[X] Einführung in Codepages und Unicode
-
 Genial! Hat wirklich noch niemand einen autom. Counter geschrieben???
Genial! Hat wirklich noch niemand einen autom. Counter geschrieben??? 
-
^^ nö. Irgendwie müssen wir unser dasein ja auch rechtfertigen
")
-
1 Kleiner Historischer Abriss
Schon vor langer Zeit haben die Menschen das Bedürfnis gehabt etwas aufzuschreiben. Damals hat man noch Schildkröten statt Papier verwendet, aber vom Prinzip hat sich bis heute nicht viel daran geändert.
Bis die Computer kamen... dann hatte man das Problem, dass die Schriftzeichen sich so schwer in den Bildschirm ritzen ließen. Dieses Problem hatte man übrigens nicht erst mit den Computern sondern auch schon früher, als man versucht hat Nachrichten ohne Steintafeln/Papier zu übertragen (z.B. via Optische-Telegraphie).
Es musste also eine Codierung für die Zeichen her. Upps, da wir gerade bei Zeichen sind: Das was umgangssprachlich als "Zeichen" verstanden wird, ist i.d.R. ein "Glyph".
Aber nun zurück zu den Computern und das Problem mit den Zeichen... Der Computer versteht (bis heute noch) nur Bits (also 0 und 1), also musste etwas erfunden werden, was sich mit 0 und 1 darstellen lässt. Einer der ersten Zeichensätze für solche Zwecke war der "Baudot-Code" (obwohl es zu dieser Zeit noch gar keinen Computer gab). Davon abgeleitet wurde dann der CCITT-2 Code zum Standard in der Telex Übertragung (welches heute noch in Deutschland existiert!).
Erst 1967 wurde dann der ASCII Standard definiert, welcher aus 7-Bit besteht und noch heute Gültigkeit hat und die Basis für die meisten Codierungen ist.
Mehr Infos zur Historie gibt es auch bei Heise.
2 Die Folgen von ASCII
Der ASCII Zeichensatz hatte ein großes Problem: Er wurde von den Amerikanern definiert, deren Horizont kaum über den Teich reicht. Somit wurden nur Zeichen aufgenommen, die drüben bekannt waren. Nicht einmal Zeichen die in Europa oft verwendet werden (z.B. ä, ö, ü, ß, á, à, usw.) wurden berücksichtigt.
Aus dieser Not heraus wurden diverse Codepages erfunden. Die meisten dieser Codepages (also Kodierungen, welche mehr als nur ASCII-Zeichen enthalten) wurden durch die ISO in der Norm ISO 8859 standardisiert. Diese Codepages bestehen aus 8-Bit und können somit 2^8 Zeichen (256) adressieren. Die meisten dieser Codepages verwenden in den ersten 128 Zeichen dieselben Zeichen wie im ASCII Standard. Somit sind nur die letzten 128 Zeichen in einer Codepage unterschiedlich. Die ISO hat aber nur Zeichensätze aufgenommen, die im westlichen Umfeld gebräuchlich waren. Damit wurden auch hier keine Asiatischen Zeichen kodiert, welches wiederum diverse Länderspezifische Kodierungen hervorbrachte (z.B. Big5, GB2312 und Shift-JIS).Auch in Windows halten sich alle Codepages in den ersten 128 Bytes an den ASCII Standard und nur die oberen 128 Bytes sind Codepage-Spezifisch (naja, es gibt auch Ausnahmen: so hat z.B. die Windows Codepage 932 (Japanisch) oder 949 (Koreanisch) an der Position 0x5C nicht ein Backslash sondern ein YEN bzw. ein WON Zeichen; siehe auch: When is a backslash not a backslash?).
2.2 Kodierung von mehr als 256 Zeichen
Durch die Einschränkung auf 256 Zeichen (SBCS: Singlebyte Character Set; es wird nur ein Byte für ein Zeichen benötigt), welche aus den gebräuchlichen 8-Bit für ein Zeichen hervorgeht, haben alle Sprachen Probleme, welche mehr als 256 Zeichen verwenden. Um dieses Problem zu lösen wurde das Multibyte Character Set erfunden.
Bei MBCS wird für ein Zeichen min. 1 Byte verwendet. Es gibt aber auch viele Zeichen, für die 2 und mehr Bytes verwendet werden (bei solchen Zeichen werden die ersten Bytes als "Lead-Byte" bezeichnet). Mit dieser Technik können beliebig viele Zeichen Kodiert werden.
In der Praxis gibt es kaum MBCS Zeichensätze. Die meisten Kodierungen verwenden nur DBCS (Doublebyte Character Set) welcher maximal 2 Byte zur Kodierung eines Zeichens verwenden (so z.B. auch alle unterstützten MBCS von Microsoft).
2.2 MBCS und die Auswirkungen auf die Programmierung
Das Handhaben von Zeichenketten war in C schon immer ein Problem. Neben den vielen Programmierfehlern bzgl. zu kleiner Puffer ist mit dem Aufkommen der MBCS noch ein weiteren Problem dazugekommen, welches sich viele Programmierer nicht bewusst sind: Ein Zeichen kann aus mehreren Bytes bestehen!
Vielen werden jetzt zwar denken: Was geht mich das an! Im Folgenden will ich versuchen darauf einzugehen (PS: Man kann das Problem natürlich auch ignorieren, nur wird man dann bestimmte Gebiete (z.B. Asien) von seinem Programm ausschließen).
2.2.1 Wie lang ist ein MBCS String?
Hier scheiden sich schon die Geister: Was ist denn genau gemeint? Will der Frager die Anzahl der Zeichen (Glyphs?) wissen oder die Anzahl der Bytes? Will man z.B. in einer Textverarbeitung die Anzahl der Zeichen zur Information anzeigen (wie es ja einige machen), so will man sicherlich die Anzahl der "Glyphs" wissen. Bei einem MBCS-Zeichensatz kann dies aber weniger sein, als der String in Bytes lang ist. Somit ist ein einfaches
strlennicht mehr ausreichend. Man muss also immer noch etwas über den tatsächlich verwendeten Zeichensatz wissen um die Anzahl der "Glyphs" zu ermitteln. Hier taucht gleich das zweite Problem auf: Bei den MBCS sind nicht alle Byte-Folgen gültige Zeichen! So ist z.B. bei Shift-JIS die Zeichenfolge 0xE6 0x40 ein gültiges Zeichen wo hingegen 0xE6 0x7F kein definiertes Zeichen ist.Leider gibt es für MBCS-Unterstützung keine (zumindest mir bekannte) Normierung in der C/C++ Welt. Microsoft hat hierfür eine eigene Erweiterung zur Verfügung gestellt, welches hier unterstützt (
_mbslen(ohne Prüfung auf Gültigkeit des Strings) und_mbstrlen(mir Prüfung auf Gültigkeit des Strings)). In Linux (g++) sind mir keine Funktionen bekannt, welche die Anzahl der "Glyphs" für verschiedene Codepages zurückliefern (für UTF8 gibt es wohlg_utf8_strlen).2.2.2 Suchen von Zeichen in Strings
Um z.B. ein bestimmtes Zeichen in einem String zu suchen, nimmt man ja i.d.R.
strchr. Wenn z.B. nach einem Unterstrich (_) suchen will, so ist dies bei einem SBCS ja trivial. Bei einem MBCS wird es hingegen schon sehr komplex, da auch beachtet werden muss, ob das aktuelle Zeichen eine "Lead-Byte" ist und somit das nächste als kombiniertes Zeichen betrachtet werden muss. Ein einfaches Suchen mittelsstrchrist somit nicht mehr möglich. In der Windows Codepage 936 (Simplified Chinese GBK), ist das Zeichen U+7BF2 (Besenstiel) als "0xBA 0x5F" kodiert. Dies würde bei einer simplen Suche nach "_" (0x5F) ein Treffer liefern, was offensichtlich falsch ist.Die Probleme mit MBCS gehen noch viel weiter. So ist es z.B. für einen Benutzer einer Textverarbeitung etwas ungewöhnlich, wenn das Programm MBCS verwendet (vielleicht ohne das der Programmierer dies weis), wenn er mit dem Cursor (Caret) durch seinen Text geht (z.B. Pfeil nach rechts) und er für ein (MBCS) Zeichen zuerst "im" Zeichen landet und erst beim zweiten mal hinter dem Zeichen...
3 Die Lösung aller Probleme: UNICODE
(oder: Wie man noch mehr Probleme schafft)Um das Problem zu Lösen, dass immer mehr unterschiedliche Codepages aus dem Kraut schießen, wurde (erst) 1991 eine einheitliche Kodierung definiert, welche alle Sprachen / Zeichen aufnehmen sollte (History of Unicode 1.0). Dabei wurde schon der erste Fehler gemacht und man ging davon aus, dass 2 Byte (65536) Zeichen vollkommen ausreichen würden um alle Zeichen in der Welt abzudecken (Zitat: "16-bits wide because this provides a sufficient number of codes (65,536) to represent electronic text characters anticipated for the foreseeable future"). Naja, die "foreseeable future" war bei vielen doch wohl sehr beschränkt ;).
Zumindest wurde dem Projekt etwas Erfolg vorhergesagt, da sich alle großen Firmen (Apple, GO, IBM, Metaphor, Microsoft, NeXT, Novell, The Research Libraries Group and Sun Microsystems) beteiligten.
Die Probleme mit dem zu kleinen Adressraum wurden dann auch schon in der Version 2 behoben, indem zusätzliche 16 weitere gleich große Bereiche definiert wurden. Somit gehen die Codepoints von U+00000 bis U+10FFFF (und belegen bei 1-zu-1 Kodierung jetzt 32-Bit). Wir dürfen gespannt sein, wie lange dieser Namenraum ausreichen wird.
Die aktuelle Unicode-Version 5.0.0 enthält ungefähr 99.000 Zeichen.
3.1 Kodierungen von UNICODE
Für Unicode gibt es unterschiedliche Kodierungen. Alle beziehen sich aber auf die Codepoints (ein bestimmter Wert in dem Unicode-Coderaum; dieser Wert wird i.d.R. mittels U+xxxx oder U+10xxxx geschrieben), welche im Unicode-Standard definiert sind.
Es gibt die Folgenden Kodierungen von Unicode:
- UTF-32 (BE oder LE)
- UTF-16 (BE oder LE)
- UTF-8
- UTF-7
- UTF-EBCDIC
- PunycodeDie gebräuchlichste Kodierung ist UTF-8. Aus Sicht der Komplexität von Unicode spielt es keine große Rolle, welche der UTF-x Kodierungen man verwendet (aber dazu später).
3.2 BOM
Beim Lesen/Schreiben von Dateien existiert immer das Problem, dass man wissen muss, in welcher Kodierung diese Datei gelesen/gespeichert werden soll. Das Unicode-Konsortium hat hierfür einen BOM definiert, welcher ganz am Anfang der Datei steht und die Kodierung (für Unicode) definiert. Mit diesem BOM können aber nur die Unicode-Kodierungen unterschieden werden. Es ist nichts allgemeingültiges, womit man auch andere Codepages unterscheiden könnte.
Wenn kein BOM vorhanden ist, so kann nicht eindeutig ermittelt werden, um welches Encoding es sich bei einer (Text-)Datei handelt. Es ist einzig eine "Statistische Analyse" des Textes möglich, wie es z.B. Notepad mittels der WinAPI-Funktion
IsTextUnicodemacht.3.3 Blocks
Unicode definiert zusammengehörige Zeichen in einem Block. Ein Block ist z.B. der ASCII-Block (Basic-Latin U+0000 bis U+007F). Um für kommende Zeichen genug Platz zu lassen, entstehen natürlich in einigen Blöcken Lücken die freigelassen wurden. Daraus wird auch ersichtlich warum erst ca. 9% aller Codepoints vergeben sind.
3.4 Kategorien
Jedem Codepoint ist (min.) eine Kategorie zugeordnet. Es gibt insgesamt 33 Kategorien. Eine Kategorie ist z.B. "Letter, Lowercase" (Kleinbuchstabe). In dieser Kategorie sind z.B. 1634 Zeichen vorhanden.
3.5 Besonderheiten von Unicode
Unicode versucht alle Probleme die man mit Sprachen und deren dazugehörigen Zeichen hat zu lösen. Aus diesem Grunde ist auch der Standard schon fast unüberschaubar geworden und es gibt wohl nur wenige Menschen die alle Bereiche vollständig verstanden haben. Im Folgenden will ich einzelne dieser Besonderheiten vorstellen.
3.5.1 Zahlen
Viele Programme müssen mit Zahlen arbeiten. Aber eigentlich fast alle beschränken sich dabei auf die uns bekannten Zahlen 0-9. Im Unicode-Standard sind aber über 836 Codepoints als Zahlen (Numbers) definiert! So gibt es z.B. das Zeichen U+216B (ROMAN NUMERAL TWELVE), welches als Zahl mit dem Wert 12 definiert ist. 290 von diesen Zahlen sind als Decimal Digits definiert und können somit 1-zu-1 mir den uns bekannten Stellenwertsystem (Digits 0-9) ausgetauscht werden. 210 Zahlen sind so genannte Buchstaben-Zahlen, also Zahlen, welche sich nicht direkt mit einem "Digit" (also Zahlen die durch ein Stellenwertsystem zwischen 0 und 9 verwenden lassen) darstellen lassen. Die dritte Kategorie von Zahlen sind Sonstige Zahlen. Diese beinhalten z.B. auch Brüche (z.B. Ein viertel (1/4)) oder die Zahl "eins weniger als die vorherige".
Leider existiert auch hier in der C/C++ Welt keine mir bekannte Bibliothek, welcher diese Eigenheit von Unicode vollständig unterstützt. So "kennt" z.B. die Funktion
iswdigitje nach verwendetem OS bestimmte Zahlen nicht...Mein GCC 3.3.4 unter Linux v2.6.8 kennt z.B. die Zahl ARABIC-INDIC DIGIT FIVE nicht. Dagegen erkennt es das gleiche Programm unter Windows XP (die MS-CRT verwendet intern
GetStringTypeW, welches viele Zeichen kennt).#include <stdio.h> #include <ctype.h> int main() { if (iswdigit(0x0035) == 0) printf("'DIGIT FIVE' ist KEINE Zahl"); if (iswdigit(0x0665) == 0) printf("'ARABIC-INDIC DIGIT FIVE' ist KEINE Zahl"); return 0; }Im .NET-Framework 2.0 gibt es in der
Char-Klasse, viele für Unicode notwendige Hilfsfunktionen. So kann man z.B. mittelsusing namespace System; int main() { Console::WriteLine("'DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0035)); Console::WriteLine("'ARABIC-INDIC DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0665)); Console::WriteLine("'ROMAN NUMERAL TWELVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x216B)); }die Zahlenwerte dieser Unicode-Codepoints ermitteln.
Am Ende des Artikels findet sich noch ein Beispiel, welches alle (in .NET 2.0) bekannten Zahlen mit den dazugehörigen Werten ausgibt.
3.5.2 Combining-Characters
Die uns geläufigen Zeichen wie ä, ö, ü usw. sind ja etwas besondere Zeichen. Das 'ä' ist ja eigentlich ein 'a' mit einem Diakritischem Zeichen. Und genau dieser Sachverhalt kann auch in Unicode abgebildet werden. Das Zeichen 'ä' kann entweder als ein Verbundenes Zeichen (precomposed character) geschrieben werden (U+00E4) oder als Kombination aus einem Basiszeichen (a) und einem Diaresis (combining-character): U+0061 U+0308.
Ein Combining Character ist somit ein Zeichen, was immer mit einem Basiszeichen zusammen dargestellt wird. Es ist auch möglich, dass ein Basiszeichen mehrere Combining-Characters enthält. So ist im folgenden Bild das Zeichen U+1EAB als eine Kombination aus einem Basiszeichen und zwei Combining-Characters dargestellt:
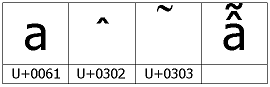
Diese Tatsache ist vielen nicht bekannt. Man sollte sich dieses aber wirklich verinnerlichen! Daraus ergeben sich erhebliche Konsequenzen. So ist z.B. das Vergleichen von Strings nicht mehr so trivial und muss ganz anders ablaufen. Auch hat es Auswirkung auf die Eingabe von Zeichen und das "Durchgehen" des Textes mittels der Cursor-Tasten. Wurde z.B. das obige Zeichen U+1EAB als Combining-Character eingeben, welches aus 3 Codepoints besteht, so wäre es für den Benutzer einer Textverarbeitung sehr verwunderlich, wenn man drei mal die "Pfeil nach rechts" Taste drücken müssen, um hinter das Zeichen zu kommen.
Hier schließt sich auch wieder der Kreis zu den MBCS-Zeichensätzen. Hier hat man nämlich genau dasselbe Problem, dass ein Codepoint nicht unbedingt ein Zeichen (Glyph) sein muss. UTF8/16 kann man ja auch als MBCS ansehen und somit wird auch deutlich, warum es eigentlich egal ist wenn man nicht UTF-32 zur Speicherung der Zeichen verwendet: Ein Aufwand bei der Darstellung und dem "durchgehen" von Zeichen hat man so oder so. Deshalb kann es nicht als Nachteil angesehen werden, wenn man intern kein UTF-32 verwendet.
3.5.3 Compatibility characters
"Compatibility characters" sind Codepoints, welche nur aufgenommen wurden um eine bessere Kompatibilität mit schon bestehenden Codepages herzustellen und somit eine einfache Konvertierung von diesen Codepages nach Unicode und wieder zurück zu ermöglichen. Man unterschiedet dabei zwischen Codepoints welche sich 1-zu-1 auf ein anderen Codepoint mappen lassen (so z.B. U+F900 welches sich direkt nach U+8C48 mappen lässt) und solchen Zeichen, die eigentlich aus mehreren Zeichen bestehen (Composite Character) aber auch mit mehreren einzelnen Zeichen angezeigt werden können (Decomposed Character). Ein Beispiel hierfür ist "bar", welches natürlich auch aus den Einzelbuchstaben bar zusammengesetzt werden kann.
3.5.4 Normalization
Aus den obigen Ausführungen kann man erkennen, dass es für einen Satz fast beliebig viele Darstellungsmöglichkeiten gibt (z.B. Combining/Compatibility-Characters). Um dieses Wirrwarr etwas zu entzerren hat man sog. "Normalisierungs-Formen" eingeführt. Jeder String kann in solch eine Form überführt werden (ist auch Voraussetzung für den Textvergleich und die Sortierung; wobei die Normalisierung dabei nur ein Schritt ist!). Es gibt die folgenden Normalisierungen:
* Normalization Form D (NFD, Canonical Decomposition):
Spaltet zusammengesetzte Zeichen in die einzelnen Bestandteile auf (wenn möglich). So wird z.B. das Zeichen 'Ä' in die Darstellung als U+0041 U+0308 überführt.
* Normalization Form C (NFC, Canonical Decomposition, followed by Canonical Composition):
Ist das Gegenteile von NFD: Hier werden zusammengesetzte Zeichen bevorzugt (wenn möglich). So wird anstelle von 'LATIN CAPITAL LETTER A', 'COMBINING DIAERESIS' das Zeichen 'LATIN CAPITAL LETTER A WITH DIAERESIS' verwendet.
Auch werden veraltete, kombinierte Zeichen durch neue ersetzt, z.B. 'ANGSTROM SIGN' wird durch 'LATIN CAPITAL LETTER A WITH RING ABOVE' ersetzt.
* Normalization Form KD (NFKD, Compatibility Decomposition):
Ist wie "Form D", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht.
* Normalization Form KC (NFKC, Compatibility Decomposition, followed by Canonical Composition):
Ist wie "Form C", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht.Bei allen diesen Normalisierungen ist zu beachten, dass es Fälle gibt in denen ein "Round-Trip" zur ursprünglichen Kodierung nicht mehr möglich ist. Auch kann sich die Bedeutung verändern (wenn z.B. das einzelne Zeichen bar durch die drei Einzelbuchstaben "b a r" ersetzt wird.
In der Windows-API kann eine Normalisierung in diese Formen mittels der Funktion
FoldStringdurchgeführt werden.Im .NET-Framework 2.0 hat die
String-Klasse eine Methode um einen String zu normalisieren bzw. abzufragen ob der String normalisiert ist (siehe dazu auch meine Anfrage an Michael Kaplan von Microsoft).
Auch gibt es in dem NamespaceSystem::Globalizationsehr viele Klassen die sich mit Unicode und sonstigen Dingen der Globalisierung beschäftigen. Ebenso in dem NamespaceSystem::Text, welche z.B. auch Klassen zur Konvertierung von Strings in diverse Zeichensätze anbietet.Linux: Es gibt wohl diverse LIBs die das können (siehe Links weiter unten).
3.5.5 BiDi-Classes
Der Unicode-Standard definiert (hauptsächlich) wie die Strings im (Haupt-)Speicher kodiert werden. Dies wird auch als "logische Reihenfolge" bezeichnet. Diese Reihenfolge muss aber nicht unbedingt mit der Reihenfolge wie die Texte dargestellt werden identisch sein! In unsere Hemisphären kennen wir eigentlich nur die Links-Nach-Rechts (LTR) Schriftarten. Es gibt aber auch Sprachen, wo die Schreibweise von Rechts-Nach-Links (RTL) geht. Da Unicode alle Zeichen und Sprachen abdeckt (besser gesagt: "fast alle", da sich das Konsortium bis heute weigert "Klingonisch" aufzunehmen; aber die beiden Sprachen (Tengwar und Cirth) von J. R. R. Tolkien will man zukünftig aufnehmen), wurden natürlich auch solche Dinge berücksichtigt. Wenn nun RTL- und LTR-Texte gemischt werden, so redet man von bi-directional Text. Um auch hier eine einheitliche Vorgehensweise zu erlauben wurden dazu für jedes Zeichen bestimmte Properties aufgenommen (also wie das Zeichen bzgl. RTL/LTR dargestellt werden soll) und es wurde eine eigene Standard-Beschreibung definiert.
Für jedes Zeichen ist somit genau definiert, wie es sich in einem BiDi Umfeld verhalten soll. Dieses Verhalten kann mit expliziten Angaben von "Schreibrichtungen" verändert werden.
Das "durchgehen" solch eines Satzes von links nach rechts ist für uns etwas ungewohnt, da die Position des Carets ungewöhnlich "springt":
 .
.In dem obigen Beispiel werden die folgenden Codepoints verwendet und diese auch in dieser Reihenfolge in der Datei/Speicher abgelegt:
U+0044 U+0069 U+0065 U+0020 U+0648 U+064E U+0631 U+0652 U+062F U+064E U+0629 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002E
Die Reihenfolge auf dem Bildschirm ist aber eine etwas andere:
U+0044 U+0069 U+0065 U+0020 U+0629 U+064E U+062F U+0652 U+0631 U+064E U+0648 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002EHierzu noch eine kleine Quizfrage: Wenn das Caret mitten in einem RTL Text steht und man "Backspace" drückt, in welche Richtung bewegt sich das Caret und welches Zeichen wird gelöscht?
Den genauen Algorithmus zum Erzeugen eines Sortkeys zu beschreiben würde den Rahmen dieses Dokumentes bei weitem Sprengen. Für detaillierte Infos, siehe den #TR9-Standard.
(PS: Es ist nicht so schlimm wenn man es nicht ganz verstanden hat, Microsoft hat es auch noch nicht
)3.5.6 Textvergleich und Sortierung
Ein Textvergleich von Unicode-Strings ist eines der komplexesten, was es im Unicode Standard gibt (noch komplexer als BiDi!). Der (aktuelle) Textvergleich wird durch den "Unicode Technical Standard #10 (Unicode Collation Algorithm)" definiert. Ausgedruckt ergibt dies bei mir ca. 78 DIN A4 Seiten.
Ganz grob kann man sagen: Jedem Codepoint (Zeichen) ist ein (oder mehrere) Gewichtungsfaktor(en) zugeordnet. Anhand dieser Gewichte und anderen Kirterien (z.B. Ignorierung der Groß- und Kleinschreibung) wird ein "Sort Key" zusammengestellt, mit dem dann ein String verglichen werden kann. Diese Gewichtungsfaktoren sind entweder explizit für ein Zeichen definiert oder er kann aus der Position und sonstigen Eigenschaften berechnet werden.
Ein kleines Beispiel: Es soll der Sort-Key für den String "Öde" erstellt werden.
Hierzu muss man zuerst den String in die Normalform NFD bringen. Dies ergibt dann
U+004F U+0308 U+0064 U+0065.
Nun muss in der Tabelle für die Weights nachgeschaut werden und daraus ergibt sich das folgende "Collection Element Array":(113B.0020.0008), (0000.0047.0002), (1010.0020.0002), (1029.0020.0002)Nun hat man die Gewichte für alle 4 Zeichen. Dabei ist der erste Eintrag das Primäre Gewicht, der zweite das Sekundäre Gewicht und das dritte das Tertiäre Gewicht.
Aus diesem "Collection Element Array" wird nun der Sortkey gebildet, indem man die primäre, sekundäre und tertiäre Gewichte in der richtigen Reihenfolge anordnet (und man lässt die Zahlen weg, welche 0 sind). Daraus ergibt sich dann der Sortkey:113B, 1010, 1029 | 0020, 0047, 0020, 0020 | 0008, 0002, 0002, 0002Diese Zahlen kann man nun mit anderen Sortkeys mit einem "normalen"
memcmpvergleichen. Wie man aber auch sehen kann, wird ein Sortkey sehr lang. Er braucht somit wesentlich mehr Platz als der String selber. Deshalb gibt es auch hier Komprimierungen, welchen den Sortkey wieder wesentlich reduzieren, damit das Vergleichen noch (Speicherplatz-) Effizient wird.Auch hier kann ich aber aus Platzgründen nicht vollständig auf den Algorithmus eingegangen werden. Eine genaue Erklärung gibt es wiederum im Unicode Technical Standard #10.
Trotzdem ein paar Links:
* Globalization Step-by-Step
* How do sort keys work?
* The jury will give this string no weightIn Windows kann z.B. mittels der Funktion
LCMapStringmit dem, FlagLCMAP_SORTKEYein Sortkey für jeden beliebigen String erzeugt werden. Das gleiche gibt es für Linux in der ICU-Lib.3.6 Beispiele mit Unicode
3.6.1 Gleiche Dateinamen unter Windows
Per Definition ist es unter Windows nicht möglich zwei Dateien mit dem gleichen Dateinamen im selben Verzeichnis anzulegen. Ein Versuch dies zu machen, wird scheitern. Mit dem Wissen von Unicode und dem Wissen, dass das Dateisystem eigentlich kein Unicode unterstützt, sondern die übergebenen (2-Byte langen) Zeichen einfach 1-zu-1 übernimmt, kann man jetzt Dateinamen erzeugen, die genau gleich angezeigt werden, aber unterschiedlich im Dateisystem gespeichert sind:
#include <windows.h> #include <tchar.h> int _tmain() { // File names with same names! wchar_t name1[] = {'\\', 'B', 0xE4, 0x0}; // \Bä wchar_t name2[] = {'\\', 'B', 0x61, 0x0308, 0x0}; // \Bä HANDLE h1 = CreateFileW(name1, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); HANDLE h2 = CreateFileW(name2, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); CloseHandle(h2); CloseHandle(h1); return 0; }Hiermit hat man jetzt zwei Dateien, die "Bä" heißen (was eigentlich nicht sein sollte). Hätte der NTFS-Treiber eine korrekte Implementierung von Unicode, so würde er erkennen, dass beide Strings genau gleich sind und dies somit nicht zulassen.
3.6.2 Beispiele von speziellen Unicode-Zeichen
Ein ganz besonderes Unicode-Zeichen ist z.B. das SOFT HYPEN (U+00AD). Das ist ein Bindestrich, welcher nur manchmal sichtbar ist. Im Folgenden habe ich einen Text erstellt, welcher so viel wie möglich dieses Zeichen enthält. Wenn man also den Browser ganz eng zusammenschiebt, so sieht man, dass manchmal aus dem "nichts" ein Bindestrich zur Silbentrennung auftaucht (zumindest beim IE6).
<html>
<head>
</head>
</body>
Es werde eine Feste zwischen den Wassern, die da scheide zwischen den Wassern.
Da machte Gott die Feste und schied das Wasser unter der Feste von dem Wasser über der Feste. Und es geschah so.
</body>
</html>(das ganze gibt es auch hier zum separaten Anschauen)
3.7 Einschränkungen von C/C++
C/C++ kennt für Unicode den Datentypwchar_t. Alle Zeichenorientierten Unicode-Varianten der CRT nehmen diesen Datentyp entgegen. Bei den MS-Compilern ist dieser Datentyp 16-Bit lang. Dies hat zur Folge, dass aktuell keine Unterstützung für Unicode-Codepoints > U+FFFF vorhanden ist, da hierfür 32-Bit (oder 2x16-Bit) notwendig wären. So kann man z.B. mitiswdigitdas Zeichen 'MATHEMATICAL MONOSPACE DIGIT FIVE' (U+1D7FB) nicht als Zahl erkennen. Hier wäre es notwendig, dass alle Unicode-Funktionen einen String entgegen nehmen würden und intern konsequent in UTF-8/16/32 kodiert würden. Bei einigen anderen Compilern istwchar_t32-Bit, womit eine vollständige Abbildung aller Unicode-Codepoints in einemwchar_tmöglich ist.3.8 Unterstützung von Unicode in .NET 2.0
.NET hat eine sehr vollständige Implementierung von Unicode. So werden auch die Codepoints > U+FFFF unterstützt. Strings werden intern als UTF-16 abgespeichert.
Mit dem folgenden Code kann man z.B. alle Unicode-Zeichen durchgehen und z.B. ermitteln, ob diese eine Zahl ist und den Wert dazu ausgeben.
using namespace System; int main() { for(int c=0; c<=0x10FFFF; c++) { if ((c >= 0x00d800) && (c <= 0x00dfff)) continue; // überspringe die Surrogates String ^s = Char::ConvertFromUtf32(c); if (Char::IsNumber(s, 0)) { Console::WriteLine("'0x{0:X}' hat den Zahlenwert {1}", c, Char::GetNumericValue(s, 0)); } } }4 Konvertierung zwischen unterschiedlichen Codepages
Möchte man Strings von einer Codepage in eine andere Codepage konvertieren, so ist der einfachste Weg, wenn man über Unicode geht.
Man konvertiert zuerst den Ausgangsstring nach Unicode (UTF-x Kodierung spielt dabei keine Rolle) und kodiert dann diesen Unicode-String in das Zielencoding. Unter Windows kann man hierzu
MultiByteToWideCharundWideCharToMultiByteverwenden. Für ein (schlechtes) Beispiel siehe Looking Up a User's Full Name.5 Anhang
5.1 Eingabe von Unicode-Zeichen
In Windows gibt es verschiedene Methoden Unicode-Zeichen einzugeben. Aus meiner Erfahrung gehen aber nicht alle Eingabemethoden in allen Programmen. Die Universalste ist die Verwendung eines Unicode-IME (Input Methode Editors). Eine kurze Beschreibung wie man dies aktiviert hat der i18n Guru von Microsoft hier aufgeführt.
5.2 Links
5.2.1 Unicode allgemein
* Unicode Home Page
* FileFormatInfo: Unicode
* Die Unicode-Datenbank
* Unicode's characters5.2.2 C/C++ Allgemein
* Standard C++ IOStreams and Locales
5.2.3 Linux und Unicode
* UTF-8 and Unicode FAQ for Unix/Linux
* Linux-Howtos: Making your programs Unicode aware
* Linux Unicode programming5.2.4 Unicode-Libraries für Linux
6 Nachwort
Die häufige Verwendung von Microsoft Produkten rührt daher, dass ich diese hauptsächlich verwende. Ich habe mich bemüht aus dem Linux-Lager Infos zu finden, mir konnte dies aber nicht so gelingen wie erhofft. Für sachdienliche Hinweise bin ich jederzeit offen!
-
~Ich habe die Listen mal noch in "echte" Listen umgewandelt, hoffe das ist in Ordnung.~
1 Kleiner historischer Abriss
Schon vor langer Zeit haben die Menschen das Bedürfnis gehabt, etwas aufzuschreiben. Damals hat man noch Schildkröten statt Papier verwendet, aber vom Prinzip hat sich bis heute nicht viel daran geändert.
Bis die Computer kamen... dann hatte man das Problem, dass die Schriftzeichen sich so schwer in den Bildschirm ritzen ließen. Dieses Problem hatte man übrigens nicht erst mit den Computern sondern auch schon früher, als man versucht hat, Nachrichten ohne Steintafeln/Papier zu übertragen (z.B. via Optische Telegraphie).
Es musste also eine Codierung für die Zeichen her. Upps, da wir gerade bei Zeichen sind: Das was umgangssprachlich als "Zeichen" verstanden wird, ist i.d.R. ein "Glyph".
Aber nun zurück zu den Computern und das Problem mit den Zeichen... Der Computer versteht (bis heute noch) nur Bits (also 0 und 1), also musste etwas erfunden werden, was sich mit 0 und 1 darstellen lässt. Einer der ersten Zeichensätze für solche Zwecke war der "Baudot-Code" (obwohl es zu dieser Zeit noch gar keinen Computer gab). Davon abgeleitet wurde dann der CCITT-2 Code zum Standard in der Telex Übertragung (welches heute noch in Deutschland existiert!).
Erst 1967 wurde dann der ASCII Standard definiert, welcher aus 7 Bit besteht und noch heute Gültigkeit hat und die Basis für die meisten Codierungen ist.
Mehr Infos zur Historie gibt es auch bei Heise.
2 Die Folgen von ASCII
Der ASCII-Zeichensatz hatte ein großes Problem: Er wurde von den Amerikanern definiert, deren Horizont kaum über den Teich reicht. Somit wurden nur Zeichen aufgenommen, die drüben bekannt waren. Nicht einmal Zeichen, die in Europa oft verwendet werden (z.B. ä, ö, ü, ß, á, à, usw.) wurden berücksichtigt.
Aus dieser Not heraus wurden diverse Codepages erfunden. Die meisten dieser Codepages (also Kodierungen, welche mehr als nur ASCII-Zeichen enthalten) wurden durch die ISO in der Norm ISO 8859 standardisiert. Diese Codepages bestehen aus 8 Bit und können somit 2^8 Zeichen (256) adressieren. Die meisten dieser Codepages verwenden in den ersten 128 Zeichen dieselben Zeichen wie im ASCII-Standard. Somit sind nur die letzten 128 Zeichen in einer Codepage unterschiedlich. Die ISO hat aber nur Zeichensätze aufgenommen, die im westlichen Umfeld gebräuchlich waren. Damit wurden auch hier keine asiatischen Zeichen kodiert, welches wiederum diverse länderspezifische Kodierungen hervorbrachte (z.B. Big5, GB2312 und Shift-JIS).Auch in Windows halten sich alle Codepages in den ersten 128 Bytes an den ASCII-Standard und nur die oberen 128 Bytes sind Codepage-spezifisch (naja, es gibt auch Ausnahmen: so hat z.B. die Windows Codepage 932 (Japanisch) oder 949 (Koreanisch) an der Position 0x5C nicht ein Backslash sondern ein YEN bzw. ein WON Zeichen; siehe auch: When is a backslash not a backslash?).
2.2 Kodierung von mehr als 256 Zeichen
Durch die Einschränkung auf 256 Zeichen (SBCS: Singlebyte Character Set; es wird nur ein Byte für ein Zeichen benötigt), welche aus den gebräuchlichen 8 Bit für ein Zeichen hervorgeht, haben alle Sprachen Probleme, welche mehr als 256 Zeichen verwenden. Um dieses Problem zu lösen, wurde das Multibyte Character Set erfunden.
Bei MBCS wird für ein Zeichen min. 1 Byte verwendet. Es gibt aber auch viele Zeichen, für die 2 und mehr Bytes verwendet werden (bei solchen Zeichen werden die ersten Bytes als "Lead-Byte" bezeichnet). Mit dieser Technik können beliebig viele Zeichen kodiert werden.
In der Praxis gibt es kaum MBCS-Zeichensätze. Die meisten Kodierungen verwenden nur DBCS (Doublebyte Character Set) welcher maximal 2 Byte zur Kodierung eines Zeichens verwenden (so z.B. auch alle unterstützten MBCS von Microsoft).
2.2 MBCS und die Auswirkungen auf die Programmierung
Das Handhaben von Zeichenketten war in C schon immer ein Problem. Neben den vielen Programmierfehlern bzgl. zu kleiner Puffer ist mit dem Aufkommen der MBCS noch ein weiteren Problem dazugekommen, welches sich viele Programmierer nicht bewusst sind: Ein Zeichen kann aus mehreren Bytes bestehen!
Vielen werden jetzt zwar denken: Was geht mich das an! Im Folgenden will ich versuchen darauf einzugehen (PS: Man kann das Problem natürlich auch ignorieren, nur wird man dann bestimmte Gebiete (z.B. Asien) von seinem Programm ausschließen).
2.2.1 Wie lang ist ein MBCS-String?
Hier scheiden sich schon die Geister: Was ist denn genau gemeint? Will der Fragende die Anzahl der Zeichen (Glyphs?) wissen oder die Anzahl der Bytes? Will man z.B. in einer Textverarbeitung die Anzahl der Zeichen zur Information anzeigen (wie es ja einige machen), so will man sicherlich die Anzahl der "Glyphs" wissen. Bei einem MBCS-Zeichensatz kann dies aber weniger sein, als der String in Bytes lang ist. Somit ist ein einfaches
strlennicht mehr ausreichend. Man muss also immer noch etwas über den tatsächlich verwendeten Zeichensatz wissen um die Anzahl der "Glyphs" zu ermitteln. Hier taucht gleich das zweite Problem auf: Bei den MBCS sind nicht alle Byte-Folgen gültige Zeichen! So ist z.B. bei Shift-JIS die Zeichenfolge 0xE6 0x40 ein gültiges Zeichen wo hingegen 0xE6 0x7F kein definiertes Zeichen ist.Leider gibt es für MBCS-Unterstützung keine (zumindest mir bekannte) Normierung in der C/C++-Welt. Microsoft hat hierfür eine eigene Erweiterung zur Verfügung gestellt, welches hier unterstützt (
_mbslen(ohne Prüfung auf Gültigkeit des Strings) und_mbstrlen(mir Prüfung auf Gültigkeit des Strings)). In Linux (g++) sind mir keine Funktionen bekannt, welche die Anzahl der "Glyphs" für verschiedene Codepages zurückliefern (für UTF8 gibt es wohlg_utf8_strlen).2.2.2 Suchen von Zeichen in Strings
Um z.B. ein bestimmtes Zeichen in einem String zu suchen, nimmt man ja i.d.R.
strchr. Wenn z.B. nach einem Unterstrich (_) suchen will, so ist dies bei einem SBCS ja trivial. Bei einem MBCS wird es hingegen schon sehr komplex, da auch beachtet werden muss, ob das aktuelle Zeichen ein "Lead-Byte" ist und somit das nächste als kombiniertes Zeichen betrachtet werden muss. Ein einfaches Suchen mittelsstrchrist somit nicht mehr möglich. In der Windows Codepage 936 (Simplified Chinese GBK), ist das Zeichen U+7BF2 (Besenstiel) als "0xBA 0x5F" kodiert. Dies würde bei einer simplen Suche nach "_" (0x5F) einen Treffer liefern, was offensichtlich falsch ist.Die Probleme mit MBCS gehen noch viel weiter. So ist es z.B. für einen Benutzer einer Textverarbeitung etwas ungewöhnlich, wenn das Programm MBCS verwendet (vielleicht ohne dass der Programmierer dies weiß), wenn er mit dem Cursor (Caret) durch seinen Text geht (z.B. Pfeil nach rechts) und er für ein (MBCS) Zeichen zuerst "im" Zeichen landet und erst beim zweiten mal hinter dem Zeichen...
3 Die Lösung aller Probleme: UNICODE
(oder: Wie man noch mehr Probleme schafft)Um das Problem zu lösen, dass immer mehr unterschiedliche Codepages aus dem Kraut schießen, wurde (erst) 1991 eine einheitliche Kodierung definiert, welche alle Sprachen / Zeichen aufnehmen sollte (History of Unicode 1.0). Dabei wurde schon der erste Fehler gemacht und man ging davon aus, dass 2 Byte (65536) Zeichen vollkommen ausreichen würden um alle Zeichen in der Welt abzudecken (Zitat: "16-bits wide because this provides a sufficient number of codes (65,536) to represent electronic text characters anticipated for the foreseeable future"). Naja, die "foreseeable future" war bei vielen doch wohl sehr beschränkt ;).
Zumindest wurde dem Projekt etwas Erfolg vorhergesagt, da sich alle großen Firmen (Apple, GO, IBM, Metaphor, Microsoft, NeXT, Novell, The Research Libraries Group and Sun Microsystems) beteiligten.
Die Probleme mit dem zu kleinen Adressraum wurden dann auch schon in der Version 2 behoben, indem zusätzliche 16 weitere gleich große Bereiche definiert wurden. Somit gehen die Codepoints von U+00000 bis U+10FFFF (und belegen bei 1-zu-1 Kodierung jetzt 32 Bit). Wir dürfen gespannt sein, wie lange dieser Namenraum ausreichen wird.
Die aktuelle Unicode-Version 5.0.0 enthält ungefähr 99.000 Zeichen.
3.1 Kodierungen von UNICODE
Für Unicode gibt es unterschiedliche Kodierungen. Alle beziehen sich aber auf die Codepoints (ein bestimmter Wert in dem Unicode-Coderaum; dieser Wert wird i.d.R. mittels U+xxxx oder U+10xxxx geschrieben), welche im Unicode-Standard definiert sind.
Es gibt die folgenden Kodierungen von Unicode:
- UTF-32 (BE oder LE)
- UTF-16 (BE oder LE)
- UTF-8
- UTF-7
- UTF-EBCDIC
- PunycodeDie gebräuchlichste Kodierung ist UTF-8. Aus Sicht der Komplexität von Unicode spielt es keine große Rolle, welche der UTF-x Kodierungen man verwendet (aber dazu später).
3.2 BOM
Beim Lesen/Schreiben von Dateien existiert immer das Problem, dass man wissen muss, in welcher Kodierung diese Datei gelesen/gespeichert werden soll. Das Unicode-Konsortium hat hierfür einen BOM definiert, welcher ganz am Anfang der Datei steht und die Kodierung (für Unicode) definiert. Mit diesem BOM können aber nur die Unicode-Kodierungen unterschieden werden. Es ist nichts allgemeingültiges, womit man auch andere Codepages unterscheiden könnte.
Wenn kein BOM vorhanden ist, so kann nicht eindeutig ermittelt werden, um welches Encoding es sich bei einer (Text-)Datei handelt. Es ist einzig eine "statistische Analyse" des Textes möglich, wie es z.B. Notepad mittels der WinAPI-Funktion
IsTextUnicodemacht.3.3 Blocks
Unicode definiert zusammengehörige Zeichen in einem Block. Ein Block ist z.B. der ASCII-Block (Basic-Latin U+0000 bis U+007F). Um für kommende Zeichen genug Platz zu lassen, entstehen natürlich in einigen Blöcken Lücken die freigelassen wurden. Daraus wird auch ersichtlich warum erst ca. 9% aller Codepoints vergeben sind.
3.4 Kategorien
Jedem Codepoint ist (min.) eine Kategorie zugeordnet. Es gibt insgesamt 33 Kategorien. Eine Kategorie ist z.B. "Letter, Lowercase" (Kleinbuchstabe). In dieser Kategorie sind z.B. 1634 Zeichen vorhanden.
3.5 Besonderheiten von Unicode
Unicode versucht alle Probleme, die man mit Sprachen und deren dazugehörigen Zeichen hat, zu lösen. Aus diesem Grunde ist auch der Standard schon fast unüberschaubar geworden und es gibt wohl nur wenige Menschen, die alle Bereiche vollständig verstanden haben. Im Folgenden will ich einzelne dieser Besonderheiten vorstellen.
3.5.1 Zahlen
Viele Programme müssen mit Zahlen arbeiten. Aber eigentlich fast alle beschränken sich dabei auf die uns bekannten Zahlen 0-9. Im Unicode-Standard sind aber über 836 Codepoints als Zahlen (Numbers) definiert! So gibt es z.B. das Zeichen U+216B (ROMAN NUMERAL TWELVE), welches als Zahl mit dem Wert 12 definiert ist. 290 von diesen Zahlen sind als Decimal Digits definiert und können somit 1-zu-1 mit dem uns bekannten Stellenwertsystem (Digits 0-9) ausgetauscht werden. 210 Zahlen sind so genannte Buchstaben-Zahlen, also Zahlen, welche sich nicht direkt mit einem "Digit" (also Zahlen, die durch ein Stellenwertsystem zwischen 0 und 9 verwenden lassen) darstellen lassen. Die dritte Kategorie von Zahlen sind Sonstige Zahlen. Diese beinhalten z.B. auch Brüche (z.B. Ein viertel (1/4)) oder die Zahl "eins weniger als die vorherige".
Leider existiert auch hier in der C/C++-Welt keine mir bekannte Bibliothek, welche diese Eigenheit von Unicode vollständig unterstützt. So "kennt" z.B. die Funktion
iswdigitje nach verwendetem OS bestimmte Zahlen nicht...Mein GCC 3.3.4 unter Linux v2.6.8 kennt z.B. die Zahl ARABIC-INDIC DIGIT FIVE nicht. Dagegen erkennt es das gleiche Programm unter Windows XP (die MS-CRT verwendet intern
GetStringTypeW, welches viele Zeichen kennt).#include <stdio.h> #include <ctype.h> int main() { if (iswdigit(0x0035) == 0) printf("'DIGIT FIVE' ist KEINE Zahl"); if (iswdigit(0x0665) == 0) printf("'ARABIC-INDIC DIGIT FIVE' ist KEINE Zahl"); return 0; }Im .NET-Framework 2.0 gibt es in der
Char-Klasse viele für Unicode notwendige Hilfsfunktionen. So kann man z.B. mittelsusing namespace System; int main() { Console::WriteLine("'DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0035)); Console::WriteLine("'ARABIC-INDIC DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0665)); Console::WriteLine("'ROMAN NUMERAL TWELVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x216B)); }die Zahlenwerte dieser Unicode-Codepoints ermitteln.
Am Ende des Artikels findet sich noch ein Beispiel, welches alle (in .NET 2.0) bekannten Zahlen mit den dazugehörigen Werten ausgibt.
3.5.2 Combining-Characters
Die uns geläufigen Zeichen wie ä, ö, ü usw. sind ja etwas besondere Zeichen. Das 'ä' ist ja eigentlich ein 'a' mit einem diakritischem Zeichen. Und genau dieser Sachverhalt kann auch in Unicode abgebildet werden. Das Zeichen 'ä' kann entweder als ein verbundenes Zeichen (precomposed character) geschrieben werden (U+00E4) oder als Kombination aus einem Basiszeichen (a) und einem Diaresis (combining-character): U+0061 U+0308.
Ein Combining Character ist somit ein Zeichen, was immer mit einem Basiszeichen zusammen dargestellt wird. Es ist auch möglich, dass ein Basiszeichen mehrere Combining-Characters enthält. So ist im folgenden Bild das Zeichen U+1EAB als eine Kombination aus einem Basiszeichen und zwei Combining-Characters dargestellt:
Diese Tatsache ist vielen nicht bekannt. Man sollte sich dieses aber wirklich verinnerlichen! Daraus ergeben sich erhebliche Konsequenzen. So ist z.B. das Vergleichen von Strings nicht mehr so trivial und muss ganz anders ablaufen. Auch hat es Auswirkung auf die Eingabe von Zeichen und das "Durchgehen" des Textes mittels der Cursor-Tasten. Wurde z.B. das obige Zeichen U+1EAB als Combining-Character eingeben, welches aus 3 Codepoints besteht, so wäre es für den Benutzer einer Textverarbeitung sehr verwunderlich, wenn man drei mal die "Pfeil nach rechts" Taste drücken müssen, um hinter das Zeichen zu kommen.
Hier schließt sich auch wieder der Kreis zu den MBCS-Zeichensätzen. Hier hat man nämlich genau dasselbe Problem, dass ein Codepoint nicht unbedingt ein Zeichen (Glyph) sein muss. UTF8/16 kann man ja auch als MBCS ansehen und somit wird auch deutlich, warum es eigentlich egal ist, wenn man nicht UTF-32 zur Speicherung der Zeichen verwendet: Ein Aufwand bei der Darstellung und dem "Durchgehen" von Zeichen hat man so oder so. Deshalb kann es nicht als Nachteil angesehen werden, wenn man intern kein UTF-32 verwendet.
3.5.3 Compatibility characters
"Compatibility characters" sind Codepoints, welche nur aufgenommen wurden um eine bessere Kompatibilität mit schon bestehenden Codepages herzustellen und somit eine einfache Konvertierung von diesen Codepages nach Unicode und wieder zurück zu ermöglichen. Man unterschiedet dabei zwischen Codepoints welche sich 1-zu-1 auf ein anderen Codepoint mappen lassen (so z.B. U+F900, welches sich direkt nach U+8C48 mappen lässt) und solchen Zeichen, die eigentlich aus mehreren Zeichen bestehen (Composite Character) aber auch mit mehreren einzelnen Zeichen angezeigt werden können (Decomposed Character). Ein Beispiel hierfür ist "bar", welches natürlich auch aus den Einzelbuchstaben bar zusammengesetzt werden kann.
3.5.4 Normalization
Aus den obigen Ausführungen kann man erkennen, dass es für einen Satz fast beliebig viele Darstellungsmöglichkeiten gibt (z.B. Combining/Compatibility-Characters). Um dieses Wirrwarr etwas zu entzerren hat man sog. "Normalisierungs-Formen" eingeführt. Jeder String kann in solch eine Form überführt werden (ist auch Voraussetzung für den Textvergleich und die Sortierung; wobei die Normalisierung dabei nur ein Schritt ist!). Es gibt die folgenden Normalisierungen:
- Normalization Form D (NFD, Canonical Decomposition):
Spaltet zusammengesetzte Zeichen in die einzelnen Bestandteile auf (wenn möglich). So wird z.B. das Zeichen 'Ä' in die Darstellung als U+0041 U+0308 überführt. - Normalization Form C (NFC, Canonical Decomposition, followed by Canonical Composition):
Ist das Gegenteil von NFD: Hier werden zusammengesetzte Zeichen bevorzugt (wenn möglich). So wird anstelle von 'LATIN CAPITAL LETTER A', 'COMBINING DIAERESIS' das Zeichen 'LATIN CAPITAL LETTER A WITH DIAERESIS' verwendet.
Auch werden veraltete, kombinierte Zeichen durch neue ersetzt, z.B. 'ANGSTROM SIGN' wird durch 'LATIN CAPITAL LETTER A WITH RING ABOVE' ersetzt. - Normalization Form KD (NFKD, Compatibility Decomposition):
Ist wie "Form D", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht. - Normalization Form KC (NFKC, Compatibility Decomposition, followed by Canonical Composition):
Ist wie "Form C", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht.
Bei allen diesen Normalisierungen ist zu beachten, dass es Fälle gibt in denen ein "Round-Trip" zur ursprünglichen Kodierung nicht mehr möglich ist. Auch kann sich die Bedeutung verändern (wenn z.B. das einzelne Zeichen bar durch die drei Einzelbuchstaben "b a r" ersetzt wird.
In der Windows-API kann eine Normalisierung in diese Formen mittels der Funktion
FoldStringdurchgeführt werden.Im .NET-Framework 2.0 hat die
String-Klasse eine Methode, um einen String zu normalisieren bzw. abzufragen ob der String normalisiert ist (siehe dazu auch meine Anfrage an Michael Kaplan von Microsoft).
Auch gibt es in dem NamespaceSystem::Globalizationsehr viele Klassen, die sich mit Unicode und sonstigen Dingen der Globalisierung beschäftigen. Ebenso in dem NamespaceSystem::Text, welche z.B. auch Klassen zur Konvertierung von Strings in diverse Zeichensätze anbietet.Linux: Es gibt wohl diverse LIBs, die das können (siehe Links weiter unten).
3.5.5 BiDi-Classes
Der Unicode-Standard definiert (hauptsächlich) wie die Strings im (Haupt-)Speicher kodiert werden. Dies wird auch als "logische Reihenfolge" bezeichnet. Diese Reihenfolge muss aber nicht unbedingt mit der Reihenfolge, wie die Texte dargestellt werden, identisch sein! In unsere Hemisphären kennen wir eigentlich nur die Links-Nach-Rechts (LTR) Schriftarten. Es gibt aber auch Sprachen, wo die Schreibweise von Rechts-Nach-Links (RTL) geht. Da Unicode alle Zeichen und Sprachen abdeckt (besser gesagt: "fast alle", da sich das Konsortium bis heute weigert "Klingonisch" aufzunehmen; aber die beiden Sprachen (Tengwar und Cirth) von J. R. R. Tolkien will man zukünftig aufnehmen), wurden natürlich auch solche Dinge berücksichtigt. Wenn nun RTL- und LTR-Texte gemischt werden, so redet man von bi-directional Text. Um auch hier eine einheitliche Vorgehensweise zu erlauben, wurden dazu für jedes Zeichen bestimmte Properties aufgenommen (also wie das Zeichen bzgl. RTL/LTR dargestellt werden soll) und es wurde eine eigene Standard-Beschreibung definiert.
Für jedes Zeichen ist somit genau definiert, wie es sich in einem BiDi Umfeld verhalten soll. Dieses Verhalten kann mit expliziten Angaben von "Schreibrichtungen" verändert werden.
Das "durchgehen" solch eines Satzes von links nach rechts ist für uns etwas ungewohnt, da die Position des Carets ungewöhnlich "springt":
.In dem obigen Beispiel werden die folgenden Codepoints verwendet und diese auch in dieser Reihenfolge in der Datei/Speicher abgelegt:
U+0044 U+0069 U+0065 U+0020 U+0648 U+064E U+0631 U+0652 U+062F U+064E U+0629 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002E
Die Reihenfolge auf dem Bildschirm ist aber eine etwas andere:
U+0044 U+0069 U+0065 U+0020 U+0629 U+064E U+062F U+0652 U+0631 U+064E U+0648 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002EHierzu noch eine kleine Quizfrage: Wenn das Caret mitten in einem RTL Text steht und man "Backspace" drückt, in welche Richtung bewegt sich das Caret und welches Zeichen wird gelöscht?
Den genauen Algorithmus zum Erzeugen eines Sortkeys zu beschreiben würde den Rahmen dieses Dokumentes bei weitem Sprengen. Für detaillierte Infos, siehe den #TR9-Standard.
(PS: Es ist nicht so schlimm wenn man es nicht ganz verstanden hat, Microsoft hat es auch noch nicht
)3.5.6 Textvergleich und Sortierung
Ein Textvergleich von Unicode-Strings ist eines der komplexesten, was es im Unicode Standard gibt (noch komplexer als BiDi!). Der (aktuelle) Textvergleich wird durch den "Unicode Technical Standard #10 (Unicode Collation Algorithm)" definiert. Ausgedruckt ergibt dies bei mir ca. 78 DIN A4 Seiten.
Ganz grob kann man sagen: Jedem Codepoint (Zeichen) ist ein (oder mehrere) Gewichtungsfaktor(en) zugeordnet. Anhand dieser Gewichte und anderen Kriterien (z.B. Ignorierung der Groß- und Kleinschreibung) wird ein "Sort Key" zusammengestellt, mit dem dann ein String verglichen werden kann. Diese Gewichtungsfaktoren sind entweder explizit für ein Zeichen definiert oder er kann aus der Position und sonstigen Eigenschaften berechnet werden.
Ein kleines Beispiel: Es soll der Sort-Key für den String "Öde" erstellt werden.
Hierzu muss man zuerst den String in die Normalform NFD bringen. Dies ergibt dann
U+004F U+0308 U+0064 U+0065.
Nun muss in der Tabelle für die Weights nachgeschaut werden und daraus ergibt sich das folgende "Collection Element Array":(113B.0020.0008), (0000.0047.0002), (1010.0020.0002), (1029.0020.0002)Nun hat man die Gewichte für alle 4 Zeichen. Dabei ist der erste Eintrag das Primäre Gewicht, der zweite das Sekundäre Gewicht und das dritte das Tertiäre Gewicht.
Aus diesem "Collection Element Array" wird nun der Sortkey gebildet, indem man die primäre, sekundäre und tertiäre Gewichte in der richtigen Reihenfolge anordnet (und man lässt die Zahlen weg, welche 0 sind). Daraus ergibt sich dann der Sortkey:113B, 1010, 1029 | 0020, 0047, 0020, 0020 | 0008, 0002, 0002, 0002Diese Zahlen kann man nun mit anderen Sortkeys mit einem "normalen"
memcmpvergleichen. Wie man aber auch sehen kann, wird ein Sortkey sehr lang. Er braucht somit wesentlich mehr Platz als der String selbst. Deshalb gibt es auch hier Komprimierungen, welche den Sortkey wieder wesentlich reduzieren, damit das Vergleichen noch (Speicherplatz-)effizient wird.Auch hier kann ich aber aus Platzgründen nicht vollständig auf den Algorithmus eingehen. Eine genaue Erklärung gibt es wiederum im Unicode Technical Standard #10.
Trotzdem ein paar Links:
In Windows kann z.B. mittels der Funktion
LCMapStringmit dem FlagLCMAP_SORTKEYein Sortkey für jeden beliebigen String erzeugt werden. Das gleiche gibt es für Linux in der ICU-Lib.3.6 Beispiele mit Unicode
3.6.1 Gleiche Dateinamen unter Windows
Per Definition ist es unter Windows nicht möglich, zwei Dateien mit dem gleichen Dateinamen im selben Verzeichnis anzulegen. Ein Versuch dies zu machen, wird scheitern. Mit dem Wissen von Unicode und dem Wissen, dass das Dateisystem eigentlich kein Unicode unterstützt, sondern die übergebenen (2-Byte langen) Zeichen einfach 1-zu-1 übernimmt, kann man jetzt Dateinamen erzeugen, die genau gleich angezeigt werden, aber unterschiedlich im Dateisystem gespeichert sind:
#include <windows.h> #include <tchar.h> int _tmain() { // File names with same names! wchar_t name1[] = {'\\', 'B', 0xE4, 0x0}; // \Bä wchar_t name2[] = {'\\', 'B', 0x61, 0x0308, 0x0}; // \Bä HANDLE h1 = CreateFileW(name1, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); HANDLE h2 = CreateFileW(name2, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); CloseHandle(h2); CloseHandle(h1); return 0; }Hiermit hat man jetzt zwei Dateien, die "Bä" heißen (was eigentlich nicht sein sollte). Hätte der NTFS-Treiber eine korrekte Implementierung von Unicode, so würde er erkennen, dass beide Strings genau gleich sind und dies somit nicht zulassen.
3.6.2 Beispiele von speziellen Unicode-Zeichen
Ein ganz besonderes Unicode-Zeichen ist z.B. das SOFT HYPEN (U+00AD). Das ist ein Bindestrich, welcher nur manchmal sichtbar ist. Im Folgenden habe ich einen Text erstellt, welcher so viel wie möglich dieses Zeichen enthält. Wenn man also den Browser ganz eng zusammenschiebt, so sieht man, dass manchmal aus dem "nichts" ein Bindestrich zur Silbentrennung auftaucht (zumindest beim IE6).
<html>
<head>
</head>
</body>
Es werde eine Feste zwischen den Wassern, die da scheide zwischen den Wassern.
Da machte Gott die Feste und schied das Wasser unter der Feste von dem Wasser über der Feste. Und es geschah so.
</body>
</html>(das ganze gibt es auch hier zum separaten Anschauen)
3.7 Einschränkungen von C/C++
C/C++ kennt für Unicode den Datentyp
wchar_t. Alle zeichenorientierten Unicode-Varianten der CRT nehmen diesen Datentyp entgegen. Bei den MS-Compilern ist dieser Datentyp 16 Bit lang. Dies hat zur Folge, dass aktuell keine Unterstützung für Unicode-Codepoints > U+FFFF vorhanden ist, da hierfür 32 Bit (oder 2x16 Bit) notwendig wären. So kann man z.B. mitiswdigitdas Zeichen 'MATHEMATICAL MONOSPACE DIGIT FIVE' (U+1D7FB) nicht als Zahl erkennen. Hier wäre es notwendig, dass alle Unicode-Funktionen einen String entgegen nehmen würden und intern konsequent in UTF-8/16/32 kodiert würden. Bei einigen anderen Compilern istwchar_t32-Bit, womit eine vollständige Abbildung aller Unicode-Codepoints in einemwchar_tmöglich ist.3.8 Unterstützung von Unicode in .NET 2.0
.NET hat eine sehr vollständige Implementierung von Unicode. So werden auch die Codepoints > U+FFFF unterstützt. Strings werden intern als UTF-16 abgespeichert.
Mit dem folgenden Code kann man z.B. alle Unicode-Zeichen durchgehen und ermitteln, ob dieses eine Zahl ist und den Wert dazu ausgeben.
using namespace System; int main() { for(int c=0; c<=0x10FFFF; c++) { if ((c >= 0x00d800) && (c <= 0x00dfff)) continue; // überspringe die Surrogates String ^s = Char::ConvertFromUtf32(c); if (Char::IsNumber(s, 0)) { Console::WriteLine("'0x{0:X}' hat den Zahlenwert {1}", c, Char::GetNumericValue(s, 0)); } } }4 Konvertierung zwischen unterschiedlichen Codepages
Möchte man Strings von einer Codepage in eine andere Codepage konvertieren, so ist der einfachste Weg, wenn man über Unicode geht.
Man konvertiert zuerst den Ausgangsstring nach Unicode (UTF-x Kodierung spielt dabei keine Rolle) und kodiert dann diesen Unicode-String in das Zielencoding. Unter Windows kann man hierzu
MultiByteToWideCharundWideCharToMultiByteverwenden. Für ein (schlechtes) Beispiel siehe Looking Up a User's Full Name.5 Anhang
5.1 Eingabe von Unicode-Zeichen
In Windows gibt es verschiedene Methoden Unicode-Zeichen einzugeben. Aus meiner Erfahrung gehen aber nicht alle Eingabemethoden in allen Programmen. Die universalste ist die Verwendung eines Unicode-IME (Input Method Editors). Eine kurze Beschreibung wie man dies aktiviert, hat der i18n Guru von Microsoft hier aufgeführt.
5.2 Links
5.2.1 Unicode allgemein
5.2.2 C/C++ Allgemein
5.2.3 Linux und Unicode
- UTF-8 and Unicode FAQ for Unix/Linux
- Linux-Howtos: Making your programs Unicode aware
- Linux Unicode programming
5.2.4 Unicode-Libraries für Linux
6 Nachwort
Die häufige Verwendung von Microsoft-Produkten rührt daher, dass ich diese hauptsächlich verwende. Ich habe mich bemüht aus dem Linux-Lager Infos zu finden, mir konnte dies aber nicht so gelingen wie erhofft. Für sachdienliche Hinweise bin ich jederzeit offen!
- Normalization Form D (NFD, Canonical Decomposition):
-
Danke! Mich hat es schon immer gewundert warum das so komische "*" sind... lässt sich eigentlich der etwas grosse Abstand irgendwie minimieren? Die Listen haben wohl noch ein paar Nebeneffekte...
-
Du meinst den vertikalen Abstand? Ich hab mal ein bisschen rumgespielt und meinen Beitrag editiert, jetzt ist es denke ich besser :).
-
1 Kleiner historischer Abriss
Schon vor langer Zeit haben die Menschen das Bedürfnis gehabt etwas aufzuschreiben. Damals hat man noch Schildkröten statt Papier verwendet, aber vom Prinzip hat sich bis heute nicht viel daran geändert.
Bis die Computer kamen... dann hatte man das Problem, dass die Schriftzeichen sich so schwer in den Bildschirm ritzen ließen. Dieses Problem hatte man übrigens nicht erst mit den Computern sondern auch schon früher, als man versucht hat Nachrichten ohne Steintafeln/Papier zu übertragen (z.B. via Optische-Telegraphie).
Es musste also eine Codierung für die Zeichen her. Upps, da wir gerade bei Zeichen sind: Das was umgangssprachlich als "Zeichen" verstanden wird, ist i.d.R. ein "Glyph".
Aber nun zurück zu den Computern und das Problem mit den Zeichen... Der Computer versteht (bis heute noch) nur Bits (also 0 und 1), also musste etwas erfunden werden, was sich mit 0 und 1 darstellen lässt. Einer der ersten Zeichensätze für solche Zwecke war der "Baudot-Code" (obwohl es zu dieser Zeit noch gar keinen Computer gab). Davon abgeleitet wurde dann der CCITT-2 Code zum Standard in der Telex Übertragung (welches heute noch in Deutschland existiert!).
Erst 1967 wurde dann der ASCII-Standard definiert, welcher aus 7-Bit besteht und noch heute Gültigkeit hat und die Basis für die meisten Codierungen ist.
Mehr Infos zur Historie gibt es auch bei Heise.
2 Die Folgen von ASCII
Der ASCII-Zeichensatz hatte ein großes Problem: Er wurde von den Amerikanern definiert, deren Horizont kaum über den Teich reicht. Somit wurden nur Zeichen aufgenommen, die drüben bekannt waren. Nicht einmal Zeichen die in Europa oft verwendet werden (z.B. ä, ö, ü, ß, á, à, usw.) wurden berücksichtigt.
Aus dieser Not heraus wurden diverse Codepages erfunden. Die meisten dieser Codepages (also Kodierungen, welche mehr als nur ASCII-Zeichen enthalten) wurden durch die ISO in der Norm ISO 8859 standardisiert. Diese Codepages bestehen aus 8-Bit und können somit 2^8 Zeichen (256) adressieren. Die meisten dieser Codepages verwenden in den ersten 128 Zeichen dieselben Zeichen wie im ASCII-Standard. Somit sind nur die letzten 128 Zeichen in einer Codepage unterschiedlich. Die ISO hat aber nur Zeichensätze aufgenommen, die im westlichen Umfeld gebräuchlich waren. Damit wurden auch hier keine asiatischen Zeichen kodiert, welches wiederum diverse länderspezifische Kodierungen hervorbrachte (z.B. Big5, GB2312 und Shift-JIS).Auch in Windows halten sich alle Codepages in den ersten 128 Bytes an den ASCII-Standard und nur die oberen 128 Bytes sind Codepage-Spezifisch (naja, es gibt auch Ausnahmen: so hat z.B. die Windows Codepage 932 (Japanisch) oder 949 (Koreanisch) an der Position 0x5C nicht ein Backslash sondern ein YEN bzw. ein WON Zeichen; siehe auch: When is a backslash not a backslash?).
2.2 Kodierung von mehr als 256 Zeichen
Durch die Einschränkung auf 256 Zeichen (SBCS: Singlebyte Character Set; es wird nur ein Byte für ein Zeichen benötigt), welche aus den gebräuchlichen 8-Bit für ein Zeichen hervorgeht, haben alle Sprachen Probleme, welche mehr als 256 Zeichen verwenden. Um dieses Problem zu lösen wurde das Multibyte Character Set erfunden.
Bei MBCS wird für ein Zeichen min. 1 Byte verwendet. Es gibt aber auch viele Zeichen, für die 2 und mehr Bytes verwendet werden (bei solchen Zeichen werden die ersten Bytes als "Lead-Byte" bezeichnet). Mit dieser Technik können beliebig viele Zeichen kodiert werden.
In der Praxis gibt es kaum MBCS-Zeichensätze. Die meisten Kodierungen verwenden nur DBCS (Doublebyte Character Set) welcher maximal 2 Byte zur Kodierung eines Zeichens verwenden (so z.B. auch alle unterstützten MBCS von Microsoft).
2.2 MBCS und die Auswirkungen auf die Programmierung
Das Handhaben von Zeichenketten war in C schon immer ein Problem. Neben den vielen Programmierfehlern bzgl. zu kleiner Puffer ist mit dem Aufkommen der MBCS noch ein weiteren Problem dazugekommen, welches sich viele Programmierer nicht bewusst sind: Ein Zeichen kann aus mehreren Bytes bestehen!
Vielen werden jetzt zwar denken: Was geht mich das an! Im Folgenden will ich versuchen darauf einzugehen (PS: Man kann das Problem natürlich auch ignorieren, nur wird man dann bestimmte Gebiete (z.B. Asien) von seinem Programm ausschließen).
2.2.1 Wie lang ist ein MBCS-String?
Hier scheiden sich schon die Geister: Was ist denn genau gemeint? Will der Fragende die Anzahl der Zeichen (Glyphs?) wissen oder die Anzahl der Bytes? Will man z.B. in einer Textverarbeitung die Anzahl der Zeichen zur Information anzeigen (wie es ja einige machen), so will man sicherlich die Anzahl der "Glyphs" wissen. Bei einem MBCS-Zeichensatz kann dies aber weniger sein, als der String in Bytes lang ist. Somit ist ein einfaches
strlennicht mehr ausreichend. Man muss also immer noch etwas über den tatsächlich verwendeten Zeichensatz wissen um die Anzahl der "Glyphs" zu ermitteln. Hier taucht gleich das zweite Problem auf: Bei den MBCS sind nicht alle Byte-Folgen gültige Zeichen! So ist z.B. bei Shift-JIS die Zeichenfolge 0xE6 0x40 ein gültiges Zeichen wo hingegen 0xE6 0x7F kein definiertes Zeichen ist.Leider gibt es für MBCS-Unterstützung keine (zumindest mir bekannte) Normierung in der C/C++-Welt. Microsoft hat hierfür eine eigene Erweiterung zur Verfügung gestellt, welches hier unterstützt (
_mbslen(ohne Prüfung auf Gültigkeit des Strings) und_mbstrlen(mir Prüfung auf Gültigkeit des Strings)). In Linux (g++) sind mir keine Funktionen bekannt, welche die Anzahl der "Glyphs" für verschiedene Codepages zurückliefern (für UTF8 gibt es wohlg_utf8_strlen).2.2.2 Suchen von Zeichen in Strings
Um z.B. ein bestimmtes Zeichen in einem String zu suchen, nimmt man ja i.d.R.
strchr. Wenn z.B. nach einem Unterstrich (_) suchen will, so ist dies bei einem SBCS ja trivial. Bei einem MBCS wird es hingegen schon sehr komplex, da auch beachtet werden muss, ob das aktuelle Zeichen eine "Lead-Byte" ist und somit das nächste als kombiniertes Zeichen betrachtet werden muss. Ein einfaches Suchen mittelsstrchrist somit nicht mehr möglich. In der Windows Codepage 936 (Simplified Chinese GBK), ist das Zeichen U+7BF2 (Besenstiel) als "0xBA 0x5F" kodiert. Dies würde bei einer simplen Suche nach "_" (0x5F) einen Treffer liefern, was offensichtlich falsch ist.Die Probleme mit MBCS gehen noch viel weiter. So ist es z.B. für einen Benutzer einer Textverarbeitung etwas ungewöhnlich, wenn das Programm MBCS verwendet (vielleicht ohne dass der Programmierer dies weiß), wenn er mit dem Cursor (Caret) durch seinen Text geht (z.B. Pfeil nach rechts) und er für ein (MBCS) Zeichen zuerst "im" Zeichen landet und erst beim zweiten mal hinter dem Zeichen...
3 Die Lösung aller Probleme: UNICODE
(oder: Wie man noch mehr Probleme schafft)Um das Problem zu lösen, dass immer mehr unterschiedliche Codepages aus dem Kraut schießen, wurde (erst) 1991 eine einheitliche Kodierung definiert, welche alle Sprachen / Zeichen aufnehmen sollte (History of Unicode 1.0). Dabei wurde schon der erste Fehler gemacht und man ging davon aus, dass 2 Byte (65536) Zeichen vollkommen ausreichen würden um alle Zeichen in der Welt abzudecken (Zitat: "16-bits wide because this provides a sufficient number of codes (65,536) to represent electronic text characters anticipated for the foreseeable future"). Naja, die "foreseeable future" war bei vielen doch wohl sehr beschränkt ;).
Zumindest wurde dem Projekt etwas Erfolg vorhergesagt, da sich alle großen Firmen (Apple, GO, IBM, Metaphor, Microsoft, NeXT, Novell, The Research Libraries Group and Sun Microsystems) beteiligten.
Die Probleme mit dem zu kleinen Adressraum wurden dann auch schon in der Version 2 behoben, indem zusätzliche 16 weitere gleich große Bereiche definiert wurden. Somit gehen die Codepoints von U+00000 bis U+10FFFF (und belegen bei 1-zu-1 Kodierung jetzt 32-Bit). Wir dürfen gespannt sein, wie lange dieser Namenraum ausreichen wird.
Die aktuelle Unicode-Version 5.0.0 enthält ungefähr 99.000 Zeichen.
3.1 Kodierungen von UNICODE
Für Unicode gibt es unterschiedliche Kodierungen. Alle beziehen sich aber auf die Codepoints (ein bestimmter Wert in dem Unicode-Coderaum; dieser Wert wird i.d.R. mittels U+xxxx oder U+10xxxx geschrieben), welche im Unicode-Standard definiert sind.
Es gibt die folgenden Kodierungen von Unicode:
- UTF-32 (BE oder LE)
- UTF-16 (BE oder LE)
- UTF-8
- UTF-7
- UTF-EBCDIC
- PunycodeDie gebräuchlichste Kodierung ist UTF-8. Aus Sicht der Komplexität von Unicode spielt es keine große Rolle, welche der UTF-x Kodierungen man verwendet (aber dazu später).
3.2 BOM
Beim Lesen/Schreiben von Dateien existiert immer das Problem, dass man wissen muss, in welcher Kodierung diese Datei gelesen/gespeichert werden soll. Das Unicode-Konsortium hat hierfür einen BOM definiert, welcher ganz am Anfang der Datei steht und die Kodierung (für Unicode) definiert. Mit diesem BOM können aber nur die Unicode-Kodierungen unterschieden werden. Es ist nichts allgemeingültiges, womit man auch andere Codepages unterscheiden könnte.
Wenn kein BOM vorhanden ist, so kann nicht eindeutig ermittelt werden, um welches Encoding es sich bei einer (Text-)Datei handelt. Es ist einzig eine "Statistische Analyse" des Textes möglich, wie es z.B. Notepad mittels der WinAPI-Funktion
IsTextUnicodemacht.3.3 Blocks
Unicode definiert zusammengehörige Zeichen in einem Block. Ein Block ist z.B. der ASCII-Block (Basic-Latin U+0000 bis U+007F). Um für kommende Zeichen genug Platz zu lassen, entstehen natürlich in einigen Blöcken Lücken die freigelassen wurden. Daraus wird auch ersichtlich warum erst ca. 9% aller Codepoints vergeben sind.
3.4 Kategorien
Jedem Codepoint ist (min.) eine Kategorie zugeordnet. Es gibt insgesamt 33 Kategorien. Eine Kategorie ist z.B. "Letter, Lowercase" (Kleinbuchstabe). In dieser Kategorie sind z.B. 1634 Zeichen vorhanden.
3.5 Besonderheiten von Unicode
Unicode versucht alle Probleme die man mit Sprachen und deren dazugehörigen Zeichen hat zu lösen. Aus diesem Grunde ist auch der Standard schon fast unüberschaubar geworden und es gibt wohl nur wenige Menschen die alle Bereiche vollständig verstanden haben. Im Folgenden will ich einzelne dieser Besonderheiten vorstellen.
3.5.1 Zahlen
Viele Programme müssen mit Zahlen arbeiten. Aber eigentlich fast alle beschränken sich dabei auf die uns bekannten Zahlen 0-9. Im Unicode-Standard sind aber über 836 Codepoints als Zahlen (Numbers) definiert! So gibt es z.B. das Zeichen U+216B (ROMAN NUMERAL TWELVE), welches als Zahl mit dem Wert 12 definiert ist. 290 von diesen Zahlen sind als Decimal Digits definiert und können somit 1-zu-1 mit dem uns bekannten Stellenwertsystem (Digits 0-9) ausgetauscht werden. 210 Zahlen sind so genannte Buchstaben-Zahlen, also Zahlen, welche sich nicht direkt mit einem "Digit" (also Zahlen die durch ein Stellenwertsystem zwischen 0 und 9 verwenden lassen) darstellen lassen. Die dritte Kategorie von Zahlen sind Sonstige Zahlen. Diese beinhalten z.B. auch Brüche (z.B. Ein viertel (1/4)) oder die Zahl "eins weniger als die vorherige".
Leider existiert auch hier in der C/C++-Welt keine mir bekannte Bibliothek, welche diese Eigenheit von Unicode vollständig unterstützt. So "kennt" z.B. die Funktion
iswdigitje nach verwendetem OS bestimmte Zahlen nicht...Mein GCC 3.3.4 unter Linux v2.6.8 kennt z.B. die Zahl ARABIC-INDIC DIGIT FIVE nicht. Dagegen erkennt es das gleiche Programm unter Windows XP (die MS-CRT verwendet intern
GetStringTypeW, welches viele Zeichen kennt).#include <stdio.h> #include <ctype.h> int main() { if (iswdigit(0x0035) == 0) printf("'DIGIT FIVE' ist KEINE Zahl"); if (iswdigit(0x0665) == 0) printf("'ARABIC-INDIC DIGIT FIVE' ist KEINE Zahl"); return 0; }Im .NET-Framework 2.0 gibt es in der
Char-Klasse, viele für Unicode notwendige Hilfsfunktionen. So kann man z.B. mittelsusing namespace System; int main() { Console::WriteLine("'DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0035)); Console::WriteLine("'ARABIC-INDIC DIGIT FIVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x0665)); Console::WriteLine("'ROMAN NUMERAL TWELVE' hat den Zahlenwert {0}", Char::GetNumericValue(0x216B)); }die Zahlenwerte dieser Unicode-Codepoints ermitteln.
Am Ende des Artikels findet sich noch ein Beispiel, welches alle (in .NET 2.0) bekannten Zahlen mit den dazugehörigen Werten ausgibt.
3.5.2 Combining-Characters
Die uns geläufigen Zeichen wie ä, ö, ü usw. sind ja etwas besondere Zeichen. Das 'ä' ist ja eigentlich ein 'a' mit einem Diakritischem Zeichen. Und genau dieser Sachverhalt kann auch in Unicode abgebildet werden. Das Zeichen 'ä' kann entweder als ein verbundenes Zeichen (precomposed character) geschrieben werden (U+00E4) oder als Kombination aus einem Basiszeichen (a) und einem Diaresis (combining-character): U+0061 U+0308.
Ein Combining Character ist somit ein Zeichen, was immer mit einem Basiszeichen zusammen dargestellt wird. Es ist auch möglich, dass ein Basiszeichen mehrere Combining-Characters enthält. So ist im folgenden Bild das Zeichen U+1EAB als eine Kombination aus einem Basiszeichen und zwei Combining-Characters dargestellt:
Diese Tatsache ist vielen nicht bekannt. Man sollte sich dieses aber wirklich verinnerlichen! Daraus ergeben sich erhebliche Konsequenzen. So ist z.B. das Vergleichen von Strings nicht mehr so trivial und muss ganz anders ablaufen. Auch hat es Auswirkung auf die Eingabe von Zeichen und das "Durchgehen" des Textes mittels der Cursor-Tasten. Wurde z.B. das obige Zeichen U+1EAB als Combining-Character eingeben, welches aus 3 Codepoints besteht, so wäre es für den Benutzer einer Textverarbeitung sehr verwunderlich, wenn man drei mal die "Pfeil nach rechts" Taste drücken müssen, um hinter das Zeichen zu kommen.
Hier schließt sich auch wieder der Kreis zu den MBCS-Zeichensätzen. Hier hat man nämlich genau dasselbe Problem, dass ein Codepoint nicht unbedingt ein Zeichen (Glyph) sein muss. UTF8/16 kann man ja auch als MBCS ansehen und somit wird auch deutlich, warum es eigentlich egal ist wenn man nicht UTF-32 zur Speicherung der Zeichen verwendet: Ein Aufwand bei der Darstellung und dem "durchgehen" von Zeichen hat man so oder so. Deshalb kann es nicht als Nachteil angesehen werden, wenn man intern kein UTF-32 verwendet.
3.5.3 Compatibility characters
"Compatibility characters" sind Codepoints, welche nur aufgenommen wurden um eine bessere Kompatibilität mit schon bestehenden Codepages herzustellen und somit eine einfache Konvertierung von diesen Codepages nach Unicode und wieder zurück zu ermöglichen. Man unterschiedet dabei zwischen Codepoints welche sich 1-zu-1 auf ein anderen Codepoint mappen lassen (so z.B. U+F900 welches sich direkt nach U+8C48 mappen lässt) und solchen Zeichen, die eigentlich aus mehreren Zeichen bestehen (Composite Character) aber auch mit mehreren einzelnen Zeichen angezeigt werden können (Decomposed Character). Ein Beispiel hierfür ist "bar", welches natürlich auch aus den Einzelbuchstaben bar zusammengesetzt werden kann.
3.5.4 Normalization
Aus den obigen Ausführungen kann man erkennen, dass es für einen Satz fast beliebig viele Darstellungsmöglichkeiten gibt (z.B. Combining/Compatibility-Characters). Um dieses Wirrwarr etwas zu entzerren hat man sog. "Normalisierungs-Formen" eingeführt. Jeder String kann in solch eine Form überführt werden (ist auch Voraussetzung für den Textvergleich und die Sortierung; wobei die Normalisierung dabei nur ein Schritt ist!). Es gibt die folgenden Normalisierungen:
- Normalization Form D (NFD, Canonical Decomposition):
Spaltet zusammengesetzte Zeichen in die einzelnen Bestandteile auf (wenn möglich). So wird z.B. das Zeichen 'Ä' in die Darstellung als U+0041 U+0308 überführt. - Normalization Form C (NFC, Canonical Decomposition, followed by Canonical Composition):
Ist das Gegenteil von NFD: Hier werden zusammengesetzte Zeichen bevorzugt (wenn möglich). So wird anstelle von 'LATIN CAPITAL LETTER A', 'COMBINING DIAERESIS' das Zeichen 'LATIN CAPITAL LETTER A WITH DIAERESIS' verwendet.
Auch werden veraltete, kombinierte Zeichen durch neue ersetzt, z.B. 'ANGSTROM SIGN' wird durch 'LATIN CAPITAL LETTER A WITH RING ABOVE' ersetzt. - Normalization Form KD (NFKD, Compatibility Decomposition):
Ist wie "Form D", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht. - Normalization Form KC (NFKC, Compatibility Decomposition, followed by Canonical Composition):
Ist wie "Form C", nur werden "compatibility character" durch richtige (aktuelle) Zeichen ersetzt. So wird z.B. anstelle aus dem einen Zeichen fi die zwei Einzelbuchstaben "fi" gemacht.
Bei allen diesen Normalisierungen ist zu beachten, dass es Fälle gibt in denen ein "Round-Trip" zur ursprünglichen Kodierung nicht mehr möglich ist. Auch kann sich die Bedeutung verändern (wenn z.B. das einzelne Zeichen bar durch die drei Einzelbuchstaben "b a r" ersetzt wird.
In der Windows-API kann eine Normalisierung in diese Formen mittels der Funktion
FoldStringdurchgeführt werden.Im .NET-Framework 2.0 hat die
String-Klasse eine Methode um einen String zu normalisieren bzw. abzufragen ob der String normalisiert ist (siehe dazu auch meine Anfrage an Michael Kaplan von Microsoft).
Auch gibt es in dem NamespaceSystem::Globalizationsehr viele Klassen die sich mit Unicode und sonstigen Dingen der Globalisierung beschäftigen. Ebenso in dem NamespaceSystem::Text, welche z.B. auch Klassen zur Konvertierung von Strings in diverse Zeichensätze anbietet.Linux: Es gibt wohl diverse LIBs die das können (siehe Links weiter unten).
3.5.5 BiDi-Classes
Der Unicode-Standard definiert (hauptsächlich) wie die Strings im (Haupt-)Speicher kodiert werden. Dies wird auch als "logische Reihenfolge" bezeichnet. Diese Reihenfolge muss aber nicht unbedingt mit der Reihenfolge wie die Texte dargestellt werden identisch sein! In unsere Hemisphären kennen wir eigentlich nur die Links-Nach-Rechts (LTR) Schriftarten. Es gibt aber auch Sprachen, wo die Schreibweise von Rechts-Nach-Links (RTL) geht. Da Unicode alle Zeichen und Sprachen abdeckt (besser gesagt: "fast alle", da sich das Konsortium bis heute weigert "Klingonisch" aufzunehmen; aber die beiden Sprachen (Tengwar und Cirth) von J. R. R. Tolkien will man zukünftig aufnehmen), wurden natürlich auch solche Dinge berücksichtigt. Wenn nun RTL- und LTR-Texte gemischt werden, so redet man von bi-directional Text. Um auch hier eine einheitliche Vorgehensweise zu erlauben wurden dazu für jedes Zeichen bestimmte Properties aufgenommen (also wie das Zeichen bzgl. RTL/LTR dargestellt werden soll) und es wurde eine eigene Standard-Beschreibung definiert.
Für jedes Zeichen ist somit genau definiert, wie es sich in einem BiDi Umfeld verhalten soll. Dieses Verhalten kann mit expliziten Angaben von "Schreibrichtungen" verändert werden.
Das "durchgehen" solch eines Satzes von links nach rechts ist für uns etwas ungewohnt, da die Position des Carets ungewöhnlich "springt":
.In dem obigen Beispiel werden die folgenden Codepoints verwendet und diese auch in dieser Reihenfolge in der Datei/Speicher abgelegt:
U+0044 U+0069 U+0065 U+0020 U+0648 U+064E U+0631 U+0652 U+062F U+064E U+0629 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002E
Die Reihenfolge auf dem Bildschirm ist aber eine etwas andere:
U+0044 U+0069 U+0065 U+0020 U+0629 U+064E U+062F U+0652 U+0631 U+064E U+0648 U+0020 U+0076 U+0065 U+0072 U+0077 U+0065 U+006C U+006B U+0074 U+002EHierzu noch eine kleine Quizfrage: Wenn das Caret mitten in einem RTL Text steht und man "Backspace" drückt, in welche Richtung bewegt sich das Caret und welches Zeichen wird gelöscht?
Den genauen Algorithmus zum Erzeugen eines Sortkeys zu beschreiben würde den Rahmen dieses Dokumentes bei weitem Sprengen. Für detaillierte Infos, siehe den #TR9-Standard.
(PS: Es ist nicht so schlimm wenn man es nicht ganz verstanden hat, Microsoft hat es auch noch nicht
)3.5.6 Textvergleich und Sortierung
Ein Textvergleich von Unicode-Strings ist eines der komplexesten, was es im Unicode Standard gibt (noch komplexer als BiDi!). Der (aktuelle) Textvergleich wird durch den "Unicode Technical Standard #10 (Unicode Collation Algorithm)" definiert. Ausgedruckt ergibt dies bei mir ca. 78 DIN A4 Seiten.
Ganz grob kann man sagen: Jedem Codepoint (Zeichen) ist ein (oder mehrere) Gewichtungsfaktor(en) zugeordnet. Anhand dieser Gewichte und anderen Kriterien (z.B. Ignorierung der Groß- und Kleinschreibung) wird ein "Sort Key" zusammengestellt, mit dem dann ein String verglichen werden kann. Diese Gewichtungsfaktoren sind entweder explizit für ein Zeichen definiert oder er kann aus der Position und sonstigen Eigenschaften berechnet werden.
Ein kleines Beispiel: Es soll der Sort-Key für den String "Öde" erstellt werden.
Hierzu muss man zuerst den String in die Normalform NFD bringen. Dies ergibt dann
U+004F U+0308 U+0064 U+0065.
Nun muss in der Tabelle für die Weights nachgeschaut werden und daraus ergibt sich das folgende "Collection Element Array":(113B.0020.0008), (0000.0047.0002), (1010.0020.0002), (1029.0020.0002)Nun hat man die Gewichte für alle 4 Zeichen. Dabei ist der erste Eintrag das Primäre Gewicht, der zweite das Sekundäre Gewicht und das dritte das Tertiäre Gewicht.
Aus diesem "Collection Element Array" wird nun der Sortkey gebildet, indem man die primäre, sekundäre und tertiäre Gewichte in der richtigen Reihenfolge anordnet (und man lässt die Zahlen weg, welche 0 sind). Daraus ergibt sich dann der Sortkey:113B, 1010, 1029 | 0020, 0047, 0020, 0020 | 0008, 0002, 0002, 0002Diese Zahlen kann man nun mit anderen Sortkeys mit einem "normalen"
memcmpvergleichen. Wie man aber auch sehen kann, wird ein Sortkey sehr lang. Er braucht somit wesentlich mehr Platz als der String selbst. Deshalb gibt es auch hier Komprimierungen, welche den Sortkey wieder wesentlich reduzieren, damit das Vergleichen noch (Speicherplatz-)effizienter wird.Auch hier kann ich aber aus Platzgründen nicht vollständig auf den Algorithmus eingehen. Eine genaue Erklärung gibt es wiederum im Unicode Technical Standard #10.
Trotzdem ein paar Links:
In Windows kann z.B. mittels der Funktion
LCMapStringmit dem, FlagLCMAP_SORTKEYein Sortkey für jeden beliebigen String erzeugt werden. Das gleiche gibt es für Linux in der ICU-Lib.3.6 Beispiele mit Unicode
3.6.1 Gleiche Dateinamen unter Windows
Per Definition ist es unter Windows nicht möglich zwei Dateien mit dem gleichen Dateinamen im selben Verzeichnis anzulegen. Ein Versuch dies zu machen, wird scheitern. Mit dem Wissen von Unicode und dem Wissen, dass das Dateisystem eigentlich kein Unicode unterstützt, sondern die übergebenen (2-Byte langen) Zeichen einfach 1-zu-1 übernimmt, kann man jetzt Dateinamen erzeugen, die genau gleich angezeigt werden, aber unterschiedlich im Dateisystem gespeichert sind:
#include <windows.h> #include <tchar.h> int _tmain() { // File names with same names! wchar_t name1[] = {'\\', 'B', 0xE4, 0x0}; // \Bä wchar_t name2[] = {'\\', 'B', 0x61, 0x0308, 0x0}; // \Bä HANDLE h1 = CreateFileW(name1, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); HANDLE h2 = CreateFileW(name2, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL); CloseHandle(h2); CloseHandle(h1); return 0; }Hiermit hat man jetzt zwei Dateien, die "Bä" heißen (was eigentlich nicht sein sollte). Hätte der NTFS-Treiber eine korrekte Implementierung von Unicode, so würde er erkennen, dass beide Strings genau gleich sind und dies somit nicht zulassen.
3.6.2 Beispiele von speziellen Unicode-Zeichen
Ein ganz besonderes Unicode-Zeichen ist z.B. das SOFT HYPEN (U+00AD). Das ist ein Bindestrich, welcher nur manchmal sichtbar ist. Im Folgenden habe ich einen Text erstellt, welcher so viel wie möglich dieses Zeichen enthält. Wenn man also den Browser ganz eng zusammenschiebt, so sieht man, dass manchmal aus dem "nichts" ein Bindestrich zur Silbentrennung auftaucht (zumindest beim IE6).
<html>
<head>
</head>
</body>
Es werde eine Feste zwischen den Wassern, die da scheide zwischen den Wassern.
Da machte Gott die Feste und schied das Wasser unter der Feste von dem Wasser über der Feste. Und es geschah so.
</body>
</html>(das ganze gibt es auch hier zum separaten Anschauen)
3.7 Einschränkungen von C/C++
C/C++ kennt für Unicode den Datentypwchar_t. Alle zeichenorientierten Unicode-Varianten der CRT nehmen diesen Datentyp entgegen. Bei den MS-Compilern ist dieser Datentyp 16-Bit lang. Dies hat zur Folge, dass aktuell keine Unterstützung für Unicode-Codepoints > U+FFFF vorhanden ist, da hierfür 32-Bit (oder 2x16-Bit) notwendig wären. So kann man z.B. mitiswdigitdas Zeichen 'MATHEMATICAL MONOSPACE DIGIT FIVE' (U+1D7FB) nicht als Zahl erkennen. Hier wäre es notwendig, dass alle Unicode-Funktionen einen String entgegen nehmen würden und intern konsequent in UTF-8/16/32 kodiert würden. Bei einigen anderen Compilern istwchar_t32-Bit, womit eine vollständige Abbildung aller Unicode-Codepoints in einemwchar_tmöglich ist.3.8 Unterstützung von Unicode in .NET 2.0
.NET hat eine sehr vollständige Implementierung von Unicode. So werden auch die Codepoints > U+FFFF unterstützt. Strings werden intern als UTF-16 abgespeichert.
Mit dem folgenden Code kann man z.B. alle Unicode-Zeichen durchgehen und z.B. ermitteln, ob dieses eine Zahl ist und den Wert dazu ausgeben.
using namespace System; int main() { for(int c=0; c<=0x10FFFF; c++) { if ((c >= 0x00d800) && (c <= 0x00dfff)) continue; // überspringe die Surrogates String ^s = Char::ConvertFromUtf32(c); if (Char::IsNumber(s, 0)) { Console::WriteLine("'0x{0:X}' hat den Zahlenwert {1}", c, Char::GetNumericValue(s, 0)); } } }4 Konvertierung zwischen unterschiedlichen Codepages
Möchte man Strings von einer Codepage in eine andere Codepage konvertieren, so ist der einfachste Weg, wenn man über Unicode geht.
Man konvertiert zuerst den Ausgangsstring nach Unicode (UTF-x Kodierung spielt dabei keine Rolle) und kodiert dann diesen Unicode-String in das Zielencoding. Unter Windows kann man hierzu
MultiByteToWideCharundWideCharToMultiByteverwenden. Für ein (schlechtes) Beispiel siehe Looking Up a User's Full Name.5 Anhang
5.1 Eingabe von Unicode-Zeichen
In Windows gibt es verschiedene Methoden Unicode-Zeichen einzugeben. Aus meiner Erfahrung gehen aber nicht alle Eingabemethoden in allen Programmen. Die universalste ist die Verwendung eines Unicode-IME (Input Methode Editors). Eine kurze Beschreibung wie man dies aktiviert hat der i18n Guru von Microsoft hier aufgeführt.
5.2 Links
5.2.1 Unicode allgemein
5.2.2 C/C++ Allgemein
5.2.3 Linux und Unicode
- UTF-8 and Unicode FAQ for Unix/Linux
- Linux-Howtos: Making your programs Unicode aware
- Linux Unicode programming
5.2.4 Unicode-Libraries für Linux
6 Nachwort
Die häufige Verwendung von Microsoft-Produkten rührt daher, dass ich diese hauptsächlich verwende. Ich habe mich bemüht aus dem Linux-Lager Infos zu finden, mir konnte dies aber nicht so gelingen wie erhofft. Für sachdienliche Hinweise bin ich jederzeit offen!
- Normalization Form D (NFD, Canonical Decomposition):
-
Jochen, ist der erste Beitrag der, der veröffentlicht werden soll?

-
Nein, natürlich immer der letzte... im Folgenden noch mals die aktuelle Version:
-
Oh, okay entschuldige.
Ich dachte nur, weil im ersten die neuen Tags sind - aber da hattest du ja Probleme.
Okay, ich nehm dann den von eben.")
-
Jochen? Der Artikel ist noch auf R. Ist das Absicht?
-
Natürlich nicht, sorry... hab vergessen das ICH das umstellen muss