:
intext:"SHDocVw.InternetExplorer" + intext:"mshtml.HTMLDocumentClass"
Code – Schnipsel sind da manchmal sehr aufschlussreich. An der Stelle füge ich selbstverständlich auch einen Link ein der auf einen Beitrag von mir verlinkt:
Wie lange der Link aktiv auf meinen Beitrag verweist, hängt nathürlich davon ab wie lange die Webdatenbank des Forums Beiträge speichert. Da der Beitrag aber denke ich nicht im .NET - FAQ des Forums(http://www.c-plusplus.net/forum/viewforum-var-f-is-29.html) ist wird er irgendwann mal tot sein.
Aber egal durch Google wird man mit etwas Geschick ähnliches jederzeit reproduzieren können!5 Das GUI meines RSS Feed – Readers auf Basis der vorangegangenen 4 Punkte
In die 4 Punkte sind viel Internetrecherchen und Gedankengänge von mir eingeflossen. Software–Engineering durch
UML, PAP und Nassi Schneidermann habe ich bewusst weggelassen. Das Beispielprojekt ist so einfach das sich das meines Erachtens nicht gelohnt hätte.
Der Menüpunkt Konfiguration erlaubt das der RSS Feed – Reader auch über einen Proxy–Server funktioniert.
Als Ausgangspunkt für eine Weiterentwicklung sollte das Projekt eine ausreichende Grundlage sein.
Das Projekt kann man sich nathürlich in Form einer gepackten Datei (WinRAR) runterladen.http://www.c-plusplus.net/magazin/bilder/RSS/Version1.1a.rar
Nachwort
An manchen Stellen bin ich vielleicht vom 100sten ins 1000ste gekommen, oder vielleicht auch nur fast.
Und um es kurz und knackig zu halten sollte soetwas selbstverständlich nicht passieren. Trotzdem sollte
der Beitrag auch etwas über den Tellerrand lunzen, siehe die Interoperabilität in der nathürlich viel mehr steckt.Mit freundlichen Grüssen sclearscreen
-
Seh ich schlecht, oder sind da jetzt wieder jede Menge Fehler drin? Hast du die letzte korrigierte Fassung benutzt?
-
ich habe die letzte korrigierte Fassung benutzt und habe die dick gekennzeichneten
Fehler so geändert wie es gekennzeichnet war!z.B: habe ich die Leerzeichen zwischen ehemals HttpWebRequest - Klasse
rausgenommen etc.dann auch das mit der wörtlichen Rede was Du angemerkt hattest
usw. und und und
mfg sclearscreen
P.S.: Ich benutze aucgh Fettdruck auch ganz für gewöhnliche Hervorhebungen und nicht für Fehlermarkierungen :xmas1:
-
sclearscreen schrieb:
ich habe die letzte korrigierte Fassung benutzt
Die von -predator-, auf Seite 7 ganz unten?
Danach sieht es nicht aus. Viele Leerzeichen um Bindestriche, und nathürlich auch. Jede Menge Fehler, die längst berichtigt waren, sind wieder drin.
-
okay dann hatte ich den Falschen erwischt
ich brauche also nur den auf Seite 7 nehmen der ist korrigiert?
Es sollte dann also reichen an den entsprechenden Stellen
die korrigiert worden sind Kursiv- und Fettdruck rauszunehmen und sonstige Textausschmückungen die korrigierte Stellen ausweisen?Wäre das dann soweit okay?
-
sclearscreen schrieb:
ich brauche also nur den auf Seite 7 nehmen
Ja.
Es sollte dann also reichen an den entsprechenden Stellen
die korrigiert worden sind Kursiv- und Fettdruck rauszunehmen und sonstige Textausschmückungen die korrigierte Stellen ausweisen?Hast du denn noch etwas hinzuzufügen? Denselben Text, nur um die [kor]-Tags bereinigt, nochmal zu zitieren, bringt ja nicht viel.
-
Grundkonzept zur Entwicklung eines RSS Feed Readers unter Verwendung von .NET 1.1
Autor: sclearscreen
Entwicklungsplattform: WindowsXP
IDE: Visual Studio 2003
Vorwort
Ich bin registrierter Nutzer des Forums http://www.c-plusplus.net und ich bin absolut überzeugt von
der dahinter liegenden Idee solcher Foren.
Eines schönen Abends auf einem Besuch entdeckte ich ein Problemposting eines Unregistrierten,
in der Richtung „Wie kann ich ein RSS Feed anzeigen“. Nun ich konnte ihm leider nicht helfen,
weil ich der Meinung bin man sollte darüber Ahnung haben, bevor man seinen Senf dazugibt. Zu diesem Zeitpunkt beschäftigt ich mich auch mit einer neuen Entwicklungsumgebung/Framework.
Hinzu kommt noch das ich zu diesem Zeitpunkt in einer Weiterbildung war, die sich mit eben dieser Entwicklungumgebung beschäftigt.
Ich dachte nur: „Wie passend! Mal sehn wie schnell man sich in diese Webtechnik einarbeiten kann.“ Ich wollte das dann auch gleich mit dem Inhalt meiner Weiterbildung verknüpfen.
Nur soviel schon im Voraus die Mühe und die gewonnene Erfahrung im Umgang mit der schönen IDE waren es echt wert. Über Lösungen die man selbst geschafft habe kann ich mich immer freuen wie ein Schneekönig, zudem kann man sehr viel Motivation für Kommendes rausholen.Ein Dozent in meiner Weiterbildung sagt mal zu mir .NET in Verbindung mit der Microsoft IDE
macht Ihn süchtig. Ja in meinem Fall trifft das auch für mich zu, ich weiß jetzt von zwei Abhängigen.
Diese selbstgestellte Aufgabe war sehr reizvoll in Verbindung mit .NET1. Nur für den Leser der sich unter RSS Feed noch nichts vorstellen kann
RSS Feed ist eine weitere Möglichkeit, Informationen zu irgendwelchen Themen, die im Internet/Intranet gehostet werden, schnell zusammenzufassen. Der Nutzer solcher RSS Feeds, benutzt sogenannte RSS Feed–Readerapplikationen um sich einen schnellen Überblick über neue Informationen zu verschaffen.
Denkbares Szenario wäre, man hat eine Lieblingswebseite die eine RSS Feed beinhaltet.
Dann hat man sich schlussendlich einen RSS Feed–Reader auf seinen Rechner installiert. Und bevor man auf die Seite surft holt man sich erstmal einen schnellen Themenüberblick über seine Lieblingswebseite ob es Neuigkeiten gibt. Denn viele Webseiten haben auch viel sinnfreie Informationen die einen nicht interessieren.Es ist eine Tatsache das RSS Feed ein Dateiformat ist! Hierbei wird XML angwendet und XML kann dabei auch seine Stärken voll zur Entfalltung bringen. Für Leser die sich schon näher mit XML beschäftigt haben ist zu sagen, das diese
XML–Dokumente (RSS Feeds) datenzentriert aufbereitet sind. D.h. Diese Daten sind auch sehr geiegnet für das Arbeiten in Verbindung mit Datenbanken und dergleichen.Wem schonmal fogende Symboliken auf Webseiten untergekommen sind
hatte also schon Berührung mit einem oder mehren RSS Feed. Diese Symboliken/Grafiken kennzeichnen auf einer
Webseite Links auf die Datei die die Informationen des RSS Feeds enthält. Strukturiert ist die Information dort dann eben mittels XML. Man macht auf diese Links einen Linksklick/Rechtsklick und erhält in jedem Fall einen URL den
man in seinen RSS Feed–Reader einspeisst. Dadurch wird diese Applikation in die Lage versetzt mittels HTTP oder
anderweitig das XML–Dokument aus dem Netz zu ziehen. Der Reader kann dann das XML–Dokument parsen.2. Technische Spezifikationen und Versionen von RSS Feed
Wie gesagt mein Beitrag soll das Grundkonzept sowie das Rüstzeug liefern. Damit ein Programmierer/Entwickler
einen RSS Feed–Reader mittels des .NET–Frameworks entwickeln kann. Deshalb sollte man sich die folgenden Links
ruhig einmal zu Gemüte führen. Schliesslich findet man dort das nötige „Know How“ durch welche Elementags
RSS Feeds strukturiert sind. Was wiederum wichtig ist wenn man Information in XML–Dokumenten suchen will!
Hier also erstmal die besagten Internetlinks:http://www.xml.com/pub/a/2002/12/18/dive-into-xml.html
http://www.uatsap.com/de/rss/manual/3
http://blogs.law.harvard.edu/tech/rss
http://www.microsoft.com/germany/msdn/library/data/xml/EntwickelnEinesNewsAggregatorsFuerDesktops.mspx
http://msdn.microsoft.com/coding4fun/xmlforfun/simplerss/default.aspx?print=trueIm Kern ergibt sich daraus das diese Web – Dienste in verschiedene Versionen im Netz laufen.
Version 0.91
Version 1.0
Version 2.0Man sollte jetzt ruhig einmal gooooooogeln um Webseiten mit solchen Diensten zu finden, siehe die markanten
orangen Symbole. Und man sollte sich dabei auch gleich mal die Zeit nehmen, um den XML–Skript dieser RSS Feeds
zu lesen. Bringt man nun obige Links, die sich mit der Spezifikation von RSS beschäftigen, in Zusammenhang mit konkreten RSS Feeds erkennt man schnell das einige XML–Elementags optional sind und andere immer auftauchen!
Genau die Tags die in allen Versionen von RSS vorkommen (gemeint sind nicht die optionalen) sollte ein RSS Feed–Reader auch aus einem Webdokument rausparsen können. In Zukunft ist nathürlich zu erwarten das es nicht bei den
paar Versionen bleiben wird. Aber das ist man ja von der IT–Branche gewöhnt. Ein RSS Feed (Webdokument) ist
mittels XML–Tags strukturiert. Im folgenden Abschnitt gehe ich darauf ein welche Elemente, anhand der vorliegenden Versionsspezifikationen, die absolut notwendigen Elementtags sind.3.Die Grundelemente des RSS Feed
3.1 Das Grundgerüst des XML-Skriptes<rss ...>
<channel>
.
.
.
</channel>
</rss>
*Das Wurzelelement heisst rss wobei das auch attributiert sein kann z.B. RSS–Versions.
Wer auch manches über XML gelesen hat wird vielleicht auch wissen das man in XML auch mit Namensräumen arbeiten ähnlich C/C++ der Scope–Operator kann dann folgendes auftauchen.
Siehe doppelter Doppelpunkt.<rss::name ...>
<channel::name ...></channel::name>
</rss::name>
*3.2Die wichtigen Tagelemente zwischen dem Channel–Tag
<item>
<title>...</title>
<link>...</link>
<description>...</description>
</item>
*Diese Tags sind innerhalb des Channel–Elements sind unbedingt erforderlich. Pro Information die der RSS Feed verwaltet wiederholt sich das Element item. Es sollte auch einleuchtend sein das diese Element auch attributiert sein können, als auch das wiederum Namensräume zum Einsatz kommen können. Wenn einem nicht klar ist was mit Attributierung und Namensräumen bei XML gemeint ist sollte sich nochmal mit XML beschäftigen.
Zu gerade vorangegangener Bemerkung sei hierzu auf diesen Link verwiesen http://de.selfhtml.org/
Bleibt also nur noch wie unsere RSS Feed Reader arbeiten sollte. Die Tagnamen sind selbsterklärend genug, denke ich.4.Die angestrebte Arbeitsweise des Feed Reader
4. 1 Die GrundfunktionalitätMan muss den URL zum RSS Feed erfassen können
Man setzt HTTP ein um den Zugriff auf das Webdokument (RSS Feed) zu erlangen
Man lädt sich die Daten per HTTP lokal auf seinen Rechner
Man muss die Daten (im XML – Skript) parsen
Man stellt die geparsten Daten geeignet dar4.2Unterstützende Klassen des .NET–Framework für die Problemstellung
TextBox–Klasse o. Ähnliches zum erfassen des URL auf den RSS Feed
HttpWebRequest–Klasse um per HTTP eine Verbindung zum Webdokument (RSS Feed) zu erhalten
HttpWepResponse–Klasse ist eng in Verbindung mit der HttpWebRequest–Klasse zu sehen, da diese
Klasse eine Instanz vom Typ HttpWebResponse erzeugt Zudem beinhalte diese Instanz das Webdokument, es ist somit lokal für uns verwertbar. Diese Instanz erzeugt nun wiederum ein Stream–Objekt was man einem XmlTextReader–Objekt zuführen kann.
Mit der XmlTextReader–Klasse lässt sich das gewonnene XML–Dokument parsen, eben auf die Elemente die ich unter den Punkten 3.1 als auch 3.2 angesprochen habe.Wenn man ganz zu Fuss parsen möchte gibt es im .NET–Namensraum System.Text.Regularexpressions auch die sehr nützliche Klasse Regex. Dazu sollte man das Webdokument was im HttpWebResponse–Objekt steckt, in eine
Variable vom Type String bringen. In der MSDN.microsoft.com stehen schöne Beispiel wie man Regex–Klasse einsetzen tut. Einen Link will ich nathürlich nicht vorenthalten siehe:http://search.microsoft.com/search/results.aspx?qu=Regex&View=msdn&st=b&c=0&s=1&swc=0
4.3Interoperabilität oder Browserautomation ein anderer nützlicher Ansatzpunk
Die Grafik zeigt das man in seinem .NET–Projekt Verweise aufnehmen muss, 2 an der Zahl, wenn man diese
interessante Technik auch benutzen will.SHDOCVW.dll hat intern eine Klasse SHDocVw.InternetExplorer zur bidirektionalen Verbindung zwischen Browser
und unserer Anwendung
mshtml.tlb bietet eine unterstützende Klasse zur Konvertierung einer Information, die in einer Instanz von SHDocVw.InternetExplorer vorliegtNur soviel mit einer Instanz SHDocVw.InternetExplorer haben wir eine direkt Draht zu unserem Internetexplorer.
Wenn dieser eine Seite fertig geladen hat, liegt in deren öffentlichen Member Document die Webseite lokal vor.
Man muss diesen Member in Objekt des Types mshtml.HTMLDocumentClass umcasen um es konkret verwertbar zu machen. Diesen Typ hat man nur wenn man den 2. Verweis in seinem Projekt hat siehe der obigen Grafik.Um mehr über Interoperabilität zu erfahren sollte man einmal http://www.google.de/ benutzen. Folgender Suchquery sollte einiges bringen, den man mit Google verwenden sollte:
intext:"SHDocVw.InternetExplorer" + intext:"mshtml.HTMLDocumentClass"
Code – Schnipsel sind da manchmal sehr aufschlussreich. An der Stelle füge ich selbstverständlich auch einen Link ein der auf einen Beitrag von mir verlinkt:
Wie lange der Link aktiv auf meinen Beitrag verweist, hängt nathürlich davon ab wie lange die Webdatenbank des Forums Beiträge speichert. Da der Beitrag aber denke ich nicht im .NET-FAQ des Forums(http://www.c-plusplus.net/forum/viewforum-var-f-is-29.html) ist wird er irgendwann mal tot sein.
Aber egal durch Google wird man mit etwas Geschick ähnliches jederzeit reproduzieren können!5 Das GUI meines RSS Feed – Readers auf Basis der vorangegangenen 4 Punkte
In die 4 Punkte sind viel Internetrecherchen und Gedankengänge von mir eingeflossen. Software–Engineering durch
UML, PAP und Nassi Schneidermann habe ich bewusst weggelassen. Das Beispielprojekt ist so einfach das sich das meines Erachtens nicht gelohnt hätte.
Der Menüpunkt Konfiguration erlaubt das der RSS Feed–Reader auch über einen Proxyserver funktioniert.
Als Ausgangspunkt für eine Weiterentwicklung sollte das Projekt eine ausreichende Grundlage sein.
Das Projekt kann man sich nathürlich in Form einer gepackten Datei (WinRAR) runterladen.http://www.c-plusplus.net/magazin/bilder/RSS/Version1.1a.rar
Nachwort
An manchen Stellen bin ich vielleicht vom 100sten ins 1000ste gekommen, oder vielleicht auch nur fast.
Und um es kurz und knackig zu halten sollte soetwas selbstverständlich nicht passieren. Trotzdem sollte
der Beitrag auch etwas über den Tellerrand lunzen, siehe die Interoperabilität in der nathürlich viel mehr steckt.Mit freundlichen Grüssen sclearscreen