[X] Lesen von RSS-Feed durch Einsatz des DataSet
-
estartu schrieb:
Da es bei Artchi und mir nur um die Bildgröße bzw. einige Leerzeichen zuviel/Zeilenumbrüche zuwenig geht, kannst du meinetwegen loslegen.
")
geht das bei den anderen auch klar??? oder wollt ihr da noch was ändern??
Mr. B
-
Bin auf ner LAN mache das mit dem Bild morgen sorry habt bitte Verständniss
"argh mir fliegen im Level gerade die Kugeln um die Ohren..."

Bis denn
-
so ich habs jetzt um 20 Pixel kleiner gemacht *hmm* ist nicht viel
ich benutze Gimp dazu, mache ichs aber noch kleiner wirds unscharf.
K.A. Die Funktionen von Gimp erschlagen mich einfach K.A. wie ich das wenn ichs noch kleiner mache wieder scharf kriege

"Paprika draufstreuen bringt wohl auch nichts"

P.S.: Ich logge mich erstmal mit FP-Surfer aus, ich denke wird mir schon jemand einen Tipp geben zu Gimp. Paint hat ja nichtmal nee Skalierungsfunktion
schade.
-
sclearscreen schrieb:
so ich habs jetzt um 20 Pixel kleiner gemacht *hmm* ist nicht viel
Für die 1028x1024 Auflösung passt es jetzt, die 1024-Leute müssen noch scrollen.
ich benutze Gimp dazu, mache ichs aber noch kleiner wirds unscharf.
hm? Bei mir nicht. Ich kann's auf 75% der jetzigen Größe bringen, ohne dass es unscharf wird.
MfG
GPC
-
Benutzt du kein Vektorbasiert-Grafikprogramm dafür?
 Powerpoint oder das Präse-Programm aus OpenOffice sind dafür ideal. Kannste skallieren wie du lustig bist.
Powerpoint oder das Präse-Programm aus OpenOffice sind dafür ideal. Kannste skallieren wie du lustig bist.
-
Also, nur durch Abschneiden kriege ich es auf unter 1000 Pixel Breite.
Und sooo unscharf wird es dann auch nicht, wenn man es mit IrfanView weiter verkleinern lässt.
-
Da sieht man mal wieder das ich ein Torfnase bin!!!
Abschneiden hmm bin ich nicht draufgekommen tzzzz
Manchmal denke ich ich bin schon verkalkt 
Kann ich davon ausgehen das ich an dem Bild jetzt keine Hand mehr anlegen brauche???
-
sclearscreen schrieb:
Kann ich davon ausgehen das ich an dem Bild jetzt keine Hand mehr anlegen brauche???
Also ich hab nur Beweisführung betrieben, aber nichts hochgeladen. Schätze estartu hat das selbe getan

-
Artchi schrieb:
Benutzt du kein Vektorbasiert-Grafikprogramm dafür?
Powerpoint oder das Präse-Programm aus OpenOffice sind dafür ideal. Kannste skallieren wie du lustig bist.Bis auf Paint und Gimp habe ich noch nicht weiter ueber Teller geguckt!
-
GPC schrieb:
sclearscreen schrieb:
Kann ich davon ausgehen das ich an dem Bild jetzt keine Hand mehr anlegen brauche???
Also ich hab nur Beweisführung betrieben, aber nichts hochgeladen. Schätze estartu hat das selbe getan
Ich KANN momentan nichtmal was hochladen.
Siehe PC Forum.
-
estartu schrieb:
GPC schrieb:
sclearscreen schrieb:
Kann ich davon ausgehen das ich an dem Bild jetzt keine Hand mehr anlegen brauche???
Also ich hab nur Beweisführung betrieben, aber nichts hochgeladen. Schätze estartu hat das selbe getan
Ich KANN momentan nichtmal was hochladen.
Siehe PC Forum.Ja, das Leben ist hart, aber wir sind, äh, egal
Hab das Bild jetzt mal auf 80% skaliert und hochgeladen, was meint ihr? Kann man's noch lesen und müssen die armen Teufel mit 1024er Auflösung noch scrollen *renn & duck*
")
-
Hat sich da wirklich was geändert?
Ich muss bei ner 1100er Auflösung wieder scrollen.
-
estartu schrieb:
Hat sich da wirklich was geändert?
Ich muss bei ner 1100er Auflösung wieder scrollen.Hm, das könnte an dem Post über dem Artikel liegen, da ist noch so n fettes Teil drin. Aber das Bild selber, das hab ich wirklich verkleinert.
-
Test:
Ahja, also so geht es bei 1100.
-
1024?
Für Leute wie ich, die einen TFT mit 1024er Auflösung haben (und bekanntlich hat ein TFT nur eine Auflösung) ist es einfach nicht schön so einen Text zu lesen.
-
@sclearscreen, poste noch mal den Artikel hier rein, damit wir n neutrales Bild haben.
@Artchi, ja wie, klappt's nicht? Musst du noch scrollen?
-
Sorry, geht jetzt! *verwirrt'*
-
GPC schrieb:
@sclearscreen, poste noch mal den Artikel hier rein, damit wir n neutrales Bild haben.
@Artchi, ja wie, klappt's nicht? Musst du noch scrollen?
wird gemacht moment bitte!
-
RSS Feed mit dem DataSet
Autor: sclearscreen
IDE: Visual Studio 2003 Standard
Betriebssystem: WindowsXP
Vorwort:
Ganz kurz gesagt wer sich meinen vorherigen Beitrag angeschaut und das Projekt gezogen hat, wird beim testen einen Bug feststellen.
Es ist kein schwerwiegender Fehler der den ganzen Desktop-PC zum abstürzen bringt. Dieser Bug
veranlasst auch nicht das Programm sich ins System zu verabschieden. Nein das Programm parst beim Umgang mit RSS Feed, einer bestimmten Version, nicht alle Daten aus. Sprich das Parsen des XML funktioniert nicht richtig. Bei dem Algorithmus zum parsen des XML hatte ich voll auf Eigenbau gesetzt was nicht ganz von Erfolg gekrönt war. Soll ich als Autor dabei nun lachen oder weinen? Eher lachen es zeigt einem es geht besser und zudem hat man gleich
neun Stoff fuer einen neuen Beitrag.Also auf ans Werk.
Inhalt:
1 Refactoring des Programm
1.1 Wo muss das Refactoring angesetzt werden?
1.2 Was hat das Refactoring am Code verändert?
2 Was lernt man daraus?
3 Zum Testen gebe ich dem Der/Die möchte die Lösung nochmal auf den Weg
3.1 Die Methode ohne Verwendung eines Proxyserver
3.2 Die Methode mit Verwendung eines Proxyserver
3.3 Verwenden kann die 2 Methoden dann bespielsweise so
4 Haftungsauschluss fuer etwaige Schäden an Hardware/Software des User1.Refactoring des Programm
1. 1 Wo muss das Refactoring angesetzt werden?Ich werde vorher mit Hilfe von UML den Weg der Daten bis zum Bug deutlich machen und die fehlerhafte Implementierung dieser Stelle dann aufzeigen. Sollte manches an der UML-Symbolik nicht ganz so stimmen bitte ich das zu verschmerzen. Ich benutzte OpenOffice was nicht alle Standardformen Rechtecke, Verbindungspfeile bereitstellt. Dahert ist es mir nicht möglich spezielle Besonderheiten bei UML zu berücksichtigen. Beispielsweise kann man durch Verbindungspfeile
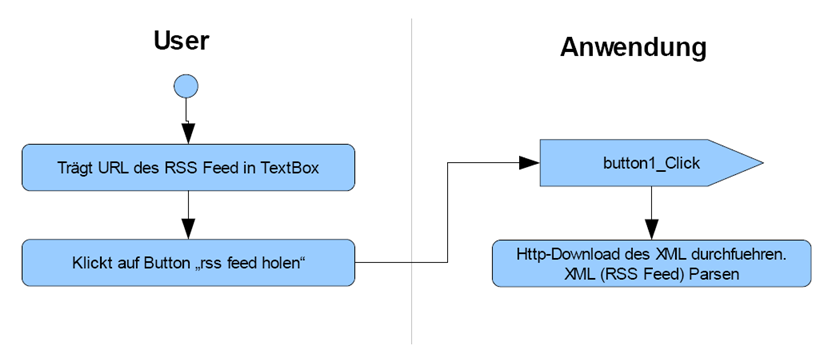
kein asynchrones Verhalten bei Prozessaufrufen darstellen, wo man eine Verbingungspfeil mit einer halben Pfeilspitze zur Darstellung braucht. So genug abgeschweift zur Sache.Wir beginnen mit einem Aktivitätendiagramm was die Interaktion des User mit seinem Reader kurz nach dem Start der Anwendung zeigt.
Ich hoffe jetzt fällt dem aufmerksamen Leser etwas auf was uns die UML-Symbolik als Signal verkauft/darstellt! Dies ist eine Methode die als Callback-Funktion fuer den Button genutzt wird.
Und eben diese Callback-Funktion, stoesst ihrerseits in Ihrem Rumpf den Code zum Dowload und Parsen des Feed an. Genau dort liegt der Hase im Pfeffer.
In diesem Code interagieren 4 Klassenobjekte miteinander um das XML-Script des RSS Feed per Http zu holen. Eines der Klassenobjekte ist eine Instanz des Types XmlTextReader.
Der Algorithmus des Parsen bestand nun darin genau dieses Objekt mit Ablaufstrukturen sinnvoll zu kombinieren, um an die heiß begehrten item-Tags zu kommen.Genau dies passiert in folgendem Block

Die Implementierung, zu diesm Block, findet man in/unter folgender Methode (siehe Projekt aus meinem 1. Beitrag)
private void button1_Click(object sender, System.EventArgs e) { . . . }Innerhalp der Methode wird per Http ueber 2 Klassen
WebRequest und WebResponse ein Stream-Objekt gebildet was einem XmlTextReader gegeben wird.
Der ganze Weg bis zur Stream-Gewinnung und der Instanzierung des XmlTextReader
arbeitet normal und nach meiner Erwartung.XmlTextReader xmltextReader = new XmlTextReader(this.rssFeed.GetResponse().GetResponseStream());Nach dieser Zuweisung beginnt der Eigenbaualgorithmus zum Parsen des XML der sich als zu unfelxibel gegenuber RSS Feed der Version 1.0 erweisst.
2 der der 3 notwendigen Tags werden nicht ausgeparst. Es ensteht dabei auch keine Endlosschleife die das GUI einfrieren lässt.
Kurzer Hand hatte ich mir einen Feed der Version 1.0 auf meine Platte geladen. Da die Klasse XmlTextReader auch aus Dateien lesen kann habe ich die Instanzierung auf diese XML-Datei umgestellt. Somit konnte ich problemloser Schrittweise debuggen ohne auf das Netzwerk/Internet angewiesen zu sein.
Dies hätte unter Umständen das Debuggen erschwert.Nach der Umstellung auf den nun lokalen Feed der Version 1.0 stellt man fest, das der Algorithmus dann eben bei jedem „item-Tag“ nur einen der 3 Tags ausparst. Hat der Algorithmus dies gemacht springt dieser zum naechsten „item-Tag“ und vergisst somit eine Child-Knoten zu lesen, dies genau ist besagter Bug.
Ich gebe zu an dem Punkt hatte mir dann die Muse gefehlt, um den Algorithmus zu verbessern. Die Gefahr einer Endlossschleifen innerhalb der while-Schleife erachtet ich zu gross.
Eine einfacherer Lösung auf Basis von vorhanden Komponenten ist immer besser als das Rad weiter neu zu erfinden.
Da ich wusste das die Klasse DataSet mit XML umgehen kann gerade im Bezug auf Datenbanken, versuchte ich 1 und 1 zusammenzuzählen.
RSS Feed sind aufgrund ihrer interen Struktur datenzentriert also ideal zur arbeit mit Datenbanken ausgelegt. Hinzu kommt das DataSet kann XML Laden als auch Speichern, beim Laden kann es seine Daten aus einem Stream-Objekt bekommen als auch von einem XmlTextReader-Objekt bekommen.
Also wenn sich diese Gedanken nicht gut anhören, es ergab sich eine funktionsfähige Lösung innerhal von 10-15 Minuten. Das Hilfesystem und die MSDN haben sich dabei wiedermal bewährt.
1.2 Was hat das Refactoring am Code verändert?
Folgenden Code wurde somit aus dem Projekt durch auskommentieren verbannt:
while(xmltextReader.Read() == true) { if(xmltextReader.Name == "item") { while(xmltextReader.Read()) // weiterlesen im Element <ITEM> { switch(xmltextReader.Name) // lesen bis wir .... { case "title": { if(titlereaded != true) { while(xmltextReader.Read() == true && xmltextReader.NodeType != XmlNodeType.Text); this.textBox2.Text = this.textBox2.Text + "TITLE: " + xmltextReader.Value + "\r\n"; titlereaded = true; // merken Uns das Titel gefunden ist } break; } case "link": { if(linkreaded != true) // doppeltes Lesen verhindern { while(xmltextReader.Read() == true && xmltextReader.NodeType != XmlNodeType.Text); this.textBox2.Text = this.textBox2.Text + "LINK: " + xmltextReader.Value + "\r\n"; linkreaded = true; // merken Uns das Link gefunden ist } break; } // und auch das 3. Kernelement Description wurde gefunden case "description": { // doppeltes Lesen der Description verhindern if(descriptionreaded != true) { while(xmltextReader.Read() == true && xmltextReader.NodeType != XmlNodeType.Text); this.textBox2.Text = this.textBox2.Text + "DESCRIPTION: " + xmltextReader.Value + "\r\n"; descriptionreaded = true; // merken uns das Description ist } break; } default: break; // hier Sind es optionale Tags des <ITEM> - Elementes } // Wir prüfen jetzt ab ob Wir alle 3 Kernelemente des <ITEM> - Elementes gefunden haben if(titlereaded == true && linkreaded == true && descriptionreaded == true) // break; // alles nötige für diesen einen News - Feed ist ausgelesen } titlereaded = false; linkreaded = false; descriptionreaded = false; this.textBox2.Text = this.textBox2.Text + "---------------------------------\r\n"; } }Das vorangegangene Listning wird ersetzt gegen folgende kurze Sequenz. Ich war jedenfalls froh das dieses Geschoss vom Tisch war
DataSet ds = new DataSet("RSS-Feed: " + this.textBox1.Text); System.IO.Stream stream = this.rssFeed.GetResponse().GetResponseStream(); XmlTextReader xmltextReader = new XmlTextReader(stream); ds.ReadXml(xmltextReader); DataTable dt = ds.Tables["item"];Der neue Code liesst sich auch viel besser. Und man bekommt auch einen Wink mit dem Zaunpfahl, was Wiederverwendung von getestet Komponenten ausmacht.
Und das bekommt man so ganz gratis mit dem Framework dazu. Eine Lösung mit 5 Zeilen Code gegenueber ich weiss nicht wieviel Zeilen. Diese 5 Zeilen ersetzen die While-Schleife mit den ganzen eingeschachtelten Ablaufstrukturen.
Man brauch sich jetzt wirklich nur ein DataGrid auf sein Formular ziehen und weist desen Eigenschaft DataSource eine der Variablen ds oder dt zu funktioniert beides.
Im Verlauf der naechsten Sachen die man mit dem DataGrid anstellen kann erinnert man sich
an die Sache mit dem HitTestInfo. Da bekommt man angeklickte bzw aktivierte Zellen im DataGrid
zurueck. Somit kommt man an den Url ran der in der Spalte mit dem Namen „link“ im DataGrid auftauchen wird.Nachdem man durch folgenden Code:
datagrid1.DataSource = dt;Das DataSet dem DataGrid bekannt macht, ist man in der Lage ueber HitTestInfo Informationen aus dem DataGrid zu holen.
Man kann dem Browser also Informationen aus der Spalte mit
dem Namen "Link" zufuehren.Der Browser biete ja durch das Browser-Control Interoperabilität mit Anwendungen. Das ist somit die ganze Kunst, um einen richtigen Feed-Reader zu bauen.
2.Was lernt man daraus?
a) Es ist immer gut und praktikabel sich mit der Klassenbibliothek des Framework
ausseinanderzusetzen. Es bringt bessere Lösungen.b) Man baut ausgiebig auf bereits getesten Code auf, was Wiederverwendbarkeit und Wartbarkeit
fördert.c) durch Verwendung bestehender getesteter Klasssen wird Code sicherer unter Umständen kürzer
als auch lesbarerd) Die genannten Dinge bringen nur was wenn man Kenntnisse ueber das jeweilige Framework hat.
Man ist im Bezug auf die 4 Punkte immer gut beraten die MSDN, Foren und das Internet zu benutzen.
3. Zum Testen gebe ich dem Der/Die möchte die Lösung nochmal auf den Weg
folgende Methode kann man in sein Projekt kopieren, einfach in die gewünschte Klasse als Methode reinkopieren. Existiert in 2 Varianten nicht ohne Grund!!!
3.1 Die Methode ohne Verwendung eines Proxyserver
// Achtung Methode kann je nach Netzwerk wenn nen Proxy zwischen euch sitzt ne Exception werfen private DataTable GetRssFeedItems(string Url) { // Dies Teil transferiert die Daten des RSS Feed zu unseren Rechner auch hier // könnte ne Exception auftreten aber die Meldung bekommen Wir auch in die Statuszeiel System.Net.HttpWebRequest rssFeed = (System.Net.HttpWebRequest) (WebRequest.Create(Url)); // Der XmlTextReader bekommt einen Netzwerkstrem direkt vom HttpWebRequest - // Objekt // dies Teil könnte ne Exception werfen das sehen Wir dann aber in der Statuszeile DataSet ds = new DataSet("RSS-Feed: " + Url); System.IO.Stream stream = rssFeed.GetResponse().GetResponseStream(); System.Xml.XmlTextReader xmltextReader = new System.Xml.XmlTextReader(stream); ds.ReadXml(xmltextReader); return (ds.Tables["item"] as DataTable); }3.2 Die Methode mit Verwendung eines Proxyserver
private DataTable GetRssFeedItems(string Url, string proxyAddresse, string proxyPort, string username, string passwort) { // Dies Teil transferiert die Daten des RSS Feed zu unseren Rechner auch hier // könnte ne Exception auftreten aber die Meldung bekommen Wir auch in die Statuszeiel System.Net.HttpWebRequest rssFeed = (System.Net.HttpWebRequest) (WebRequest.Create(Url)); // ToDo: Wenn es hier ne Exception gibt, kann es daran liegen das ein Proxy zwischen uns // und dem Internet sitzt! Wir probieren es daher mit der Proxyauthentifizierung. // Man nehme diese Proxydaten aus dem Lokalen Browser rssFeed.Proxy = new System.Net.WebProxy(proxyAddresse + ":" + proxyPort); rssFeed.Proxy.Credentials = new System.Net.NetworkCredential(username,passwort); // Der XmlTextReader bekommt einen Netzwerkstrem direkt vom HttpWebRequest - // Objekt // dies Teil könnte ne Exception werfen das sehen Wir dann aber in der Statuszeile DataSet ds = new DataSet("RSS-Feed: " + Url); System.IO.Stream stream = rssFeed.GetResponse().GetResponseStream(); System.Xml.XmlTextReader xmltextReader = new System.Xml.XmlTextReader(stream); ds.ReadXml(xmltextReader); return (ds.Tables["item"] as DataTable); }3.3 Verwenden kann die 2 Methoden dann bespielsweise so
try // Versuch den Stream normal zu holen { this.dataGrid1.DataSource = GetRssFeedItems("http://www.rss-verzeichnis.de/updates.xml"); } catch(System.Exception ex) // Exception kommt wenn ein Proxyserver dazwischen ist { MessageBox.Show(ex.Message); try // Versuch den Stream zu holen trotz Proxy { this.dataGrid1.DataSource = GetRssFeedItems("http://www.rss-verzeichnis.de/updates.xml", "100.100.100.100", // P.S.: fiktive ProxyIp "8080", "AlfonzDerUser", "AfonzesPasswort"); } catch(System.Exception ex) { // Punkt an dem es keinen Sinn macht die Anwendung weiter fortzusetzen // Stream konnte mit normaler Internetverbindung nicht geholt werden // Stream konnte auch nicht mit dem zwischengeschalteten Proxy beschafft werden MessageBox.Show(ex.Message); // Gruende: // - falscher Proxy (Proxydaten, Proxyserver inaktiv) // - Webserver mit RSS Feed inaktiv // - Internetverbindung aus verschiedene Gruenden inaktiv } }Wie man sieht wenn man die Methoden benutzt ist es ratsam try/catch zu verwenden ich habs ja als Kommentar in der einen Metode angekündigt.
4 Haftungsauschluss fuer etwaige Schäden an Hardware/Software des User
Man kann ja nie wissen! Ich will also fast hier am Ende nochmal darauf hinweisen, das Jeder/Jede
der Inhalte aus meinen Beiträgen nutzt, dies auf eigene Gefahr tut!
Ich übernehme keinerlei Haftung fuer Schäden die durch den Download, Nutzung oder Änderung an dem aufgeführten Quellcode aufgetreten sind.Ich teile gerne Erfahrung aber man muss sich absichern gerade heute. So das wäre auch geklärt denke ich. Bleibt nur noch das Nachwort oder der Nachtrag.
Nachtrag
So damit kann ein[e] Interessierter/Interessierte seinen/ihren Spieltrieb freien Lauf lassen die Sache mit dem Mozillabrowser habe ich bewusst aussen vor gelasssen. Einen Browser noch reinzupacken sollte kein Problem darstellen. Es gibt Beispiele zuhauf im Netz. Ausserdem nur durch rumspielen und rumexperimentieren erlangt man Wissen.
Beim DataGrid sollte man an die Sache mit dem HitTestInfo denken! Darüber gelangt man dann an den URL der im Feed steckt und kann somit ein Browser-Control mit Urls versorgen.
Hier brauch man den Url dann nur noch mit der Navigate-Methode des Browserobjekt in Einklang bringen schon hat man den RSS-Reader fertig. Daran laesst sich noch viel machen.
Verwaltung von Urls auf die Feeds etc.
Den Beitrag als PDF
http://www.c-plusplus.net/magazin/bilder/RSS/refactoring_RSS_Feed_mit_dem_DataSet.pdf
-
Passt wie angegossen.