[X] Binärer Suchbaum
-
Dies wird (hoffentlich) die letzte Version sein in der es große Änderungen gab. Bitte lest ihn euch durch und meldet falls eine Stelle undeutlich oder gar falsch ist. Ich bin für jedes Feedback egal ob positiv oder negativ dankbar.
Das Inhaltsverzeichnis mach ich glaub ich aber noch weg. Es verscheucht glaub ich zu viele Leser.
================
Inhaltsverzeichnis
-
1 Suchen das Problem
-
2 Binäre Suchbäume
-
2.1 Suchen
-
2.2 Maximum und Minimum
-
2.3 Durchwandern
-
2.3.1 Knoten mit rechtem Kind
-
2.3.2 Knoten ohne rechtes Kind
-
2.4 Einfügen
-
2.5 Löschen
-
2.5.1 Löschen eines Knoten ohne Kinder
-
2.5.2 Löschen eines Knoten mit einem Kind
-
2.5.3 Löschen eines Knoten mit zwei Kindern
-
2.6 Ausbalancierte Bäume und die die es nicht sind
-
2.7 Rotationen
-
3 Implementierung
-
3.1 Navigation
-
3.2 Debuggen
-
3.2.1 Konsolenausgabe
-
3.2.2 Tod dem Zeigersalat
-
3.3 Kopiekonstruktor, Destruktor und Zuweisung
-
3.4 Suchen
-
3.5 Einfügen
-
3.6 Austauschen
-
3.7 Minimum und Maximum
-
3.8 Durchwandern
-
3.9 Löschen
-
3.10 Rotationen
-
4 Bäume in der STL
-
5 Ausblick
1 Suchen das Problem
Sei es eine Datenbank oder ein Dateisystem: Das Suchen nach Werten ist eines der häufigsten Probleme in der Informatik. Das im Grunde einfach klingende Problem erweist sich als ein außerordentlich komplexes Biest sobald man über den Tellerrand der trivialen Ansätze blickt.
Für viele Anwendungen recht ein Array in das man sämtliche Werte rein schmeißt und anschließend von Anfang bis Ende durchläuft. Wenn die Datenbank aber wächst dann wird dieser Ansatz aber unvertretbar langsam. Der erste Verbesserungsvorschlag wird dann wohl sein das Array zu sortieren und es dann mit der Hilfe einer binären Suche zu durchwühlen. Solange sich die Element des Arrays nur wenig verändert ist dieser Ansatz gut andernfalls stößt auch er an seine Grenzen.
Wer noch mehr Geschwindigkeit braucht der muss sich vom einfachen Array verabschieden und auf eine andere Datenstruktur ausweichen. Ein Ansatz ist die Werte in einer Hash-Tabelle zu speichern. Diese sind in manchen Anwendungen kaum zu überbieten. Aber auch sie haben ihre Schwächen wenn die Anzahl der Elemente unerwartete Größen annimmt. Des Weiteren schneiden sie schlecht ab wenn man mehr tun will als nur Suchen wie zum Beispiel der iterative Zugriff auf die Elemente. Ist die Tabelle zu groß so wird es ewig dauern sie zu durchforsten um sämtliche Elemente wieder zu finden.
Hash-Tabelle werden aber nicht das Thema dieses Artikels sein, vielmehr wird es eine Weiterentwickelung der binären Suche sein: Der binäre Suchbaum. Dieser passt sich hervorragend einer großen Anzahl von Elementen an und erlaubt es die Element sogar sortiert aufzulisten.
2 Binäre Suchbäume
In einem Suchbaum weist man jedem Knoten ein Element zu und sorgt dafür, dass alle Elemente des linken Unterbaums kleiner und die des rechten Unterbaums größer sind.

2.1 Suchen
Um ein Element zu suchen beginnt man die Suche an der Wurzel. Falls die Wurzel den gesuchten Wert darstellt ist man schon fertig. Sonst vergleicht man ob der dieser kleiner oder größer ist und setzt seine Suche im entsprechenden Unterbaum fort. Wenn man auf der untersten Ebene des Baums angelangt ist ohne den Wert gefunden zu haben dann ist er nicht im Baum enthalten.
In folgendem Beispiel wird die 7 gesucht.

Um ein Element zu finden müssen wir im schlimmsten Fall von der Wurzel bis zur untersten Ebene wandern. Im besten Fall hat der Baum eine Höhe die logarithmisch von der Anzahl seiner Elemente abhängt. Dies gibt also in etwa eine Laufzeitkomplexität von O(log(n)) um ein Element zu suchen wenn wir ungünstige Bäume ignorieren. n ist die Gesamtanzahl der Elemente im Baum.
2.2 Maximum und Minimum
Da die Elemente geordnet im Baum vorliegen ist das kleinste Element das was sich am linken Ende des Baums befindet. Man findet es indem man die Suche an der Wurzel beginnt und sie dann nach links fort setzt bis man an einem Knoten angelangt welcher keinen linken Unterbaum mehr hat. Das größte Element findet man ähnlich, nur dass man nach rechts wandern muss.

Im schlimmsten Fall müssen wir den Baum von oben nach unten durchwandern also ist die Laufzeitkomplexität dieselbe wie die bei der Suche eines Elements das heißt O(log(n)).
2.3 Durchwandern
Um die Elemente eines Baums in geordneter Reihenfolge zu durchwandern beginnt man seine Suche beim Minimum und sucht dann immer das nächste größere Element, bis dass man beim Maximum angelangt ist.

Wie man zum nachfolgenden Knoten im Baum gelangt hängt von der Position im Baum ab von der man startet. Genauer gesagt hängt es davon ab ob der Ausgangsknoten ein rechtes Kind besitzt oder nicht.
2.3.1 Knoten mit rechtem Kind
Falls es einen rechten Unterbaum gibt so ist das nächste Element das Minimum dieses Unterbaums.
In folgendem Beispiel suchen wir das Element das der 5 folgt. Dazu begeben wir uns zuerst in den rechten Unterbaum und dann suchen wir das Minimum indem wir solange nach links wandern wie nur möglich.

2.3.2 Knoten ohne rechtes Kind
Sollte es kein rechtes Kind geben, so muss man Richtung Wurzel des Baums klettern. Falls man unterwegs auf einen Knoten stößt welchen man von seinem linken Kind aus erreicht hat so hat man das nächste Element gefunden.

Der Algorithmus um den Baum vom Maximum zum Minimum zu durchwandern ist genau spiegelverkehrt und darum werde ich nicht weiter auf ihn eingehen.
Beim durchwandern des gesamten Baums wird jede Kante genau zweimal begangen wenn man das Bestimmen des Minimum und Maximum hinzuzählt. Da es nur einen Knoten mehr gibt als Kanten hat das Durchwandern eine Laufzeitkomplexität von O(n). Um das nächste Element zu finden muss man im schlimmsten Fall von der untersten Ebene bis zur Wurzel oder andersherum wandern. Diese hat Operation hat also eine Laufzeitkomplexität von O(log(n)) im ungünstigsten Fall ist aber meisten wesentlich besser.
Es gibt einen alternativen Ansatz der die Knoten noch zusätzlich zum Baum in einer geordneten verketteten Liste zusammen strikt. Dies beschleunigt das Durchwandern um einen konstanten Faktor und sorgt dafür, dass das Bestimmen des nächsten Elements immer eine konstante Laufzeit besitzt. Der Preis ist allerdings der Mehraufwand um die verkettete Liste zu verwalten. Falls man den Baum oft durchwandern muss sollte man diese Option in betracht ziehen.
2.4 Einfügen
Um einen Wert einzufügen geht man ähnlich vor wie bei der normalen Suche. Man wandert solange nach unten, bis man einen Knoten gefunden hat der noch ein Kind, an der richtigen Seite, frei hat.
In folgendem Beispiel wird die 8 eingefügt.

Da es sich im Wesentlichen um den gleichen Algorithmus handelt wie bei der Suche ist auch die Komplexität die gleiche und zwar O(log(n)).
2.5 Löschen
Als erstes sucht man den zu löschenden Knoten nach bekannter Methode. Wie man danach vorgeht hängt von der Position des Knoten im Baum ab, das heißt wie viele Kinder der Knoten hat.
2.5.1 Löschen eines Knoten ohne Kinder
Um ein Blatt zu löschen trennt man es einfach vom Elternknoten ab.
Folgendes Beispiel zeigt wie die 5 aus dem Baum gelöscht wird:


2.5.2 Löschen eines Knoten mit einem Kind
Falls es es nur ein Kind gibt so wandert dieses den Platz des Knoten. Man trennt den zu löschenden Knoten von Kind- und Elternknoten und verbindet danach diese zwei.
Im nächsten Beispiel wird die 3 gelöscht.


2.5.3 Löschen eines Knoten mit zwei Kindern
Ein Knoten mit zwei Kindern lässt sich nicht einfach löschen. Wer aber leicht gelöscht werden kann ist das vorhergehende oder nachfolgende Element. Bei beiden handelt es sich nämlich um das Maximum respektiv dem Minimum des linken beziehungsweise rechten Unterbaums. Aus diesem Grund haben sie höchstens ein Kind und können daher mit einem der beiden oben genannten Methoden gelöscht werden.
Ob man sich für das nachfolgende oder vorhergehende Element entscheidet spielt keine große Rolle. Keine der beiden Optionen hat einen wirklichen Vorteil oder Nachteil.
In folgendem Beispiel wird die 7 gelöscht.



Manche Leser werden sich an diesem Punkt vielleicht fragen ob es denn immer ein nachfolgendes und vorhergehendes Element gibt. Es könnte ja sein, dass man den Auftrag erhalten hat das erste oder letzte Element zu löschen. Da es sich bei beiden allerdings um ein Minimum oder Maximum handelt können sie keine zwei Kinder besitzen und daher ist ein Austauschen gar nicht erst nötig.
Die Geschwindigkeit der eigentlichen Löschverfahren sind alle unabhängig von der Größe des Baums. Legendlich die Suche des zu löschenden Elements und das Bestimmen des nachfolgenden oder vorhergehenden Elements hängen von der Größe ab, darum ist die Komplexität einer Löschoperation in etwa O(log(n)).
2.6 Ausbalancierte Bäume und die die es nicht sind
Eines der großen Probleme solcher Bäume ist, dass wenn die Reihenfolge der Einfügungen ungünstig ist der Baum sehr schnell aus dem Gleichgewicht kommt und zu einer Seite hinkt. Dies macht den Baum sehr viel höher als nötig und somit die Suche viel langsamer da diese ja von der Höhe des Baums abhängt.
In folgendem Baum wird die 8 gesucht und der Arbeitsaufwand kommt schon nahe an den einer sequenziellen Suche heran.

Um dem entgegen zu wirken kann man Rotationen einsetzen.
2.7 Rotationen
Es gibt Rotationen nach links und nach rechts. Da beide Operationen genau spiegelverkehrt sind werde ich nur auf die links Rotation eingehen.
Als erstes trennt man das linke Kind vom rechten Kind der Wurzel ab und anschießend auch das rechte Kind.

Danach wird das rechte Kind zur neuen Wurzel und die alte Wurzel wird ihr neues rechtes Kind. Das Enkelkind wird zum neuen rechten Kind der alten Wurzel.
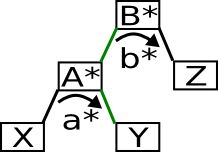
Nun ist der Baum wieder im Gleichgewicht.

Man sagt links Rotation da das Gleichgewicht sich nach links verlagert. Man kann es sich wie eine Balkenwaage vorstellen welche man in das Gleichgewicht bringt indem man den Balken an einer anderen Stelle aufhängt.


Das Beispiel hinkt zwar da nach der Rotation beide Gewichte gleich schwer sind.
Die Geschwindigkeit einer Rotation hängt nicht von der Größe des Baums ab. Die Komplexität ist also O(1).
Das große Problem von Rotationen ist zu wissen wann man sie einsetzen soll. Sie verbessern nämlich nicht immer das Gleichgewicht eines Baums wie folgendes Beispiel zeigt.


Es gibt verschiedene Strategien um hier vorzugehen. Keine ist allerdings wirklich trivial und verdienen alle ihren eigenen Artikel. Da alle aber Rotationen nutzen hab ich sie bereits jetzt eingeführt damit nicht jeder Artikel diese Operation neu beschreiben muss und direkt mit dem wirklich interessanten Teil beginnen kann. Ich werde in diesem Artikel nicht weiter auf ihre Verwendung eingehen.
3 Implementierung
Das erste was man bei einer Implementierung festlegen muss ist die Darstellung. Die Knoten werden durch eine Struktur dargestellt und dann mit Pointern verbunden. Dies sieht in etwa so aus:
template<class T> struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} };parent zeigt auf den Elternknoten. Falls es sich um die Wurzel handelt ist dieser NULL. left und right zeigen jeweils auf die Wurzel des linken oder rechten Unterbaums oder NULL falls es diesen nicht gibt.
Um zu verhindern, dass Unbefugte an unserem Baum rumbasteln wird dieser durch eine Klasse gekapselt. Dies sieht dann in etwa folgendermaßen aus:
template<class T> class Tree{ private: struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} Node*root; public: Tree():root(0){} bool is_empty()const{ return !root; } };root zeigt dabei auf die Wurzel des Baumes oder NULL falls der Baum leer ist. Ob der Baum leer ist kann mittels is_empty überprüft werden.
Es gibt Variationen in denen die Knoten keinen Zeiger auf den Elternknoten besitzen. Dies spart Speicher und erleichtert die Verwaltung der zusätzlichen Zeiger jedoch macht es auch die Implementierung mancher Operationen wie zum Beispiel des Durchwanderns komplizierter. Oft sind diese nur noch durch den Einsatz eines Stapels oder von Rekursivität überhaupt möglich. Welche Option nun die beste ist hängt von Einsatzfall ab.
Manche Leser werden vielleicht auch auf den Gedanken gekommen sein die Elemente in einem Array abzulegen und das Navigieren durch Multiplizieren der Indexe mit 2 abzuwickeln. Für manche Bäume ist dies sicherlich ein sinnvoll Ansatz wie zum Beispiel Heaps wie man in Jesters Artikel dazu nachlesen kann. Für Suchbäume ist dieser Ansatz aber unbrauchbar da Rotationen sich nur sehr schwer implementieren lassen und unausbalancierte Bäume in dieser Darstellung echte Speicherfresser sind.
3.1 Navigation
Um uns beim navigieren im Baum zu helfen schreiben wir uns Funktionen die prüfen ob es sich um ein linkes oder rechtes Kind handelt.
private: static bool is_left_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->left == node; } static bool is_right_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->right == node; }Um die Position eines Knoten ändern zu können muss man auch einen einfachen Zugriff auf den Zeiger im Elternknoten haben. Dies bietet folgende Funktion:
private: Node**get_parent_ptr(Node*node){ if(node->parent == 0) return &root; else if(is_left_child(node)) return &node->parent->left; else return &node->parent->right; }3.2 Debuggen
Da es sehr schwer ist einen Baum fehlerfrei zu implementieren müssen wir uns auch Gedanken machen wie wir ihn debuggen. Wer sich nur für den eigentlichen Code interessiert kann diesen Teil des Artikels getrost überspringen.
3.2.1 Konsolenausgabe
Eine Funktion die den Baum einfach komplett auf die Konsole ausgibt wäre sehr nützlich da die meisten Debugger nicht sonderlich gut sind um solche Datenstrukturen zu inspizieren und nur Zeigersalat anzeigen.
Ziel ist es den Baum ähnlich wie auf den Grafiken oben auszugeben. Dazu müssen wir als erstes festlegen welche Informationen über einen Knoten ausgegeben werden. Dies macht folgende Funktion:
private: static std::string format_label(const Node*node){ if(node){ std::ostringstream out; out<<node->value; return out.str(); }else return ""; }Wir müssen auch wissen wie breit und hoch der Baum wird damit wir wissen wie viel Platz frei gelassen werden muss. Folgende Funktionen berechnen diese Informationen für den Baum und jeden Unterbaum.
private: static unsigned get_height(const Node*node){ if(!node) return 0; unsigned left_height = 0, right_height = 0; if(node->left) left_height = get_height(node->left); if(node->right) right_height = get_height(node->right); // Der höchste Unterbaum bestimmt die Gesamthöhe return std::max(left_height, right_height) + 1; } static unsigned get_width(const Node*node){ if(!node) return 0; unsigned left_width = 0, right_width = 0; if(node->left) left_width = get_width(node->left); if(node->right) right_width = get_width(node->right); return left_width + format_label(node).length() + right_width; }Da wir nur zeilenweise auf die Konsole schreiben können müssen wir den Baum auch Zeile für Zeile ausgeben.
private: static void dump_spaces(std::ostream&out, unsigned count){ for(unsigned i=0; i<count; ++i) out.put(' '); } static void dump_line(std::ostream&out, const Node*node, unsigned line){ if(!node) return; if(line == 1){ // Die Wurzel des Unterbaums soll ausgegeben werden dump_spaces(out, get_width(node->left)); out<<format_label(node); dump_spaces(out, get_width(node->right)); }else{ // In beiden Unterbäumen sind die Wurzeln um eins niedriger und darum verändert // sich die Zeilennumerirung. dump_line(out, node->left, line-1); dump_spaces(out, format_label(node).length()); dump_line(out, node->right, line-1); } }Nun benötigen wir noch eine Möglichkeit den gesamten Baum auszugeben und nicht nur eine Zeile.
private: static void dump_node(std::ostream&out, const Node*node){ for(unsigned line=1, height = get_height(node); line <= height; ++line){ dump_line(out, node, line); out.put('\n'); } out.flush(); } public: void dump(std::ostream&out)const{ dump_node(out, root); }Mit der Hilfe der dump Funktion können wir nun den Baum für den Menschen lesbar anzeigen. Eine mögliche Ausgabe wäre:
6 3 10 1 5 7 12Man könnte den Ausgabealgorithmus sicher noch sehr viel verbessern was die Geschwindigkeit betrifft. Ich glaube jedoch kaum, dass er bei großen Bäumen überhaupt zum Einsatz kommen wird und deshalb werde ich dies sein lassen.
3.2.2 Tod dem Zeigersalat
Bei dem Implementieren von Bäumen wird man oft Zeigern die nicht dahin zeigen wo sie eigentlich sollten. Eine Funktion die testet ob der Baum so überhaupt richtig sein kann hilft viele Fehler zu finden. Man testet zum Beispiel ob der Elternknoten des Kindes eines Knoten dieser selbst ist.
private: bool is_wellformed(Node*node){ if(node == 0) return true; if(*get_parent_ptr(node) != node) return false; if(!is_wellformed(node->left)) return false; if(!is_wellformed(node->right)) return false; return true; }Mit Hilfe eines assert(is_wellformed(root)) können sehr viele Fehler vorzeitig abgefangen werden. Durch ein Paar geschickte gesetzte Breakpoints innerhalb dieser Funktion kann man auch sehr genau erfahren welcher Zeiger falsch ist.
3.3 Kopiekonstruktor, Destruktor und Zuweisung
Da ein Baum keine triviale Datenstruktur ist muss man auch den Kopiekonstruktor, den Destruktor und den Zuweisungsoperator implementieren.
Als erstes implementiere ich den Destruktor. Dieser ist leicht rekursive zu realisieren.
private: static void destroy_node(Node*node){ if(node){ destroy_node(node->left); destroy_node(node->right); delete node; } } public: ~Tree(){ destroy_node(root); }Bei sehr großen Bäumen kann es bei diesem Destruktor zu einem Stapelüberlauf kommen. In diesem Fall muss man ihn iterative formulieren. Die Idee ist immer das Blatt zu löschen das den kleinsten Wert aller Blätter darstellt also sich auf der linken Seite des Baums befindet. Durch das Abschneiden der ersten Blätter entstehen neue und der Baum schrumpft zusammen, bis dass er schlussendlich nicht mehr existiert.
~Tree(){ Node*now = root; while(now){ if(now->left) now = now->left; else if(now->right) now = now->right; else{ Node*next = now->parent; *get_parent_ptr(now) = 0; delete now; now = next; } } }Der Kopiekonstruktor kann auch rekursive implementiert werden man muss jedoch aufpassen ob eine Ausnahme fliegt oder nicht. Dies wird schnell unübersichtlich und fehleranfällig. Darum bevorzuge ich die iterative Version. Die Idee ist den alten und neuen Baum so zu durchlaufen wie wir es im Destruktor tun und dabei alle Knoten klonen welche im alten Baum vorhanden sind jedoch nicht im neuen.
Mit dieser Methode ist der Baum immer in einem gesunden Zustand und kann vom Destruktor auch im unvollendeten Zustand gelöscht werden. Falls eine Ausnahme fliegt brauchen wir nur den Destruktor mit der Arbeit zu beauftragen den halbfertigen Baum zu löschen.
Tree(const Tree&other){ if(!other.is_empty()){ root = new Node(other.root->value); try{ Node *now = root, *other_now = other.root; while(other_now){ if(other_now->left && !now->left){ now->left = new Node(other_now->left->value); now->left->parent = now; now = now->left; other_now = other_now->left; }else if(other_now->right && !now->right){ now->right = new Node(other_now->right->value); now->right->parent = now; now = now->right; other_now = other_now->right; }else{ now = now->parent; other_now = other_now->parent; } is_wellformed(root); } }catch(...){ this->~Tree(); throw; } } }Der Zuweisungs-Operator kann leicht mit Hilfe des Copy&Swap-Idioms implementiert werden.
public: void swap(Tree&other){ std::swap(root, other.root); } Tree&operator=(const Tree&other){ Tree temp(other); swap(temp); return *this; }3.4 Suchen
Implementieren wir nun die Suchfunktion. Da wir die innere Struktur der Klasse verstecken wollen stellen wir dem Außenstehenden nur eine Funktion zur Verfügung die testet ob ein Wert im Baum enthalten ist.
Man sollte bemerken, dass man es dem Benutzer nicht erlauben sollte den Wert des Knoten zu verändert, da dies die Position im Baum durcheinander bringen kann. Falls er dies beabsichtig, dann soll er den alten Wert rauslöschen und den neuen einfügen damit sich das Element an der richtigen Stelle befindet.
Durch den Einsatz von Templates spare ich mir eine const und eine nicht-const Version zu schreiben.
private: template<class NodeT> static NodeT*search(NodeT*root, const T&value){ NodeT*now = root; while(now){ if(value < now->value) now = now->left; else if(now->value < value) now = now->right; else return now; } return 0; } public: bool contains(const T&t)const{ return search(root, t); }3.5 Einfügen
Um ein Element einzufügen verfahren wir ähnlich jedoch behalten wir uns wo sich der Elternknoten befindet.
public: bool insert(const T&value){ Node *parent = 0, *now = root; bool is_left_child = false; while(now){ parent = now; if(value < now->value){ is_left_child = true; now = now->left; }else if(now->value < value){ is_left_child = false; now = now->right; }else return false; // Das Element ist bereits im Baum } Node*new_node = new Node(value); new_node->parent = parent; if(parent == 0) root = new_node; else if(is_left_child) parent->left = new_node; else parent->right = new_node; // Wenn etwas mit den Zeigern falsch ist // dann knallt es wahrscheinlich hier. assert(is_wellformed(root)); return true; }3.6 Austauschen
Knoten können durch austauschen der Werte getauscht werden. Dies ist sicherlich der beste Weg falls man Ganzzahlen speichern will. Es gibt jedoch auch Klassen welche sehr teuer zu tauschen sind oder die gar nicht getauscht werden können. Es ist auch möglich, dass es Zeiger auf das Element gibt die außerhalb des Baums liegen und verändert werden müssten, oder dass beim Tauschen eine Ausnahme fliegen kann. Diese Probleme kann man dadurch umgehen, dass man die Zeiger der Knoten neuverbindet. Hierbei ist der allgemeine Fall vom Fall wo einer der beiden Knoten das Kind des anderen ist zu unterscheiden.
Man sollte beachten, dass das Tauschen von Knoten wahrscheinlich die Ordnung im Baum durcheinander bringt. Es sollte also sicher gestellt sein, dass diese nachdem diese Funktion ihre Arbeit getan hat wiederhergestellt wird.
private: void swap_near_nodes(Node*child, Node*parent){ // Als erstes passen wir den unbeteiligten Großelternknoten an. *get_parent_ptr(parent) = child; // Anschließend werden die Kind- und Elternzeiger ausgetauscht. std::swap(parent->left, child->left); std::swap(parent->right, child->right); std::swap(parent->parent, child->parent); // Da eines der Kinder getauscht wird benötigt es eine // sonder Behandlung. if(child->left == child) child->left = parent; else child->right = parent; // Nun sind alle Kindzeiger richtig und die Elternzeiger können // dem angepasst werden. if(child->left) child->left->parent = child; if(child->right) child->right->parent = child; if(parent->left) parent->left->parent = parent; if(parent->right) parent->right->parent = parent; // Na wer ist sich noch sicher ob wir nicht // bereits Zeigersalat haben? Besser testen! assert(is_wellformed(root)); } void swap_far_nodes(Node*a, Node*b){ // Zuerst updaten wir die Zeiger der Eltern *get_parent_ptr(a) = b; *get_parent_ptr(b) = a; // Danach der Kinder if(a->left) a->left->parent = b; if(a->right) a->right->parent = b; if(b->left) b->left->parent = a; if(b->right) b->right->parent = a; // Und als letztes die der beiden Knoten std::swap(a->left, b->left); std::swap(a->right, b->right); std::swap(a->parent, b->parent); assert(is_wellformed(root)); } void swap_nodes(Node*a, Node*b){ if(a->parent == b) swap_near_nodes(a, b); else if(b->parent == a) swap_near_nodes(b, a); else swap_far_nodes(a, b); }3.7 Minimum und Maximum
Das Minimum eines Unterbaums findet man indem man einfach den links Zeigern folgt bis man an einem Knoten ohne linken Unterbaum angelangt ist. Ähnlich geht man beim Maximum vor.
private: template<class NodeT> static NodeT*get_min(NodeT*node){ NodeT*now = node; while(now->left) now = now->left; return now; } template<class NodeT> static NodeT*get_max(NodeT*node){ NodeT*now = node; while(now->right) now = now->right; return now; } public: const T&min()const{ return get_min(root)->value; } const T&max()const{ return get_max(root)->value; }3.8 Durchwandern
Um dem Benutzer die Möglichkeit zu geben den Baum zu durchwandern bietet sich der Einsatz von Iteratoren förmlich an. Da ich mich in diesem Artikel allerdings auf die Implementierung des Baum beschränken möchte und nicht eine Schnelleinführung zum Thema Iteratoren geben möchte werde ich nur eine Funktion implementieren die den nächst größeren Wert sucht. next nimmt einen Wert als Parameter und gibt einen Zeiger auf das nächste Element zurück oder ein NULL Zeiger falls der Parameter das Maximum war oder ein Wert der sich gar nicht im Baum befindet. prev ist eine ähnliche Funktion die jedoch das nächst kleinere Element sucht.
private: template<class NodeT> static NodeT*get_next_node(NodeT*now){ if(now->right) return get_min(now->right); else{ while(now){ if(is_left_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Ende angekommen } } template<class NodeT> static NodeT*get_prev_node(NodeT*now){ if(now->left) return get_max(now->left); else{ while(now){ if(is_right_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Anfang angekommen } } public: const T*next(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_next_node(now); if(now) return &now->value; else return 0; } const T*prev(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_prev_node(now); if(now) return &now->value; else return 0; }3.9 Löschen
Das Löschverfahren von Knoten wurde tiefgehend in der Theorie behandelt und darum gibt es nicht viel zur Implementierung zu sagen.
private: void remove(Node*node){ // Ein Blatt if(!node->left && !node->right){ *get_parent_ptr(node) = 0; delete node; } // Nur ein Kind else if(node->left && !node->right){ *get_parent_ptr(node) = node->left; node->left->parent = node->parent; delete node; }else if(!node->left && node->right){ *get_parent_ptr(node) = node->right; node->right->parent = node->parent; delete node; } // Zwei Kinder else{ Node*other = get_prev_node(node); swap_nodes(node, other); // Löschen des Knoten durch benutzen von einer // der beiden anderen Methoden remove(node); } assert(is_wellformed(root)); } public: bool remove(const T&value){ Node*node = search(value); if(node){ remove(node); return true; }else return false; }3.10 Rotationen
Rotationen können sehr viel Stress verursachen bevor sämtliche Zeiger richtig gestellt werden. Darum ist es sehr nützlich den Baum zuerst zu zeichnen: wie er vorher aussieht und danach.


Die Rotationsfunktionen geben einen Zeiger auf die neue Wurzel zurück.
private: Node*rotate_left(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->right, *X = A->left, *Y = B->left, *Z = B->right; *root_ptr = B; B->left = A; B->right = Z; A->left = X; A->right = Y; B->parent = parent; A->parent = B; if(Z) Z->parent = B; if(X) X->parent = A; if(Y) Y->parent = A; return B; }

private: Node*rotate_right(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->left, *X = B->left, *Y = B->right, *Z = A->right; *root_ptr = B; B->left = X; B->right = A; A->left = Y; A->right = Z B->parent = parent; A->parent = B; if(Z) Z->parent = A; if(X) X->parent = B; if(Y) Y->parent = A; return B; }4 Bäume in der STL
Die Spezifikation der STL gibt wie immer keine Implementierung vor, allerdings ist es sehr wahrscheinlich, dass hinter std::set und std::map Bäume am Werk sind.
Wie der Baum eingesetzt wird um std::set umzusetzen sollte eigentlich nach dem Lesen dieses Artikels klar sein da es doch gewaltige Ähnlichkeiten mit der hier entwickelten Baumklasse und std::set gibt. Bei std::map könnte es weniger deutlich sein. Hier weist man jedem Knoten einen Schlüssel und den entsprechenden Wert zu und sortiert den Baum dem Schlüssel entsprechend. Ein Suchen nach dem Schlüssel liefert also auch den Knoten in dem der entsprechende Wert gespeichert ist.
5 Ausblick
In diesem Artikel habe ich gezeigt wie Suchbäume aufgebaut sind und wie sie funktionieren jedoch auch ihre Schwächen. Der Suchbaum so wie er in diesem Artikel beschrieben wird ist recht nutzlos weil er sehr einfach aus dem Gleichgewicht kommt. Um dagegen vorzugehen gibt es verschiedene Ansätze: AVL-Baum, Rot-Schwarz Baum oder Splay-Baum um nur einige zu nennen. Alle haben ihre Stärken und Schwächen. In den nächsten Artikeln wird der hier vorgestellten Baum zu diesen Spezialbäumen umbauen und die Rotationsfunktionen die jetzt noch etwas in der Luft hängen werden ihren Teil dazu beitragen.
-
-
Wow.
")
Also das Inhaltsverzeichnis würde ich drin lassen. Das ist schöner für die, die mal schnell etwas nachschlagen wollen und die, die sich einen groben Überblick holen wollen, was in dem Artikel steht.
Ich finde es schade, dass dein Code so platzsparend formatiert ist.
Wenigtens zwischen Rückgabetyp und Funktionsname wäre ein Leerzeichen nett, den Zeichensalat leserlicher zu machen.
Ich persönlich finde sowasprivate: static std::string format_label(const Node* node) { if (node) { std::ostringstream out; out<<node->value; return out.str(); } return ""; }lesbarer als
private: static std::string format_label(const Node*node){ if(node){ std::ostringstream out; out<<node->value; return out.str(); }else return ""; }Aber das ist persönlicher Stil.
Ansonsten hilft einem Anfänger wohl nur, Zettel und Stift bereitzulegen und nachzumalen, was der Quellcode da tut. Da helfen auch Kommentare wenig. Daher finde ich die jetzt ausreichend.
Wenn jetzt noch alles thematisch korrekt ist und der Code funktioniert, dann gibts ein
 .
.
-
estartu schrieb:
Also das Inhaltsverzeichnis würde ich drin lassen. Das ist schöner für die, die mal schnell etwas nachschlagen wollen und die, die sich einen groben Überblick holen wollen, was in dem Artikel steht.
Dann bleibt es drin. Wäre es vielleicht eine Idee es ans Ende des Artikels zu verfrachten? Ich hab einfach Angst, dass einige Leser das Verzeichnis sehen, das alleine einen ganze Bildschirm füllt und verschreckt sind.
estartu schrieb:
Wenn jetzt noch alles thematisch korrekt ist und der Code funktioniert, dann gibts ein
.Danke
Heute ist mir noch die Idee gekommen vielleicht über die Geschwindigkeit von new und delete zu schreiben und die Verwendung eines Memorypools vorzuschlagen, keine Details. Wäre das sinnvoll oder würde das nur unnötig aufblähen da es direkt nicht mit dem Thema zu tun hat?
Ich bin im Moment dabei den AVL Teil zu überarbeiten und frage mich wie ich die Beweise darstellen soll. Hat da irgendwer eine Idee wie man das besser machen könnte. Latex-tags halte ich für keine gute Idee da diese des öfteren den Dienst verweigern und somit den Artikel unlesbar machen. Wenn Latex dann statische Bilder.
-
Ben04 schrieb:
Wäre es vielleicht eine Idee es ans Ende des Artikels zu verfrachten?
Oder Du nimmst die niedrigen Ebenen aus der Hierarchie aus dem Inhaltsverzeichnis, dann ist es auch nicht mehr so umfangreich.
Heute ist mir noch die Idee gekommen vielleicht über die Geschwindigkeit von new und delete zu schreiben und die Verwendung eines Memorypools vorzuschlagen, keine Details. Wäre das sinnvoll oder würde das nur unnötig aufblähen da es direkt nicht mit dem Thema zu tun hat?
Ich finde sowas immer gut. Ein paar Ausblicke schaden nicht und sie zeigen, dass es da nicht aufhört, wo der Artikel endet. Also immer her damit.
Ich bin im Moment dabei den AVL Teil zu überarbeiten und frage mich wie ich die Beweise darstellen soll. Hat da irgendwer eine Idee wie man das besser machen könnte.
Meine Idee wäre, die Aussagen, die Du benötigst, als Aussage (oder auch Lemma/Satz) zu formulieren und die Beweise dann in einen Anhang zu packen. So wird es ja auch in wissenschaftlichen Einreichungen gemacht, wenn der Platz nicht reicht um alle Beweise in vollen Details reinzunehmen. Außerdem stehen dann die Aussagen und deren Anwendung nah beieinander. Im ersten Schritt glaubt man einfach die Aussagen und sieht dann, dass alles prima funktioniert und wer dann noch Lust hat, der schaut ob die Aussagen auch wirklich richtig sind.
-
Wenn man nicht zu großzügig mit Zeilenumbrüchen in List-Tags ist, kann man das Inhaltsverzeichnis nochmal stauchen.
")
- 1 Suchen das Problem
- 2 Binäre Suchbäume
- 2.1 Suchen
- 2.2 Maximum und Minimum
- 2.3 Durchwandern
- 2.3.1 Knoten mit rechtem Kind
- 2.3.2 Knoten ohne rechtes Kind
- 2.4 Einfügen
- 2.5 Löschen
- 2.5.1 Löschen eines Knoten ohne Kinder
- 2.5.2 Löschen eines Knoten mit einem Kind
- 2.5.3 Löschen eines Knoten mit zwei Kindern
- 2.6 Ausbalancierte Bäume und die die es nicht sind
- 2.7 Rotationen
- 3 Implementierung
- 3.1 Navigation
- 3.2 Debuggen
- 3.2.1 Konsolenausgabe
- 3.2.2 Tod dem Zeigersalat
- 3.3 Kopiekonstruktor, Destruktor und Zuweisung
- 3.4 Suchen
- 3.5 Einfügen
- 3.6 Austauschen
- 3.7 Minimum und Maximum
- 3.8 Durchwandern
- 3.9 Löschen
- 3.10 Rotationen
- 4 Bäume in der STL
- 5 Ausblick
-
Damit wäre das Problem gelöst. (Könnte das Forum aber auch selber machen...)
===
3.11 Tunen von new und delete
Bäume spielen ihren Vorteil gegenüber alternativen Datenstrukturen vor allem aus wenn es viele Elemente gibt doch auch bei kleinen Listen sind sie nicht hoffnungslos Unterlegen. Wenn es nur sehr wenige Elemente gibt dann wird nichts in der Liga einfacher Arrays spielen können jedoch gilt es so nahe ran zu kommen wie möglich. Bei kleinen Bäumen fällte die Zeit die durch die Speicherverwaltung, das heißt direkt in new und delete, verbracht wird, viel mehr ins Gewicht und darum bietet es sich an hier was zu tun. Da sämtliche Knoten die gleiche Größe haben kann der Einsatz von Memory Pools Wunder wirken. Bei großen Bäumen ist ihr Einsatz sicherlich nicht verkehrt auch wenn der Gewinn proportional gesehen kleiner ausfallen wird. Zum Nachteil wird der Einsatz von Pools eigentlich so gut wie nie.
-
Ich hab noch ein paar Fehler im Code gefunden und hab noch eine Experimentier-Konsole hinzugefügt. Ich hab den Code nur mit MinGW und VC Express getestet. Könntet ihr bitte andere Compiler testen und sehe ob die irgendwelche Probleme machen. Bitte auch Warnungen posten.
Ich hab nicht vor noch etwas zu ändern aber vielleicht findet irgendwer ja noch einen Fehler. Falls keine Fehler mehr auftauchen werde ich den Artikel in ein paar Tagen auf [R] setzen.
==================
Inhaltsverzeichnis
- 1 Suchen das Problem
- 2 Binäre Suchbäume
- 2.1 Suchen
- 2.2 Maximum und Minimum
- 2.3 Durchwandern
- 2.3.1 Knoten mit rechtem Kind
- 2.3.2 Knoten ohne rechtes Kind
- 2.4 Einfügen
- 2.5 Löschen
- 2.5.1 Löschen eines Knoten ohne Kinder
- 2.5.2 Löschen eines Knoten mit einem Kind
- 2.5.3 Löschen eines Knoten mit zwei Kindern
- 2.6 Ausbalancierte Bäume und die die es nicht sind
- 2.7 Rotationen
- 3 Implementierung
- 3.1 Navigation
- 3.2 Debuggen
- 3.2.1 Konsolenausgabe
- 3.2.2 Tod dem Zeigersalat
- 3.3 Kopiekonstruktor, Destruktor und Zuweisung
- 3.4 Suchen
- 3.5 Einfügen
- 3.6 Austauschen
- 3.7 Minimum und Maximum
- 3.8 Durchwandern
- 3.9 Löschen
- 3.10 Rotationen
- 3.11 Tunen von new und delete
- 3.12 Download und Experimentierkonsole
- 4 Bäume in der STL
- 5 Ausblick
1 Suchen das Problem
Sei es eine Datenbank oder ein Dateisystem: Das Suchen nach Werten ist eines der häufigsten Probleme in der Informatik. Das im Grunde einfach klingende Problem erweist sich als ein außerordentlich komplexes Biest sobald man über den Tellerrand der trivialen Ansätze blickt.
Für viele Anwendungen recht ein Array in das man sämtliche Werte rein schmeißt und anschließend von Anfang bis Ende durchläuft. Wenn die Datenbank aber wächst dann wird dieser Ansatz aber unvertretbar langsam. Der erste Verbesserungsvorschlag wird dann wohl sein das Array zu sortieren und es dann mit der Hilfe einer binären Suche zu durchwühlen. Solange sich die Element des Arrays nur wenig verändert ist dieser Ansatz gut andernfalls stößt auch er an seine Grenzen.
Wer noch mehr Geschwindigkeit braucht der muss sich vom einfachen Array verabschieden und auf eine andere Datenstruktur ausweichen. Ein Ansatz ist die Werte in einer Hash-Tabelle zu speichern. Diese sind in manchen Anwendungen kaum zu überbieten. Aber auch sie haben ihre Schwächen wenn die Anzahl der Elemente unerwartete Größen annimmt. Desweiteren schneiden sie schlecht ab wenn man mehr tuen will als nur Suchen wie zum Beispiel der iterative Zugriff auf die Elemente. Ist die Tabelle zu groß so wird es ewig dauern sie zu durchforsten um sämtliche Elemente wieder zu finden.
Hash-Tabelle werden aber nicht das Thema dieses Artikels sein, vielmehr wird es eine Weiterentwickelung der binären Suche sein: Der binäre Suchbaum. Dieser passt sich hervoragend einer großen Anzahl von Elementen an und erlaubt es die Element sogar sortiert aufzulisten.
2 Binäre Suchbäume
In einem Suchbaum weist man jedem Knoten ein Element zu und sorgt dafür, dass alle Elemente des linken Unterbaums kleiner und die des rechten Unterbaums größer sind.
2.1 Suchen
Um ein Element zu suchen beginnt man die Suche an der Wurzel. Falls die Wurzel den gesuchten Wert darstellt ist man schon fertig. Sonst vergleicht man ob der dieser kleiner oder größer ist und setzt seine Suche im entsprechenden Unterbaum fort. Wenn man auf der untersten Ebene des Baums angelangt ist ohne den Wert gefunden zu haben dann ist er nicht im Baum enthalten.
In folgendem Beispiel wird die 7 gesucht.
Um ein Element zu finden müssen wir im schlimmsten Fall von der Wurzel bis zur untersten Ebene wandern. Im besten Fall hat der Baum eine Höhe die logarithmisch von der Anzahl seiner Elemente abhängt. Dies gibt also in etwa eine Laufzeitkomplexität von O(log(n)) um ein Element zu suchen wenn wir ungünstige Bäume ignorieren. n ist die Gesamtanzahl der Elemente im Baum.
2.2 Maximum und Minimum
Da die Elemente geordnet im Baum vorliegen ist das kleinste Element das was sich am linken Ende des Baums befindet. Man findet es indem man die Suche an der Wurzel beginnt und sie dann nach links fort setzt bis man an einem Knoten angelangt welcher keinen linken Unterbaum mehr hat. Das größte Element findet man ähnlich, nur dass man nach rechts wandern muss.
Im schlimmsten Fall müssen wir den Baum von oben nach unten durchwandern also ist die Laufzeitkomplexität dieselbe wie die bei der Suche eines Elements das heißt O(log(n)).
2.3 Durchwandern
Um die Elemente eines Baums in geordneter Reihenfolge zu durchwandern beginnt man seine Suche beim Minimum und sucht dann immer das nächste größere Element, bis dass man beim Maximum angelangt ist.
Wie man zum nachfolgenden Knoten im Baum gelangt hängt von der Position im Baum ab von der man startet. Genauer gesagt hängt es davon ab ob der Ausgangsknoten ein rechtes Kind besitzt oder nicht.
2.3.1 Knoten mit rechtem Kind
Falls es einen rechten Unterbaum gibt so ist das nächste Element das Minimum dieses Unterbaums.
In folgendem Beispiel suchen wir das Element das der 5 folgt. Dazu begeben wir uns zuerst in den rechten Unterbaum und dann suchen wir das Minimum indem wir solange nach links wandern wie nur möglich.
2.3.2 Knoten ohne rechtes Kind
Sollte es kein rechtes Kind geben, so muss man Richtung Wurzel des Baums klettern. Falls man unterwegs auf einen Knoten stößt welchen man von seinem linken Kind aus erreicht hat so hat man das nächste Element gefunden.
Der Algorithmus um den Baum vom Maximum zum Minimum zu durchwandern ist genau spiegelverkehrt und darum werde ich nicht weiter auf ihn eingehen.
Beim durchwandern des gesamten Baums wird jede Kante genau zweimal begangen wenn man das Bestimmen des Minimum und Maximum hinzuzählt. Da es nur einen Knoten mehr gibt als Kanten hat das Durchwandern eine Laufzeitkomplexität von O(n). Um das nächste Element zu finden muss man im schlimmsten Fall von der untersten Ebene bis zur Wurzel oder andersherum wandern. Diese hat Operation hat also eine Laufzeitkomplexität von O(log(n)) im ungünstigsten Fall ist aber meisten wesentlich besser.
Es gibt einen alternativen Ansatz der die Knoten noch zusätzlich zum Baum in einer geordneten verketteten Liste zusammen strikt. Dies beschleunigt das Durchwandern um einen konstanten Faktor und sorgt dafür, dass das Bestimmen des nächsten Elements immer eine konstante Laufzeit besitzt. Der Preis ist allerdings der Mehraufwand um die verkettete Liste zu verwalten. Falls man den Baum oft durchwandern muss sollte man diese Option in betracht ziehen.
2.4 Einfügen
Um einen Wert einzufügen geht man ähnlich vor wie bei der normalen Suche. Man wandert solange nach unten, bis man einen Knoten gefunden hat der noch ein Kind, an der richtigen Seite, frei hat.
In folgendem Beispiel wird die 8 eingefügt.
Da es sich im wesentlichen um den gleichen Algorithmus handelt wie bei der Suche ist auch die Komplexität die gleiche und zwar O(log(n)).
2.5 Löschen
Als erstes sucht man den zu löschenden Knoten nach bekannter Methode. Wie man danach vorgeht hängt von der Position des Knoten im Baum ab, das heißt wie viele Kinder der Knoten hat.
2.5.1 Löschen eines Knoten ohne Kinder
Um ein Blatt zu löschen trennt man es einfach vom Elternknoten ab.
Folgendes Beispiel zeigt wie die 5 aus dem Baum gelöscht wird:
2.5.2 Löschen eines Knoten mit einem Kind
Falls es es nur ein Kind gibt so wandert dieses den Platz des Knoten. Man trennt den zu löschenden Knoten von Kind- und Elternknoten und verbindet danach diese zwei.
Im nächsten Beispiel wird die 3 gelöscht.
2.5.3 Löschen eines Knoten mit zwei Kindern
Ein Knoten mit zwei Kinder lässt sich nicht einfach löschen. Wer aber leicht gelöscht werden kann ist das vorhergehende oder nachfolgende Element. Bei beiden handelt es sich nämlich um das Maximum respektiv dem Minimum des linken beziehungsweise rechten Unterbaums. Aus diesem Grund haben sie höchstens ein Kind und können daher mit einem der beiden oben genannten Methoden gelöscht werden.
Ob man sich für das nachfolgende oder vorhergehende Element entscheidet spielt keine große Rolle. Keine der beiden Optionen hat einen wirklichen Vorteil oder Nachteil.
In folgendem Beispiel wird die 7 gelöscht.
Manche Leser werden sich an diesem Punkt vielleicht fragen ob es denn immer ein nachfolgendes und vorhergehendes Element gibt. Es könnte ja sein, dass man den Auftrag erhalten hat das erste oder letzte Element zu löschen. Da es sich bei beiden allerdings um ein Minimum oder Maximum handelt können sie keine zwei Kinder besitzen und daher ist ein Austauschen gar nicht erst nötig.
Die Geschwindigkeit der eigentlichen Löschverfahren sind alle unabhängig von der Größe des Baums. Legendlich die Suche des zu löschenden Elements und das Bestimmen des nachfolgenden oder vorhergehenden Elements hängen von der Größe ab, darum ist die Komplexität einer Löschoperation in etwa O(log(n)).
2.6 Ausbalancierte Bäume und die die es nicht sind
Eines der großen Probleme solcher Bäume ist, dass wenn die Reihenfolge der Einfügungen ungünstig ist der Baum sehr schnell aus dem Gleichgewicht kommt und zu einer Seite hinkt. Dies macht den Baum sehr viel höher als nötig und somit die Suche viel langsamer da diese ja von der Höhe des Baums abhängt.
In folgendem Baum wird die 8 gesucht und der Arbeitsaufwand kommt schon nahe an den einer sequenziellen Suche heran.
Um dem entgegen zu wirken kann man Rotationen einsetzen.
2.7 Rotationen
Es gibt Rotationen nach links und nach rechts. Da beide Operationen genau spiegelverkehrt sind werde ich nur auf die links Rotation eingehen.
Als erstes trennt man das linke Kind vom rechten Kind der Wurzel ab und anschießend auch das rechte Kind.
Danach wird das rechte Kind zur neuen Wurzel und die alte Wurzel wird ihr neues rechtes Kind. Das Enkelkind wird zum neuen rechten Kind der alten Wurzel.
Nun ist der Baum wieder im Gleichgewicht.
Man sagt links Rotation da das Gleichgewicht sich nach links verlagert. Man kann es sich wie eine Balkenwaage vorstellen welche man in das Gleichgewicht bringt indem man den Balken an einer anderen Stelle aufhängt.
Das Beispiel hinkt zwar da nach der Rotation beide Gewichte gleich schwer sind.
Die Geschwindigkeit einer Rotation hängt nicht von der Größe des Baums ab. Die Komplexität ist also O(1).
Das große Problem von Rotationen ist zu wissen wann man sie einsetzen soll. Sie verbessern nämlich nicht immer das Gleichgewicht eines Baums wie folgendes Beispiel zeigt.
Es gibt verschiedene Strategien um hier vorzugehen. Keine ist allerdings wirklich trivial und verdienen alle ihren eigenen Artikel. Da alle aber Rotationen nutzen hab ich sie bereits jetzt eingeführt damit nicht jeder Artikel diese Operation neu beschreiben muss und direkt mit dem wirklich interesanten Teil beginnen kann. Ich werde in diesem Artikel nicht weiter auf ihre Verwendung eingehen.
3 Implementierung
Das erste was man bei einer Implementierung festlegen muss ist die Darstellung. Die Knoten werden durch eine Struktur dargestellt und dann mit Pointern verbunden. Dies sieht in etwa so aus:
template<class T> struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} };parent zeigt auf den Elternknoten. Falls es sich um die Wurzel handelt ist dieser NULL. left und right zeigen jeweils auf die Wurzel des linken oder rechten Unterbaums oder NULL falls es diesen nicht gibt.
Um zu verhindern, dass Unbefugte an unserem Baum rumbasteln wird dieser durch eine Klasse gekapselt. Dies sieht dann in etwa folgendermaßen aus:
template<class T> class Tree{ private: struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} }; Node*root; public: Tree():root(0){} bool is_empty()const{ return !root; } };root zeigt dabei auf die Wurzel des Baumes oder NULL falls der Baum leer ist. Ob der Baum leer ist kann mittels is_empty überprüft werden.
Es gibt Variationen in denen die Knoten keinen Zeiger auf den Elternknoten besitzen. Dies spart Speicher und erleichtert die Verwaltung der zusätzlichen Zeiger jedoch macht es auch die Implemenierung mancher Operationen wie zum Beispiel des Durchwandern komplizierter. Oft sind diese nur noch durch den Einsatz eines Stacks oder von Rekurivität überhaupt möglich. Welche Option nun die beste ist hängt von Einsatzfall ab.
Manche Leser werden vielleicht auch auf den Gedanken gekommen sein die Elemente in einem Array abzulegen und das Navigieren durch Multiplizieren der Indexe mit 2 abzuwickeln. Für manche Bäume ist dies sicherlich ein sinnvoll Ansatz wie zum Beispiel Heaps wie man in Jesters Artikel dazu nachlesen kann. Für Suchbäume ist dieser Ansatz aber unbrauchbar da Rotationen sich nur sehr schwer implementieren lassen und unausbalancierte Bäume in dieser Darstellung echte Speicherfresser sind.
3.1 Navigation
Um uns beim navigieren im Baum zu helfen schreiben wir uns Funktionen die prüfen ob es sich um ein linkes oder rechtes Kind handelt.
private: static bool is_left_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->left == node; } static bool is_right_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->right == node; }Um die Position eines Knoten ändern zu können muss man auch einen einfachen Zugriff auf den Zeiger im Elternknoten haben. Dies bietet folgende Funktion:
private: Node**get_parent_ptr(Node*node){ if(node->parent == 0) return &root; else if(is_left_child(node)) return &node->parent->left; else return &node->parent->right; }3.2 Debuggen
Da es sehr schwer ist einen Baum fehlerfrei zu implementieren müssen wir uns auch Gedanken machen wie wir ihn debuggen. Wer sich nur für den eigentlichen Code interessiert kann diesen Teil des Artikels getrost überspringen.
3.2.1 Konsolenausgabe
Eine Funktion die den Baum einfach komplett auf die Konsole ausgibt wäre sehr nützlich da die meisten Debugger nicht sonderlich gut sind um solche Datenstrukturen zu inspizieren und nur Zeigersalat anzeigen.
Ziel ist es den Baum ähnlich wie auf den Grafiken oben auszugeben. Dazu müssen wir als erstes festlegen welche Informationen über einen Knoten ausgegeben werden. Dies macht folgende Funktion:
private: static std::string format_label(const Node*node){ if(node){ std::ostringstream out; out<<node->value; return out.str(); }else return ""; }Wir müssen auch wissen wie breit und hoch der Baum wird damit wir wissen wie viel Platz frei gelassen werden muss. Folgende Funktionen berechnen diese Informationen für den Baum und jeden Unterbaum.
private: static unsigned get_height(const Node*node){ if(!node) return 0; unsigned left_height = 0, right_height = 0; if(node->left) left_height = get_height(node->left); if(node->right) right_height = get_height(node->right); // Der höchste Unterbaum bestimmt die Gesamthöhe return std::max(left_height, right_height) + 1; } static unsigned get_width(const Node*node){ if(!node) return 0; unsigned left_width = 0, right_width = 0; if(node->left) left_width = get_width(node->left); if(node->right) right_width = get_width(node->right); return left_width + format_label(node).length() + right_width; }Da wir nur zeilenweise auf die Konsole schreiben können müssen wir den Baum auch Zeile für Zeile ausgeben.
private: static void dump_spaces(std::ostream&out, unsigned count){ for(unsigned i=0; i<count; ++i) out.put(' '); } static void dump_line(std::ostream&out, const Node*node, unsigned line){ if(!node) return; if(line == 1){ // Die Wurzel des Unterbaums soll ausgegeben werden dump_spaces(out, get_width(node->left)); out<<format_label(node); dump_spaces(out, get_width(node->right)); }else{ // In beiden Unterbäumen sind die Wurzeln um eins niedriger und darum verändert // sich die Zeilennumerirung. dump_line(out, node->left, line-1); dump_spaces(out, format_label(node).length()); dump_line(out, node->right, line-1); } }Nun benötigen wir noch eine Möglichkeit den gesamten Baum auszugeben und nicht nur eine Zeile.
private: static void dump_node(std::ostream&out, const Node*node){ for(unsigned line=1, height = get_height(node); line <= height; ++line){ dump_line(out, node, line); out.put('\n'); } out.flush(); } public: void dump(std::ostream&out)const{ dump_node(out, root); }Mit der Hilfe der dump Funktion können wir nun den Baum für den Menschen lesbar anzeigen. Eine mögliche Ausgabe wäre:
6 3 10 1 5 7 12Man könnte den Ausgabealgorithmus sicher noch sehr viel verbessern was die Geschwindigkeit betrifft. Ich glaube jedoch kaum, dass er bei großen Bäumen überhaupt zum Einsatz kommen wird und deshalb werde ich dies sein lassen.
3.2.2 Tod dem Zeigersalat
Bei dem Implementieren von Bäumen wird man oft Zeigern die nicht dahin zeigen wo sie eigentlich sollten. Eine Funktion die testet ob der Baum so überhaupt richtig sein kann hilft viele Fehler zu finden. Man testet zum Beispiel ob der Elternknoten des Kindes eines Knoten dieser selbst ist.
private: bool is_wellformed(Node*node){ if(node == 0) return true; if(*get_parent_ptr(node) != node) return false; if(!is_wellformed(node->left)) return false; if(!is_wellformed(node->right)) return false; return true; }Mit Hilfe eines assert(is_wellformed(root)) können sehr viele Fehler vorzeitig abgefangen werden. Durch ein Paar geschickte gesetzte Breakpoints innerhalb dieser Funktion kann man auch sehr genau erfahren welcher Zeiger falsch ist.
3.3 Kopiekonstruktor, Destruktor und Zuweisung
Da ein Baum keine triviale Datenstruktur ist muss man auch den Kopiekonstruktor, den Destruktor und den Zuweisungsoperator implementieren.
Als erstes implementiere ich den Destruktor. Dieser ist leicht rekursive zu realisieren.
private: static void destroy_node(Node*node){ if(node){ destroy_node(node->left); destroy_node(node->right); delete node; } } public: ~Tree(){ destroy_node(root); }Bei sehr großen Bäumen kann es bei diesem Destruktor zu einem Stapelüberlauf kommen. In diesem Fall muss man ihn iterative formulieren. Die Idee ist immer das Blatt zu löschen das den kleinsten Wert aller Blätter darstellt also sich auf der linken Seite des Baums befindet. Durch das Abschneiden der ersten Blätter entstehen neue und der Baum schrumpft zusammen, bis dass er schlussendlich nicht mehr existiert.
~Tree(){ Node*now = root; while(now){ if(now->left) now = now->left; else if(now->right) now = now->right; else{ Node*next = now->parent; *get_parent_ptr(now) = 0; delete now; now = next; } } }Der Kopiekonstruktor kann auch rekursive implementiert werden man muss jedoch aufpassen ob eine Ausnahme fliegt oder nicht. Dies wird schnell unübersichtlich und fehleranfällig. Darum bevorzuge ich die iterative Version. Die Idee ist den alten und neuen Baum so zu durchlaufen wie wir es im Destruktor tun und dabei alle Knoten klonen welche im alten Baum vorhanden sind jedoch nicht im neuen.
Mit dieser Methode ist der Baum immer in einem gesunden Zustand und kann vom Destruktor auch im unvollendeten Zustand gelöscht werden. Falls eine Ausnahme fliegt brauchen wir nur den Destruktor mit der Arbeit zu beauftragen den halbfertigen Baum zu löschen.
Tree(const Tree&other){ if(other.is_empty()) root = 0; else{ root = new Node(other.root->value); try{ Node *now = root, *other_now = other.root; while(other_now){ if(other_now->left && !now->left){ now->left = new Node(other_now->left->value); now->left->parent = now; now = now->left; other_now = other_now->left; }else if(other_now->right && !now->right){ now->right = new Node(other_now->right->value); now->right->parent = now; now = now->right; other_now = other_now->right; }else{ now = now->parent; other_now = other_now->parent; } is_wellformed(root); } }catch(...){ this->~Tree(); throw; } } }Der Zuweisungs-Operator kann leicht mit Hilfe des Copy&Swap-Idioms implementiert werden.
public: void swap(Tree&other){ std::swap(root, other.root); } Tree&operator=(const Tree&other){ Tree temp(other); swap(temp); return *this; }3.4 Suchen
Implementieren wir nun die Suchfunktion. Da wir die innere Struktur der Klasse verstecken wollen stellen wir dem Außenstehenden nur eine Funktion zur Verfügung die testet ob ein Wert im Baum enthalten ist.
Man sollte bemerken, dass man es dem Benutzer nicht erlauben sollte den Wert des Knoten zu verändert, da dies die Position im Baum durcheinander bringen kann. Falls er dies beabsichtig, dann soll er den alten Wert rauslöschen und den neuen einfügen damit sich das Element an der richtigen Stelle befindet.
Durch den Einsatz von Templates spare ich mir eine const und eine nicht-const Version zu schreiben.
private: template<class NodeT> static NodeT*search(NodeT*root, const T&value){ NodeT*now = root; while(now){ if(value < now->value) now = now->left; else if(now->value < value) now = now->right; else return now; } return 0; } public: bool contains(const T&t)const{ return search(root, t); }3.5 Einfügen
Um ein Element einzufügen verfahren wir ähnlich jedoch behalten wir uns wo sich der Elternknoten befindet.
public: bool insert(const T&value){ Node *parent = 0, *now = root; bool is_left_child = false; while(now){ parent = now; if(value < now->value){ is_left_child = true; now = now->left; }else if(now->value < value){ is_left_child = false; now = now->right; }else return false; // Das Element ist bereits im Baum } Node*new_node = new Node(value); new_node->parent = parent; if(parent == 0) root = new_node; else if(is_left_child) parent->left = new_node; else parent->right = new_node; // Wenn etwas mit den Zeigern falsch ist // dann knallt es wahrscheinlich hier. assert(is_wellformed(root)); return true; }3.6 Austauschen
Knoten können durch austauschen der Werte getauscht werden. Dies ist sicherlich der beste Weg falls man Ganzzahlen speichern will. Es gibt jedoch auch Klassen welche sehr teuer zu tauschen sind oder die gar nicht getauscht werden können. Es ist auch möglich, dass es Zeiger auf das Element gibt die außerhalb des Baums liegen und verändert werden müssten, oder dass beim Tauschen eine Ausnahme fliegen kann. Diese Probleme kann man dadurch umgehen, dass man die Zeiger der Knoten neuverbindet. Hierbei ist der allgemeine Fall vom Fall wo einer der beiden Knoten das Kind des anderen ist zu unterscheiden.
Man sollte beachten, dass das Tauschen von Knoten wahrscheinlich die Ordnung im Baum durcheinander bringt. Es sollte also sicher gestellt sein, dass diese nachdem diese Funktion ihre Arbeit getan hat wiederhergestellt wird.
private: void swap_near_nodes(Node*child, Node*parent){ // Als erstes passen wir den unbeteiligten Großelternknoten an. *get_parent_ptr(parent) = child; // Anschließend werden die Kind- und Elternzeiger ausgetauscht. std::swap(parent->left, child->left); std::swap(parent->right, child->right); std::swap(parent->parent, child->parent); // Da eines der Kinder getauscht wird benötigt es eine // sonder Behandlung. if(child->left == child) child->left = parent; else child->right = parent; // Nun sind alle Kindzeiger richtig und die Elternzeiger können // dem angepasst werden. if(child->left) child->left->parent = child; if(child->right) child->right->parent = child; if(parent->left) parent->left->parent = parent; if(parent->right) parent->right->parent = parent; // Na wer ist sich noch sicher ob wir nicht // bereits Zeigersalat haben? Besser testen! assert(is_wellformed(root)); } void swap_far_nodes(Node*a, Node*b){ // Zuerst updaten wir die Zeiger der Eltern *get_parent_ptr(a) = b; *get_parent_ptr(b) = a; // Danach der Kinder if(a->left) a->left->parent = b; if(a->right) a->right->parent = b; if(b->left) b->left->parent = a; if(b->right) b->right->parent = a; // Und als letztes die der beiden Knoten std::swap(a->left, b->left); std::swap(a->right, b->right); std::swap(a->parent, b->parent); assert(is_wellformed(root)); } void swap_nodes(Node*a, Node*b){ if(a->parent == b) swap_near_nodes(a, b); else if(b->parent == a) swap_near_nodes(b, a); else swap_far_nodes(a, b); }3.7 Minimum und Maximum
Das Minimum eines Unterbaums findet man indem man einfach den links Zeigern folgt bis man an einem Knoten ohne linken Unterbaum angelangt ist. Ähnlich geht man beim Maximum vor.
private: template<class NodeT> static NodeT*get_min(NodeT*node){ NodeT*now = node; while(now->left) now = now->left; return now; } template<class NodeT> static NodeT*get_max(NodeT*node){ NodeT*now = node; while(now->right) now = now->right; return now; } public: const T&min()const{ return get_min(root)->value; } const T&max()const{ return get_max(root)->value; }3.8 Durchwandern
Um dem Benutzer die Möglichkeit zu geben den Baum zu durchwandern bietet sich der Einsatz von Iteratoren förmlich an. Da ich mich in diesem Artikel allerdings auf die Implementierung des Baum beschränken möchte und nicht eine Schnelleinführung zum Thema Iteratoren geben möchte werde ich nur eine Funktion implementieren die den nächst größeren Wert sucht. next nimmt einen Wert als Parameter und gibt einen Zeiger auf das nächste Element zurück oder ein NULL Zeiger falls der Parameter das Maximum war oder ein Wert der sich gar nicht im Baum befindet. prev ist eine ähnliche Funktion die jedoch das nächst kleinere Element sucht.
private: template<class NodeT> static NodeT*get_next_node(NodeT*now){ if(now->right) return get_min(now->right); else{ while(now){ if(is_left_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Ende angekommen } } template<class NodeT> static NodeT*get_prev_node(NodeT*now){ if(now->left) return get_max(now->left); else{ while(now){ if(is_right_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Anfang angekommen } } public: const T*next(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_next_node(now); if(now) return &now->value; else return 0; } const T*prev(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_prev_node(now); if(now) return &now->value; else return 0; }3.9 Löschen
Das Löschverfahren von Knoten wurde tiefgehend in der Theorie behandelt und darum gibt es nicht viel zur Implementirung zu sagen.
private: void remove(Node*node){ // Ein Blatt if(!node->left && !node->right){ *get_parent_ptr(node) = 0; delete node; } // Nur ein Kind else if(node->left && !node->right){ *get_parent_ptr(node) = node->left; node->left->parent = node->parent; delete node; }else if(!node->left && node->right){ *get_parent_ptr(node) = node->right; node->right->parent = node->parent; delete node; } // Zwei Kinder else{ Node*other = get_prev_node(node); swap_nodes(node, other); // Löschen des Knoten durch benutzen von einer // der beiden anderen Methoden remove(node); } assert(is_wellformed(root)); } public: bool remove(const T&value){ Node*node = search(root, value); if(node){ remove(node); return true; }else return false; }3.10 Rotationen
Rotationen können sehr viel Stress verursachen bevor sämtliche Zeiger richtig gestellt werden. Darum ist es sehr nützlich den Baum zuerst zu zeichnen : wie er vorher aussieht und danach.
Die Rotationsfunktionen geben einen Zeiger auf die neue Wurzel zurück.
private: Node*rotate_left(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->right, *X = A->left, *Y = B->left, *Z = B->right; *root_ptr = B; B->left = A; B->right = Z; A->left = X; A->right = Y; B->parent = parent; A->parent = B; if(Z) Z->parent = B; if(X) X->parent = A; if(Y) Y->parent = A; return B; } private: Node*rotate_right(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->left, *X = B->left, *Y = B->right, *Z = A->right; *root_ptr = B; B->left = X; B->right = A; A->left = Y; A->right = Z; B->parent = parent; A->parent = B; if(Z) Z->parent = A; if(X) X->parent = B; if(Y) Y->parent = A; return B; }3.11 Tunen von new und delete
Bäume spielen ihren Vorteil gegenüber alternativen Datenstrukturen vor allem aus wenn es viele Elemente gibt doch auch bei kleinen Listen sind sie nicht hoffnungslos Unterlegen. Wenn es nur sehr wenige Elemente gibt dann wird nichts in der Liga einfacher Arrays spielen können jedoch gilt es so nahe wie möglich ran zu kommen. Bei kleinen Bäumen fällte die Zeit die durch die Speicherverwaltung, das heißt direkt in new und delete, verbracht wird, viel mehr ins Gewicht und darum bietet es sich an hier was zu tun. Da sämtliche Knoten die gleiche Größe haben kann der Einsatz von Memory Pools Wunder wirken. Bei großen Bäumen ist ihr Einsatz sicherlich nicht verkehrt auch wenn der Gewinn proportional gesehen kleiner ausfallen wird. Zum Nachteil wird der Einsatz von Pools eigentlich so gut wie nie.
3.12 Download und Experimentierkonsole
Die Implementierung gibt es auch fertig in einer Datei verpackt um das Herumexperimentieren zu erleichtern. Neben dem eigentlichen Baum ist auch eine Konsole enthalten mit deren Hilfe man die einzelnen Funktionen in Aktion sehen kann. Alles was zum Übersetzen benötigt wird ist ein Standard konformer Compiler.
4 Bäume in der STL
Die Spezifikation der STL gibt wie immer keine Implementierung vor, allerdings ist es sehr wahrscheinlich, dass hinter std::set und std::map Bäume am Werk sind.
Wie der Baum eingesetzt wird um std::set umzusetzen sollte eigentlich nach dem Lesen dieses Artikels klar sein da es doch gewaltige Ähnlichkeiten mit der hier entwickelten Baumklasse und std::set gibt. Bei std::map könnte es weniger deutlich sein. Hier weist man jedem Knoten einen Schlüssel und den entsprechenden Wert zu und sortiert den Baum dem Schlüssel entsprechend. Ein Suchen nach dem Schlüssel liefert also auch den Knoten in dem der entsprechende Wert gespeichert ist.
5 Ausblick
In diesem Artikel habe ich gezeigt wie Suchbäume aufgebaut sind und wie sie funktionieren jedoch auch ihre Schwächen. Der Suchbaum so wie er in diesem Artikel beschrieben wird ist recht nutzlos weil er sehr einfach aus dem Gleichgewicht kommt. Um dagegen vorzugehen gibt es verschiedene Ansätze: AVL-Baum, Rot-Schwarz Baum oder Splay-Baum um nur einige zu nennen. Alle haben ihre Stärken und Schwächen. In den nächsten Artikeln wird der hier vorgestellten Baum zu diesen Spezialbäumen umbauen und die Rotationsfunktionen die jetzt noch etwas in der Luft hängen werden ihren Teil dazu beitragen.
-
Ich hab den Artikel jetzt auf [R] gesetzt. Ich hoffe jemand findet die Zeit das ganze auf Rechtschreibfehler zu prüfen. Im Download gibt es auch noch ein paar Kommentare drin. Danke in voraus.
-
Inhaltsverzeichnis
- 1 Suchen - das Problem
- 2 Binäre Suchbäume
- 2.1 Suchen
- 2.2 Maximum und Minimum
- 2.3 Durchwandern
- 2.3.1 Knoten mit rechtem Kind
- 2.3.2 Knoten ohne rechtes Kind
- 2.4 Einfügen
- 2.5 Löschen
- 2.5.1 Löschen eines Knoten ohne Kinder
- 2.5.2 Löschen eines Knoten mit einem Kind
- 2.5.3 Löschen eines Knoten mit zwei Kindern
- 2.6 Ausbalancierte Bäume und die, die es nicht sind
- 2.7 Rotationen
- 3 Implementierung
- 3.1 Navigation
- 3.2 Debuggen
- 3.2.1 Konsolenausgabe
- 3.2.2 Tod dem Zeigersalat
- 3.3 Kopierkonstruktor, Destruktor und Zuweisung
- 3.4 Suchen
- 3.5 Einfügen
- 3.6 Austauschen
- 3.7 Minimum und Maximum
- 3.8 Durchwandern
- 3.9 Löschen
- 3.10 Rotationen
- 3.11 Tunen von new und delete
- 3.12 Download und Experimentierkonsole
- 4 Bäume in der STL
- 5 Ausblick
1 Suchen - das Problem
Sei es eine Datenbank oder ein Dateisystem: Das Suchen nach Werten ist eines der häufigsten Probleme in der Informatik. Das im Grunde einfach klingende Problem erweist sich als ein außerordentlich komplexes Biest, sobald man über den Tellerrand der trivialen Ansätze blickt.
Für viele Anwendungen reicht ein Array, in das man sämtliche Werte reinschmeißt und anschließend von Anfang bis Ende durchläuft. Wenn die Datenbank aber wächst, dann wird dieser Ansatz unvertretbar langsam. Der erste Verbesserungsvorschlag wird dann wohl sein, das Array zu sortieren und es dann mit der Hilfe einer binären Suche zu durchwühlen. Solange sich die Elemente des Arrays nur wenig verändern, ist dieser Ansatz gut, andernfalls stößt auch er an seine Grenzen.
Wer noch mehr Geschwindigkeit braucht, der muss sich vom einfachen Array verabschieden und auf eine andere Datenstruktur ausweichen. Ein Ansatz ist, die Werte in einer Hash-Tabelle zu speichern. Diese sind in manchen Anwendungen kaum zu überbieten. Aber auch sie haben ihre Schwächen, wenn die Anzahl der Elemente unerwartete Größen annimmt. Des Weiteren schneiden sie schlecht ab, wenn man mehr tun will, als nur Suchen, wie zum Beispiel der iterative Zugriff auf die Elemente. Ist die Tabelle zu groß, so wird es ewig dauern, sie zu durchforsten, um sämtliche Elemente wieder zu finden.
Hash-Tabelle***n*** werden aber nicht das Thema dieses Artikels sein, vielmehr wird es eine Weiterentwicklung der binären Suche sein: Der binäre Suchbaum. Dieser passt sich hervorragend einer großen Anzahl von Elementen an und erlaubt es, die Element***e*** sogar sortiert aufzulisten.
2 Binäre Suchbäume
In einem Suchbaum weist man jedem Knoten ein Element zu und sorgt dafür, dass alle Elemente des linken Unterbaums kleiner und die des rechten Unterbaums größer sind.
2.1 Suchen
Um ein Element zu suchen, beginnt man die Suche an der Wurzel. Falls die Wurzel den gesuchten Wert darstellt, ist man schon fertig. Sonst vergleicht man, ob dieser kleiner oder größer ist und setzt seine Suche im entsprechenden Unterbaum fort. Wenn man auf der untersten Ebene des Baums angelangt ist, ohne den Wert gefunden zu haben, dann ist er nicht im Baum enthalten.
In folgendem Beispiel wird die 7 gesucht.
Um ein Element zu finden, müssen wir im schlimmsten Fall von der Wurzel bis zur untersten Ebene wandern. Im besten Fall hat der Baum eine Höhe die logarithmisch von der Anzahl seiner Elemente abhängt. Dies gibt also in etwa eine Laufzeitkomplexität von O(log(n)), um ein Element zu suchen, wenn wir ungünstige Bäume ignorieren. n ist die Gesamtanzahl der Elemente im Baum.
2.2 Maximum und Minimum
Da die Elemente geordnet im Baum vorliegen, ist das kleinste Element das, was sich am linken Ende des Baums befindet. Man findet es, indem man die Suche an der Wurzel beginnt und sie dann nach links fortsetzt bis man an einem Knoten angelangt, welcher keinen linken Unterbaum mehr hat. Das größte Element findet man ähnlich, nur dass man nach rechts wandern muss.
Im schlimmsten Fall müssen wir den Baum von oben nach unten durchwandern, also ist die Laufzeitkomplexität dieselbe, wie die bei der Suche eines Elements, das heißt O(log(n)).
2.3 Durchwandern
Um die Elemente eines Baums in geordneter Reihenfolge zu durchwandern, beginnt man seine Suche beim Minimum und sucht dann immer das nächste größere Element, bis man beim Maximum angelangt ist.
Wie man zum nachfolgenden Knoten im Baum gelangt, hängt von der Position im Baum ab von der man startet. Genauer gesagt hängt es davon ab, ob der Ausgangsknoten ein rechtes Kind besitzt oder nicht.
2.3.1 Knoten mit rechtem Kind
Falls es einen rechten Unterbaum gibt, so ist das nächste Element das Minimum dieses Unterbaums.
In folgendem Beispiel suchen wir das Element, das der 5 folgt. Dazu begeben wir uns zuerst in den rechten Unterbaum und dann suchen wir das Minimum, indem wir solange nach links wandern wie nur möglich.
2.3.2 Knoten ohne rechtes Kind
Sollte es kein rechtes Kind geben, so muss man Richtung Wurzel des Baums klettern. Falls man unterwegs auf einen Knoten stößt, welchen man von seinem linken Kind aus erreicht hat, so hat man das nächste Element gefunden.
Der Algorithmus um den Baum vom Maximum zum Minimum zu durchwandern, ist genau spiegelverkehrt und darum werde ich nicht weiter auf ihn eingehen.
Beim D***urchwandern des gesamten Baums wird jede Kante genau zweimal begangen, wenn man das Bestimmen des Minimum***s und Maximum***s*** hinzuzählt. Da es nur einen Knoten mehr gibt als Kanten, hat das Durchwandern eine Laufzeitkomplexität von O(n). Um das nächste Element zu finden, muss man im schlimmsten Fall von der untersten Ebene bis zur Wurzel oder andersherum wandern. Diese Operation hat also eine Laufzeitkomplexität von O(log(n)) im ungünstigsten Fall, ist aber meisten***s*** wesentlich besser.
Es gibt einen alternativen Ansatz, der die Knoten noch zusätzlich zum Baum in einer geordneten verketteten Liste zusammenstrickt. Dies beschleunigt das Durchwandern um einen konstanten Faktor und sorgt dafür, dass das Bestimmen des nächsten Elements immer eine konstante Laufzeit besitzt. Der Preis ist allerdings der Mehraufwand, um die verkettete Liste zu verwalten. Falls man den Baum oft durchwandern muss, sollte man diese Option in Betracht ziehen.
2.4 Einfügen
Um einen Wert einzufügen, geht man ähnlich vor, wie bei der normalen Suche. Man wandert solange nach unten, bis man einen Knoten gefunden hat, der noch ein Kind, an der richtigen Seite, frei hat.
In folgendem Beispiel wird die 8 eingefügt.
Da es sich im ***W***esentlichen um den gleichen Algorithmus handelt wie bei der Suche, ist auch die Komplexität die gleiche und zwar O(log(n)).
2.5 Löschen
Als erstes sucht man den zu löschenden Knoten nach bekannter Methode. Wie man danach vorgeht, hängt von der Position des Knoten im Baum ab, das heißt wie viele Kinder der Knoten hat.
2.5.1 Löschen eines Knoten ohne Kinder
Um ein Blatt zu löschen trennt man es einfach vom Elternknoten ab.
Folgendes Beispiel zeigt wie die 5 aus dem Baum gelöscht wird:
2.5.2 Löschen eines Knoten mit einem Kind
Falls es es nur ein Kind gibt, so wandert dieses an den Platz des Knoten. Man trennt den zu löschenden Knoten von Kind- und Elternknoten und verbindet danach diese zwei.
Im nächsten Beispiel wird die 3 gelöscht.
2.5.3 Löschen eines Knoten mit zwei Kindern
Ein Knoten mit zwei Kinder***n*** lässt sich nicht einfach löschen. Was aber leicht gelöscht werden kann, ist das vorhergehende oder nachfolgende Element. Bei beiden handelt es sich nämlich um das Maximum respektiv***e*** das Minimum des linken beziehungsweise rechten Unterbaums. Aus diesem Grund haben sie höchstens ein Kind und können daher mit einem der beiden oben genannten Methoden gelöscht werden.
Ob man sich für das nachfolgende oder vorhergehende Element entscheidet, spielt keine große Rolle. Keine der beiden Optionen hat einen wirklichen Vorteil oder Nachteil.
In folgendem Beispiel wird die 7 gelöscht.
Manche Leser werden sich an diesem Punkt vielleicht fragen, ob es denn immer ein nachfolgendes und vorhergehendes Element gibt. Es könnte ja sein, dass man den Auftrag erhalten hat, das erste oder letzte Element zu löschen. Da es sich bei beiden allerdings um ein Minimum oder Maximum handelt, können sie keine zwei Kinder besitzen und daher ist ein Austauschen gar nicht erst nötig.
Die Geschwindigkeit der eigentlichen Löschverfahren sind alle unabhängig von der Größe des Baums. Lediglich die Suche des zu löschenden Elements und das Bestimmen des nachfolgenden oder vorhergehenden Elements hängen von der Größe ab, darum ist die Komplexität einer Löschoperation in etwa O(log(n)).
2.6 Ausbalancierte Bäume und die, die es nicht sind
Eines der großen Probleme solcher Bäume ist, dass wenn die Reihenfolge der Einfügungen ungünstig ist, der Baum sehr schnell aus dem Gleichgewicht kommt und zu einer Seite hinkt. Dies macht den Baum sehr viel höher als nötig und somit die Suche viel langsamer, da diese ja von der Höhe des Baums abhängt.
In folgendem Baum wird die 8 gesucht und der Arbeitsaufwand kommt schon nahe an den einer sequenziellen Suche heran.
Um dem entgegenzuwirken, kann man Rotationen einsetzen.
2.7 Rotationen
Es gibt Rotationen nach links und nach rechts. Da beide Operationen genau spiegelverkehrt sind, werde ich nur auf die ***Links-***Rotation eingehen.
Als erstes trennt man das linke Kind vom rechten Kind der Wurzel ab und ansch***l***ießend auch das rechte Kind.
Danach wird das rechte Kind zur neuen Wurzel und die alte Wurzel wird ihr neues rechtes Kind. Das Enkelkind wird zum neuen rechten Kind der alten Wurzel.
Nun ist der Baum wieder im Gleichgewicht.
Man sagt ***Links-***Rotation, da sich das Gleichgewicht nach links verlagert. Man kann es sich wie eine Balkenwaage vorstellen, welche man in das Gleichgewicht bringt, indem man den Balken an einer anderen Stelle aufhängt.
Das Beispiel hinkt aber, da nach der Rotation beide Gewichte gleich schwer sind.
Die Geschwindigkeit einer Rotation hängt nicht von der Größe des Baums ab. Die Komplexität ist also O(1).
Das große Problem von Rotationen ist zu wissen, wann man sie einsetzen soll. Sie verbessern nämlich nicht immer das Gleichgewicht eines Baums wie folgendes Beispiel zeigt.
Es gibt verschiedene Strategien, um hier vorzugehen. Keine ist allerdings wirklich trivial und verdienen alle ihren eigenen Artikel. Da alle aber Rotationen nutzen, hab***e*** ich sie bereits jetzt eingeführt, damit nicht jeder Artikel diese Operation neu beschreiben muss und direkt mit dem wirklich interessanten Teil beginnen kann. Ich werde in diesem Artikel nicht weiter auf ihre Verwendung eingehen.
3 Implementierung
Das erste, was man bei einer Implementierung festlegen muss, ist die Darstellung. Die Knoten werden durch eine Struktur dargestellt und dann mit Pointern verbunden. Dies sieht in etwa so aus:
template<class T> struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} };parent zeigt auf den Elternknoten. Falls es sich um die Wurzel handelt, ist dieser NULL. left und right zeigen jeweils auf die Wurzel des linken oder rechten Unterbaums oder NULL, falls es diesen nicht gibt.
Um zu verhindern, dass Unbefugte an unserem Baum rumbasteln wird dieser durch eine Klasse gekapselt. Dies sieht dann in etwa folgendermaßen aus:
template<class T> class Tree{ private: struct Node{ Node*parent, *left, *right; T value; explicit Node(const T&value): parent(0), left(0), right(0), value(value){} }; Node*root; public: Tree():root(0){} bool is_empty()const{ return !root; } };root zeigt dabei auf die Wurzel des Baumes oder NULL, falls der Baum leer ist. Ob der Baum leer ist, kann mittels is_empty überprüft werden.
Es gibt Variationen, in denen die Knoten keinen Zeiger auf den Elternknoten besitzen. Dies spart Speicher und erleichtert die Verwaltung der zusätzlichen Zeiger, jedoch macht es auch die Implementierung mancher Operationen, wie zum Beispiel des Durchwanderns, komplizierter. Oft sind diese nur noch durch den Einsatz eines Stacks oder Rekursion überhaupt möglich. Welche Option nun die beste ist, hängt vo***m*** Einsatzfall ab.
Manche Leser werden vielleicht auch auf den Gedanken gekommen sein, die Elemente in einem Array abzulegen und das Navigieren durch Multiplizieren der Indizes mit 2 abzuwickeln. Für manche Bäume ist dies sicherlich ein sinnvoll***er*** Ansatz, wie zum Beispiel bei Heaps, wie man in Jesters Artikel dazu nachlesen kann. Für Suchbäume ist dieser Ansatz aber unbrauchbar da Rotationen sich nur sehr schwer implementieren lassen und unausbalancierte Bäume in dieser Darstellung echte Speicherfresser sind.
3.1 Navigation
Um uns beim ***N***avigieren im Baum zu helfen, schreiben wir uns Funktionen, die prüfen, ob es sich um ein linkes oder rechtes Kind handelt.
private: static bool is_left_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->left == node; } static bool is_right_child(const Node*node){ if(node->parent == 0) return false; // Die Wurzel ist kein Kind else return node->parent->right == node; }Um die Position eines Knotens ändern zu können, muss man auch einen einfachen Zugriff auf den Zeiger im Elternknoten haben. Dies bietet folgende Funktion:
private: Node**get_parent_ptr(Node*node){ if(node->parent == 0) return &root; else if(is_left_child(node)) return &node->parent->left; else return &node->parent->right; }3.2 Debuggen
Da es sehr schwer ist, einen Baum fehlerfrei zu implementieren, müssen wir uns auch Gedanken machen, wie wir ihn debuggen. Wer sich nur für den eigentlichen Code interessiert kann diesen Teil des Artikels getrost überspringen.
3.2.1 Konsolenausgabe
Eine Funktion, die den Baum einfach komplett auf die Konsole ausgibt, wäre sehr nützlich da die meisten Debugger nicht sonderlich gut sind, um solche Datenstrukturen zu inspizieren, und nur Zeigersalat anzeigen.
Ziel ist es, den Baum ähnlich wie auf den Grafiken oben auszugeben. Dazu müssen wir als erstes festlegen, welche Informationen über einen Knoten ausgegeben werden. Dies macht folgende Funktion:
private: static std::string format_label(const Node*node){ if(node){ std::ostringstream out; out<<node->value; return out.str(); }else return ""; }Wir müssen auch wissen, wie breit und hoch der Baum wird, damit wir wissen wie viel Platz frei gelassen werden muss. Folgende Funktionen berechnen diese Informationen für den Baum und jeden Unterbaum.
private: static unsigned get_height(const Node*node){ if(!node) return 0; unsigned left_height = 0, right_height = 0; if(node->left) left_height = get_height(node->left); if(node->right) right_height = get_height(node->right); // Der höchste Unterbaum bestimmt die Gesamthöhe return std::max(left_height, right_height) + 1; } static unsigned get_width(const Node*node){ if(!node) return 0; unsigned left_width = 0, right_width = 0; if(node->left) left_width = get_width(node->left); if(node->right) right_width = get_width(node->right); return left_width + format_label(node).length() + right_width; }Da wir nur zeilenweise auf die Konsole schreiben können, müssen wir den Baum auch Zeile für Zeile ausgeben.
private: static void dump_spaces(std::ostream&out, unsigned count){ for(unsigned i=0; i<count; ++i) out.put(' '); } static void dump_line(std::ostream&out, const Node*node, unsigned line){ if(!node) return; if(line == 1){ // Die Wurzel des Unterbaums soll ausgegeben werden dump_spaces(out, get_width(node->left)); out<<format_label(node); dump_spaces(out, get_width(node->right)); }else{ // In beiden Unterbäumen sind die Wurzeln um eins niedriger und darum verändert // sich die Zeilennummerierung. dump_line(out, node->left, line-1); dump_spaces(out, format_label(node).length()); dump_line(out, node->right, line-1); } }Nun benötigen wir noch eine Möglichkeit, den gesamten Baum auszugeben und nicht nur eine Zeile.
private: static void dump_node(std::ostream&out, const Node*node){ for(unsigned line=1, height = get_height(node); line <= height; ++line){ dump_line(out, node, line); out.put('\n'); } out.flush(); } public: void dump(std::ostream&out)const{ dump_node(out, root); }Mit der Hilfe der dump-Funktion können wir nun den Baum für den Menschen lesbar anzeigen. Eine mögliche Ausgabe wäre:
6 3 10 1 5 7 12Man könnte den Ausgabealgorithmus sicher noch sehr viel verbessern, was die Geschwindigkeit betrifft. Ich glaube jedoch kaum, dass er bei großen Bäumen überhaupt zum Einsatz kommen wird und deshalb werde ich dies sein lassen.
3.2.2 Tod dem Zeigersalat
Bei dem Implementieren von Bäumen wird man oft Zeigern begegnen, die nicht dahin zeigen, wohin sie eigentlich sollten. Eine Funktion, die testet, ob der Baum so überhaupt richtig sein kann, hilft, viele Fehler zu finden. Man testet zum Beispiel ob der Elternknoten des Kindes eines Knoten dieser selbst ist.
private: bool is_wellformed(Node*node){ if(node == 0) return true; if(*get_parent_ptr(node) != node) return false; if(!is_wellformed(node->left)) return false; if(!is_wellformed(node->right)) return false; return true; }Mit Hilfe eines assert(is_wellformed(root)) können sehr viele Fehler vorzeitig abgefangen werden. Durch ein Paar geschickt gesetzte Breakpoints innerhalb dieser Funktion, kann man auch sehr genau erfahren, welcher Zeiger falsch ist.
3.3 Kopierkonstruktor, Destruktor und Zuweisung
Da ein Baum keine triviale Datenstruktur ist, muss man auch den Kopie***r***konstruktor, den Destruktor und den Zuweisungsoperator implementieren.
Als erstes implementiere ich den Destruktor. Dieser ist leicht rekursiv zu realisieren.
private: static void destroy_node(Node*node){ if(node){ destroy_node(node->left); destroy_node(node->right); delete node; } } public: ~Tree(){ destroy_node(root); }Bei sehr großen Bäumen kann es bei diesem Destruktor zu einem Stapelüberlauf kommen. In diesem Fall muss man ihn iterativ formulieren. Die Idee ist immer, das Blatt zu löschen, das den kleinsten Wert aller Blätter darstellt, sich also auf der linken Seite des Baums befindet. Durch das Abschneiden der ersten Blätter entstehen neue und der Baum schrumpft zusammen, bis er schlussendlich nicht mehr existiert.
~Tree(){ Node*now = root; while(now){ if(now->left) now = now->left; else if(now->right) now = now->right; else{ Node*next = now->parent; *get_parent_ptr(now) = 0; delete now; now = next; } } }Der Kopierkonstruktor kann auch rekursiv implementiert werden, man muss jedoch aufpassen, ob eine Ausnahme fliegt oder nicht. Dies wird schnell unübersichtlich und fehleranfällig. Darum bevorzuge ich die iterative Version. Die Idee ist, den alten und neuen Baum so zu durchlaufen, wie wir es im Destruktor tun und dabei alle Knoten klonen welche im alten Baum vorhanden sind, jedoch nicht im neuen.
Mit dieser Methode ist der Baum immer in einem gesunden Zustand und kann vom Destruktor auch im unvollendeten Zustand gelöscht werden. Falls eine Ausnahme fliegt, brauchen wir nur den Destruktor mit der Arbeit zu beauftragen, den halbfertigen Baum zu löschen.
Tree(const Tree&other){ if(other.is_empty()) root = 0; else{ root = new Node(other.root->value); try{ Node *now = root, *other_now = other.root; while(other_now){ if(other_now->left && !now->left){ now->left = new Node(other_now->left->value); now->left->parent = now; now = now->left; other_now = other_now->left; }else if(other_now->right && !now->right){ now->right = new Node(other_now->right->value); now->right->parent = now; now = now->right; other_now = other_now->right; }else{ now = now->parent; other_now = other_now->parent; } is_wellformed(root); } }catch(...){ this->~Tree(); throw; } } }Der Zuweisungs-Operator kann leicht mit Hilfe des Copy&Swap-Idioms implementiert werden.
public: void swap(Tree&other){ std::swap(root, other.root); } Tree&operator=(const Tree&other){ Tree temp(other); swap(temp); return *this; }3.4 Suchen
Implementieren wir nun die Suchfunktion. Da wir die innere Struktur der Klasse verstecken wollen, stellen wir dem Außenstehenden nur eine Funktion zur Verfügung, die testet, ob ein Wert im Baum enthalten ist.
Man sollte bemerken, dass man es dem Benutzer nicht erlauben sollte, den Wert des Knotens zu veränder***n***, da dies die Position im Baum durcheinander bringen kann. Falls er dies beabsichtig, dann soll er den alten Wert rauslöschen und den neuen einfügen, damit sich das Element an der richtigen Stelle befindet.
Durch den Einsatz von Templates spare ich mir, eine const- und eine nicht-const-Version zu schreiben.
private: template<class NodeT> static NodeT*search(NodeT*root, const T&value){ NodeT*now = root; while(now){ if(value < now->value) now = now->left; else if(now->value < value) now = now->right; else return now; } return 0; } public: bool contains(const T&t)const{ return search(root, t); }3.5 Einfügen
Um ein Element einzufügen, verfahren wir ähnlich, jedoch merken wir uns, wo sich der Elternknoten befindet.
public: bool insert(const T&value){ Node *parent = 0, *now = root; bool is_left_child = false; while(now){ parent = now; if(value < now->value){ is_left_child = true; now = now->left; }else if(now->value < value){ is_left_child = false; now = now->right; }else return false; // Das Element ist bereits im Baum } Node*new_node = new Node(value); new_node->parent = parent; if(parent == 0) root = new_node; else if(is_left_child) parent->left = new_node; else parent->right = new_node; // Wenn etwas mit den Zeigern falsch ist, // dann knallt es wahrscheinlich hier. assert(is_wellformed(root)); return true; }3.6 Austauschen
Knoten können durch ***A***ustauschen der Werte getauscht werden. Dies ist sicherlich der beste Weg, falls man Ganzzahlen speichern will. Es gibt jedoch auch Klassen, welche sehr teuer zu tauschen sind oder die gar nicht getauscht werden können. Es ist auch möglich, dass es Zeiger auf das Element gibt, die außerhalb des Baums liegen und verändert werden müssten, oder dass beim Tauschen eine Ausnahme fliegen kann. Diese Probleme kann man dadurch umgehen, dass man die Zeiger der Knoten neuverbindet. Hierbei ist der allgemeine Fall vom Fall, wo einer der beiden Knoten das Kind des anderen ist, zu unterscheiden.
Man sollte beachten, dass das Tauschen von Knoten wahrscheinlich die Ordnung im Baum durcheinander bringt. Es sollte also sicher gestellt sein, dass diese nachdem diese Funktion ihre Arbeit getan hat, wiederhergestellt wird.
private: void swap_near_nodes(Node*child, Node*parent){ // Als erstes passen wir den unbeteiligten Großelternknoten an. *get_parent_ptr(parent) = child; // Anschließend werden die Kind- und Elternzeiger ausgetauscht. std::swap(parent->left, child->left); std::swap(parent->right, child->right); std::swap(parent->parent, child->parent); // Da eines der Kinder getauscht wird benötigt es eine // sonder Behandlung. if(child->left == child) child->left = parent; else child->right = parent; // Nun sind alle Kindzeiger richtig und die Elternzeiger können // dem angepasst werden. if(child->left) child->left->parent = child; if(child->right) child->right->parent = child; if(parent->left) parent->left->parent = parent; if(parent->right) parent->right->parent = parent; // Na wer ist sich noch sicher ob wir nicht // bereits Zeigersalat haben? Besser testen! assert(is_wellformed(root)); } void swap_far_nodes(Node*a, Node*b){ // Zuerst updaten wir die Zeiger der Eltern *get_parent_ptr(a) = b; *get_parent_ptr(b) = a; // Danach der Kinder if(a->left) a->left->parent = b; if(a->right) a->right->parent = b; if(b->left) b->left->parent = a; if(b->right) b->right->parent = a; // Und als letztes die der beiden Knoten std::swap(a->left, b->left); std::swap(a->right, b->right); std::swap(a->parent, b->parent); assert(is_wellformed(root)); } void swap_nodes(Node*a, Node*b){ if(a->parent == b) swap_near_nodes(a, b); else if(b->parent == a) swap_near_nodes(b, a); else swap_far_nodes(a, b); }3.7 Minimum und Maximum
Das Minimum eines Unterbaums findet man, indem man einfach den Links-Zeigern folgt bis man an einem Knoten ohne linken Unterbaum angelangt ist. Ähnlich geht man beim Maximum vor.
private: template<class NodeT> static NodeT*get_min(NodeT*node){ NodeT*now = node; while(now->left) now = now->left; return now; } template<class NodeT> static NodeT*get_max(NodeT*node){ NodeT*now = node; while(now->right) now = now->right; return now; } public: const T&min()const{ return get_min(root)->value; } const T&max()const{ return get_max(root)->value; }3.8 Durchwandern
Um dem Benutzer die Möglichkeit zu geben, den Baum zu durchwandern, bietet sich der Einsatz von Iteratoren förmlich an. Da ich mich in diesem Artikel allerdings auf die Implementierung des Baum beschränken möchte und nicht eine Schnelleinführung zum Thema Iteratoren geben möchte, werde ich nur eine Funktion implementieren die den nächst größeren Wert sucht. next nimmt einen Wert als Parameter und gibt einen Zeiger auf das nächste Element zurück oder ein NULL Zeiger falls der Parameter das Maximum war oder ein Wert, der sich gar nicht im Baum befindet. prev ist eine ähnliche Funktion die jedoch das nächstkleinere Element sucht.
private: template<class NodeT> static NodeT*get_next_node(NodeT*now){ if(now->right) return get_min(now->right); else{ while(now){ if(is_left_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Ende angekommen } } template<class NodeT> static NodeT*get_prev_node(NodeT*now){ if(now->left) return get_max(now->left); else{ while(now){ if(is_right_child(now)) return now->parent; else now = now->parent; } return 0; // Wir sind am Anfang angekommen } } public: const T*next(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_next_node(now); if(now) return &now->value; else return 0; } const T*prev(const T&value)const{ const Node*now = search(root, value); if(!now) return 0; now = get_prev_node(now); if(now) return &now->value; else return 0; }3.9 Löschen
Das Löschverfahren von Knoten wurde tiefgehend in der Theorie behandelt und darum gibt es nicht viel zur Implementirung zu sagen.
private: void remove(Node*node){ // Ein Blatt if(!node->left && !node->right){ *get_parent_ptr(node) = 0; delete node; } // Nur ein Kind else if(node->left && !node->right){ *get_parent_ptr(node) = node->left; node->left->parent = node->parent; delete node; }else if(!node->left && node->right){ *get_parent_ptr(node) = node->right; node->right->parent = node->parent; delete node; } // Zwei Kinder else{ Node*other = get_prev_node(node); swap_nodes(node, other); // Löschen des Knoten durch Benutzen von einer // der beiden anderen Methoden remove(node); } assert(is_wellformed(root)); } public: bool remove(const T&value){ Node*node = search(root, value); if(node){ remove(node); return true; }else return false; }3.10 Rotationen
Rotationen können sehr viel Stress verursachen, bevor sämtliche Zeiger richtig gestellt werden. Darum ist es sehr nützlich, den Baum zuerst zu zeichnen: wie er vorher aussieht und danach.
Die Rotationsfunktionen geben einen Zeiger auf die neue Wurzel zurück.
private: Node*rotate_left(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->right, *X = A->left, *Y = B->left, *Z = B->right; *root_ptr = B; B->left = A; B->right = Z; A->left = X; A->right = Y; B->parent = parent; A->parent = B; if(Z) Z->parent = B; if(X) X->parent = A; if(Y) Y->parent = A; return B; } private: Node*rotate_right(Node*A){ Node **root_ptr = get_parent_ptr(A), *parent = A->parent, *B = A->left, *X = B->left, *Y = B->right, *Z = A->right; *root_ptr = B; B->left = X; B->right = A; A->left = Y; A->right = Z; B->parent = parent; A->parent = B; if(Z) Z->parent = A; if(X) X->parent = B; if(Y) Y->parent = A; return B; }3.11 Tunen von new und delete
Bäume spielen ihren Vorteil gegenüber alternativen Datenstrukturen vor allem aus, wenn es viele Elemente gibt, doch auch bei kleinen Listen sind sie nicht hoffnungslos ***u***nterlegen. Wenn es nur sehr wenige Elemente gibt, dann wird nichts in der Liga einfacher Arrays spielen können, jedoch gilt es so nahe wie möglich ran zu kommen. Bei kleinen Bäumen fällt die Zeit, die durch die Speicherverwaltung, das heißt direkt in new und delete, verbracht wird, viel mehr ins Gewicht und darum bietet es sich an, hier was zu tun. Da sämtliche Knoten die gleiche Größe haben, kann der Einsatz von Memory Pools Wunder wirken. Bei großen Bäumen ist ihr Einsatz sicherlich nicht verkehrt, auch wenn der Gewinn proportional gesehen kleiner ausfallen wird. Zum Nachteil wird der Einsatz von Pools eigentlich so gut wie nie.
3.12 Download und Experimentierkonsole
Die Implementierung gibt es auch fertig in einer Datei verpackt, um das Herumexperimentieren zu erleichtern. Neben dem eigentlichen Baum ist auch eine Konsole enthalten, mit deren Hilfe man die einzelnen Funktionen in Aktion sehen kann. Alles was zum Übersetzen benötigt wird ist ein standardkonformer Compiler.
4 Bäume in der STL
Die Spezifikation der STL gibt wie immer keine Implementierung vor, allerdings ist es sehr wahrscheinlich, dass hinter std::set und std::map Bäume am Werk sind.
Wie der Baum eingesetzt wird, um std::set umzusetzen, sollte eigentlich nach dem Lesen dieses Artikels klar sein, da es doch gewaltige Ähnlichkeiten zwischen der hier entwickelten Baumklasse und std::set gibt. Bei std::map könnte es weniger deutlich sein. Hier weist man jedem Knoten einen Schlüssel und den entsprechenden Wert zu und sortiert den Baum dem Schlüssel entsprechend. Ein Suchen nach dem Schlüssel liefert also auch den Knoten in dem der entsprechende Wert gespeichert ist.
5 Ausblick
In diesem Artikel habe ich gezeigt wie Suchbäume aufgebaut sind und wie sie funktionieren, jedoch auch ihre Schwächen. Der Suchbaum, so wie er in diesem Artikel beschrieben wird, ist recht nutzlos weil er sehr einfach aus dem Gleichgewicht kommt. Um dagegen vorzugehen gibt es verschiedene Ansätze: AVL-Baum, Rot-Schwarz-Baum oder Splay-Baum um nur einige zu nennen. Alle haben ihre Stärken und Schwächen. In den nächsten Artikeln wird der hier vorgestellte Baum zu diesen Spezialbäumen umgebaut und die Rotationsfunktionen, die jetzt noch etwas in der Luft hängen, werden ihren Teil dazu beitragen.
-
Hi Ben04,
ich bin jetzt mit der Korrektur des Artikels fertig.
Ich habe noch ein paar Anmerkungen:
Der Titel lautet ja "AVL Baum", aber im Ausblick schreibst du, dass du den vorgestellten Baum erst noch u.a. in einen AVL-Baum umbauen willst. Wie passt das zusammen?In Abschnitt 2.7 ("Rotationen") schreibst du:
Danach wird das rechte Kind zur neuen Wurzel und die alte Wurzel wird ihr neues rechtes Kind. Das Enkelkind wird zum neuen rechten Kind der alten Wurzel.
Sollte die alte Wurzel nicht ihr neues linkes Kind werden, so wie es auch in deinem Bild zu sehen ist?
Und schließlich noch in Abschnitt 3 ("Implementierung"): willst du dort nicht auch einen Link auf Jesters Artikel setzen?
Die Kommentare im Download-Quelltext werde ich gleich noch korrigieren, und lade ihn dann als "search_tree_kor.cpp" hoch.
Btw, die Experimentier-Konsole ist wirklich cool!
-
Der Titel lautet ja "AVL Baum", aber im Ausblick schreibst du, dass du den vorgestellten Baum erst noch u.a. in einen AVL-Baum umbauen willst. Wie passt das zusammen?
In der ersten Version war der AVL Baum auch noch drin (siehe erstes Post im Thread). Danach hab ich ihn aber raus genommen da das zuviel gewesen wäre. Der Teil kommt dann nächsten Monat. "Binärer Suchbaum" ist ein Titel der besser zum Artikel passt.
Danach wird das rechte Kind zur neuen Wurzel und die alte Wurzel wird ihr neues rechtes Kind. Das Enkelkind wird zum neuen rechten Kind der alten Wurzel.
Sollte die alte Wurzel nicht ihr neues linkes Kind werden, so wie es auch in deinem Bild zu sehen ist?
In der Tat. Die alte Wurzel wird zum linken Kind.
Und schließlich noch in Abschnitt 3 ("Implementierung"): willst du dort nicht auch einen Link auf Jesters Artikel setzen?
Mach ich.
Die Kommentare im Download-Quelltext werde ich gleich noch korrigieren, und lade ihn dann als "search_tree_kor.cpp" hoch.
Das Kodieren der Umlaute hat nicht geklappt. Hab es ausgebessert. (Ist der Hauptgrund warum die eigentliche Konsole in Englisch ist.)
Btw, die Experimentier-Konsole ist wirklich cool!
Danke
-
Dies sollte die letzte Version sein. Wie geht es jetzt weiter? Einfach auf [T] setzten?
Soll ich für den AVL Baum einen neuen Thread machen oder wird der Artikel-Post einfach rausgesplittet?
-
Ben04 schrieb:
Dies sollte die letzte Version sein. Wie geht es jetzt weiter? Einfach auf [T] setzten?
[T] kommt vor [R], nach [R] kommt nur noch [E] (also "bin fertig").
Soll ich für den AVL Baum einen neuen Thread machen oder wird der Artikel-Post einfach rausgesplittet?
Ja, mach bitte einen neuen Thread, das wird sonst unübersichtlich.
Ich splitte die letzte Version deines Artikels aus diesem Thread raus und sobald die veröffentlicht ist, kommt dieser Thread ins Archiv.
-
Hallo Ben!
Ich habe den Artikel eben herausgesplittet und mir ist aufgefallen, dass du noch kein Profil hast.
Hol das doch bitte noch schnell nach.
-
Dieser Thread wurde von Moderator/in estartu aus dem Forum Die Redaktion in das Forum Archiv verschoben.
Im Zweifelsfall bitte auch folgende Hinweise beachten:
C/C++ Forum :: FAQ - Sonstiges :: Wohin mit meiner Frage?Dieses Posting wurde automatisch erzeugt.