Sourcecode Fortschritt
-
Erste Tests:
strg+s (screenshot auf floppy) und strg+u (screenshot auf usb-stick) gehen noch gleich schnell, Schreibvorgänge sind im FAT-Modul bereits gecacht.

ttt.elf laden:
a1) Floppy real: wird jedes byte einzeln per sector lesen geladen (lese-cache notwendig), real abgebrochen zum Schutz des FDD
a2) Floppy Qemu: geht (etwas langsamer ^^)
b1) USB-Stick real: #PF (schreiben in read-only area ??), entweder bug eingebaut oder technik geht so nicht (MrX: bitte prüfen und kommentieren)
b2) USB-Stick VMWare-Player: wird jedes byte einzeln per sector lesen geladen (lese-cache notwendig), interessanter Dauertest für OS und Stick (auch nett: Stick ziehen, dauer-rot auf screen ^^)
Ein interessanter Trümmerhaufen, aus dem Phoenix aus der Asche wieder erstehen soll.
")
Die Grundfrage ist die, ob nach erfolgreichem Read-Cache-Einbau die Performance nicht doch leidet durch die vielen zusätzlichen Abläufe zwischen dem Lesen der Bytes mit fgetc.

-
0.0.1.19 (SVN Rev. 580)
Read Cache für readSector funktioniert wie gewünscht.
")
Leider existiert ein Problem beim Laden von usb-stick (Ursache noch nicht untersucht)
-
0.0.1.20 (Rev. 581)
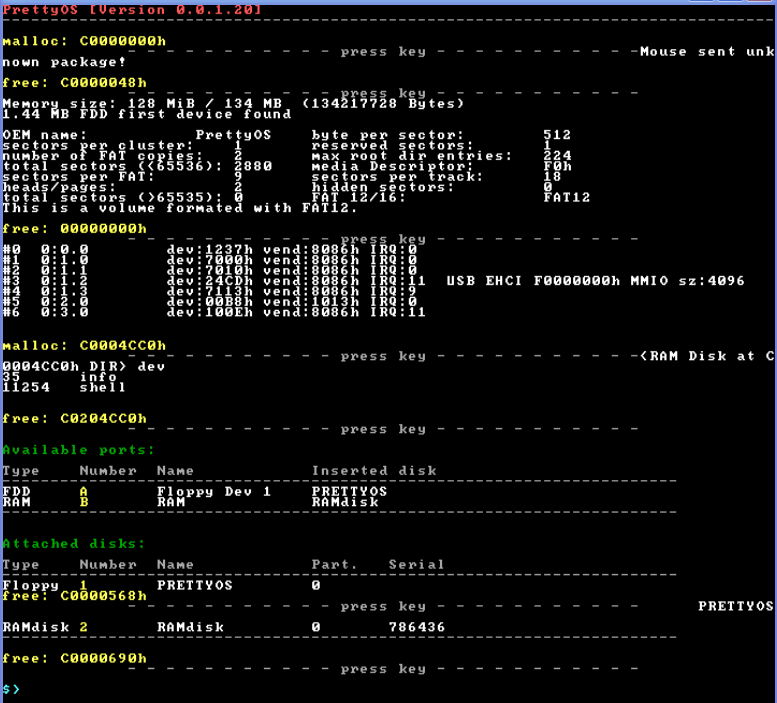
 Problem: malloc spinnt! (seit 0.0.1.18) keiner weiß warum ^^
Problem: malloc spinnt! (seit 0.0.1.18) keiner weiß warum ^^Es passiert, wenn ein programm einmal geladen wird (muss nicht ausgeführt werden)
file->name von pointer auf array umgestellt, wegen Analogie zu FAT_file->name (dort exakt 8+3), hilft aber nicht beim aktuellen Problem, sollte aber ansonsten fehlersicherer sein, da man dabei nicht vergessen kann malloc(...) auszuführen.
-
malloc/free beginnend vom Start verfolgt:
void* malloc(uint32_t size, uint32_t alignment) { //... // debug textColor(0x0E); printf("\nmalloc: %X",address); textColor(0x0F); waitForKeyStroke(); return address; } void free(void* address) { // debug textColor(0x0E); printf("\nfree: %X",address); textColor(0x0F); waitForKeyStroke(); //... }Fazit: Da passt nix zusammen!

Beweis-Foto: http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_20_malloc_free_problem.PNG
malloc free -------------------------------------- C0000000 C0000048 00000000 C0004CC0 C0204CC0 C0000568 C0000690 C0000038usw.
Absoluter Nonsens zur Zeit.
-
Version 0.0.1.21
- malloc auf Placement umgestellt (HACK), free auskommentiert (HACK)
-> PrettyOS funktioniert wieder, Fehler in malloc
- Memory-Leak in executeFile behoben (durch HACK von oben wirkungslos) und unsinnigen Code dort weggemacht
- Ehenkes Umbau von file_t::name auf statisches Array zurückgebaut
-
PrettyOS funktioniert wieder
stimmt leider nicht!
Ich werde versuchen, die Ursachen zu finden und zu korrigieren. Bitte keine Änderungen vornehmen, bis ich das Committen wieder frei gebe. Hinweise auf den konkreten Haupt-Fehler sind natürlich gerne gesehen.
-
Rev. 583: 0.0.1.22
zwischenstand: log in malloc zum aufspüren von fehlern
heap expansion evtl. nicht ok
-
Rev. 584 (0.0.1.24)
Zwischenstand zur Fehlersuche beim Expandieren des Heaps
Committen wieder frei gegeben
Fragen:
- Wo liegt der Fehler im MM (Heap)?
- Warum löst 1:\... das aus?
-
Rev. 585 (0.0.1.25)
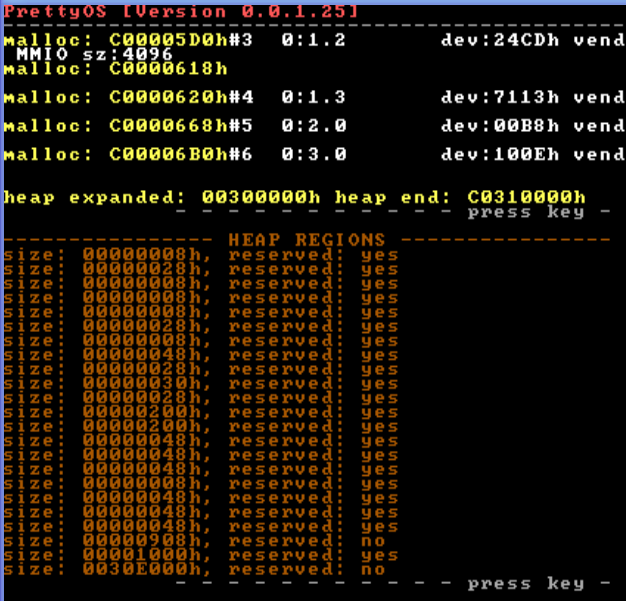
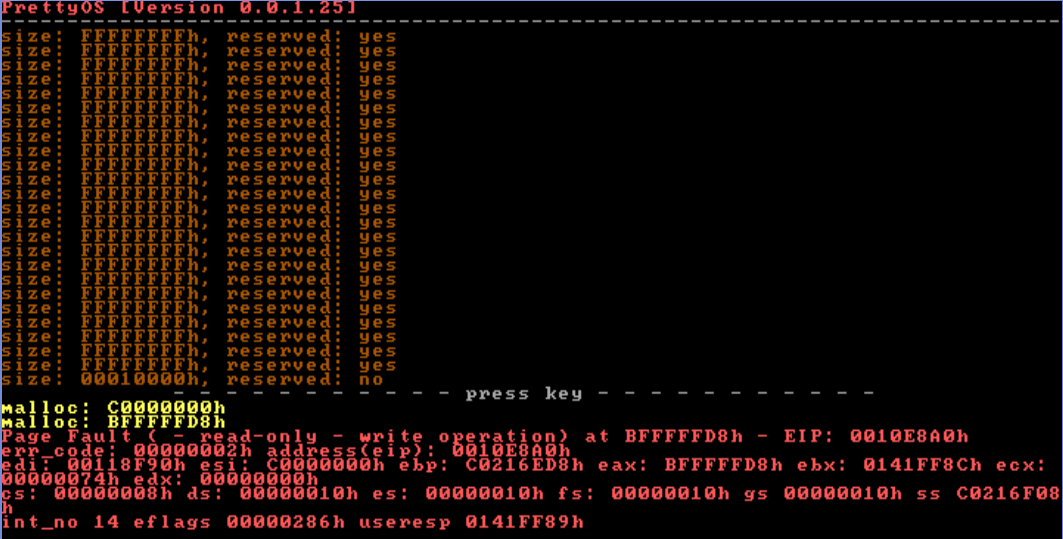
Zwischenstand Heap-Erweiterungs-Problematik:
Heap-Logger zur Analyse zeigt die Arbeitsweise des Heaps.http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_25_heap_problem.PNG <--- OK ?
http://www.henkessoft.de/OS_Dev/Bilder/0_0_1_25_heap_problem_PF.PNG <--- not OK
-
Rev. 586 (0.0.1.26):
HEAP_MIN_GROWTH = 0x40000;
#define PLACEMENT_BEGIN ((uint8_t*)0x1200000) // 18 MiB (vorher 16 MiB)
(Tobiking meint, das die Veränderung der Liste von außen erfolgen könnte, daher Tests mit 16/17/18/19 MiB als Placement-Untergrenze. Hatte hohen Einfluss.)
bei mir unter qemu bei 1:\... oder 1:|... Division by zero mit eip 0x104504 (kernel.map: 0x00105499 _FAT_fread)
Die Fehlersuche ist bisher über das Eingrenzen der Symptome nicht hinaus gewachsen.
-
Rev. 587 (0.0.1.27)
Heap-Problem erstmal gelöst: Regions Liste für Heap von 0xA00000 bis 0xE00000 gelegt. Da "unten" scheint es sicherer zu sein als zwischen 16 MiB und 20 MiB.
Tobiking hat da auch schon negative Erfahrungen bei VBox gemacht, er sprach von tasking_install.jetzt geht real und auf qemu auch wieder 3:/ttt usw.
#define _MALLOC_FREE_ sorgt für infos über malloc/free und zeigt den neuen Heap-Logger, der die "Regions", die Bausteine des Heaps, aufführt.
Wer das MM-Problem weiter bearbeiten will:
kheap.c:static const uint32_t HEAP_MIN_GROWTH = 0x40000;kheap.h:
// Placement allocation #define PLACEMENT_BEGIN ((uint8_t*) 0xA00000) // 10 MiB // TEST vorher 16 MiB #define PLACEMENT_END ((uint8_t*) 0xE00000) // 14 MiB // TEST vorher 20 MiBVorschlag aus IRC #lost von bluecode: magic einbauen und bei jedem malloc/free überprüfen, dann würden wir heap corruption zeitnah feststellen.
placement: A00000h
regions: B2A000hDa liegt Folgendes vor dem Heap:
kernel_pd = malloc(sizeof(page_directory_t), PAGESIZE); kernel_pd->tables[i] = malloc(sizeof(page_table_t), PAGESIZE); // Setup the page tables for the kernel heap (3GB-4GB), unmapped page_table_t* heap_pts = malloc(256*sizeof(page_table_t), PAGESIZE); bittable = malloc(128*1024, 0);In paging.c wurde auch folgendes geändert in phys_init():
// Check that 10 MiB-20 MiB is free for use if (!memorymap_availability(entries, 10*1024*1024, 20*1024*1024)) { textColor(0x0C); printf("The memory between 10 MiB and 20 MiB is not free for use. OS halted!\n"); for (;;); }Also bleiben für die regions-Verwaltung des Heap momentan:
E00000h - B2A000h = 2D6000h = 2973696 Bytetypedef struct { uint32_t size; bool reserved; } region_t;Größe: 4+1 Byte = 5 Byte
Anzahl regions: 2973696 Byte / 5 Byte = 594739
Heap-Area FF000000h - C0000000h = 1056964608 Byte
1056964608 Byte / 594739 regions = 1777 Byte/region (passt, wackelt und hat Luft
)
-
Rev. 588:
* Keysound.elf als Userprogramm hinzugefügt, macht immer Beep wenn man eine Taste drückt (A-Z)
-
0.0.1.28 - Rev: 589
- stack im BL 2 nach 0x99999 (korrekt: 0x9FFFF, s.u.), da kernel jetzt bei 0x100000
- kheap, paging (alles auf 10 MiB bis 20 MiB umgebaut)VBox und VMWare beklagen sich bei eingeschaltetem _MALLOC_FREE_, laufen aber ohne gut.
Real PC und qemu laufen mit und ohne.
-
Erhard Henkes schrieb:
Rev. 589: (0.0.1.28)
- stack im BL 2 nach 0x99999, da kernel jetzt bei 0x100000
Euch ist schon klar, dass Zahlen, die mit 0x anfangen, Hexzahlen sind und 0x99999 und 0x100000 damit keine direkt aufeinanderfolgenden Zahlen sind?
Immerhin habt ihr damit versehentlich was richtig gemacht, denn damit kommt ihr schonmal dem BIOS nicht in die Quere, das in dem Bereich dazwischen liegt. 0x99999 ist trotzdem eine seltsame Adresse für den Stack (und eine schlechte noch dazu, wegen Alignment).
-
sorry, war 0x9FFFF

Wäre das korrekter? Läuft aber auch anders.
mov ax,0xA000 mov ss,ax ; stack xor sp,sp ; stackpointer: A0000hSo sieht BL2 am Anfang zur Zeit aus:
;boot2.asm [map symbols boot2.map] [Bits 16] org 0x500 jmp entry_point ; go to entry point ;******************************************************* ; Includes and Defines ;******************************************************* %include "gdt.inc" ; GDT definition %include "A20.inc" ; A20 gate enabling %include "Fat12.inc" ; FAT12 driver %include "GetMemoryMap.inc" ; INT 0x15, eax = 0xE820 %define IMAGE_PMODE_BASE 0x100000 ; where the kernel is to be loaded to in protected mode %define IMAGE_RMODE_BASE 0x3000 ; where the kernel is to be loaded to in real mode ImageName db "KERNEL BIN" ImageSize dd 0 ;******************************************************* ; Data Section ;******************************************************* msgLoading db 0x0D, 0x0A, "Jumping to OS Kernel...", 0 msgFailure db 0x0D, 0x0A, "Missing KERNEL.BIN", 0x0D, 0x0A, 0x0A, 0 entry_point: cli xor ax, ax ; null segments mov ds, ax mov es, ax ;=====================================================HOTFIX===ehenkes==== mov ax,0x9000 mov ss,ax ; stack xor sp,sp dec sp ; stackpointer: 9FFFFh ;=====================================================HOTFIX===ehenkes==== sti A20: call EnableA20
-
Erhard Henkes schrieb:
sorry, war 0x9FFFF
Okay. Ich hätte eher 0x9fc00 genommen, sonst macht ihr euch womöglich die EBDA kaputt. Solange ihr die nicht braucht, ist es aber eigentlich auch egal.
Wäre das korrekter? Läuft aber auch anders.
mov ax,0xA000 mov ss,ax ; stack xor sp,sp ; stackpointer: A0000hIst besser, weil das Alignment dann stimmt. Für die Korrektheit sollte das keine Rolle spielen, aber für Performance könnte es einen Unterschied machen. Nicht, dass das in einem Bootloader entscheidend wäre, aber solche Fehler macht man ja ganz gern konsequent überall...
Edit: Nein, in Wirklichkeit ist es vollkomener Blödsinn. Als allererstes kriegt ihr einen Overflow in sp und schreibt dann den Videospeicher voll.
-
Ich hätte eher 0x9fc00 genommen
mov ax,0x9000 mov ss,ax ; stack mov sp,0xfc00 ; stackpointer: 9FC00hSo besser? Läuft auch.
Hauptsache der Kernel überfährt beim Laden ab 0x3000 im RM den Stack nicht.
-
Für Interessierte:
http://wiki.osdev.org/Memory_Map_(x86)#Extended_BIOS_Data_Area_.28EBDA.29
http://web.archive.org/web/20060508100419/http://heim.ifi.uio.no/~stanisls/helppc/ebda.html
-
0.0.1.29 - Rev: 590
- printf mit task_switching eingerahmt, um VBox und VMWare mit malloc/free/heap-Diagnose laufen zu lassen
- Stack im BL2 noch etwas angepasst
-
Version 0.0.1.30 - Rev: 591:
- Revision wird jetzt angegeben.
- synchronisation.c/.h hinzugefügt, enthält Code für semaphores (noch fehlerhaft)
-> zum testen: console.c z. 211 und 267 reinnehmen
- getCurrentMilliseconds im Userspace ergänzt, entsprechende Funktionen im Kernel ergänzt und umbenannt
- Kleinigkeiten
{kind=link}
{kind=link}
{kind=link}